作者:武卓、楊亦誠、Adrian Boguszewski、Anisha Udayakumar、Yiwei Lee、Stephanie Maluso、Raymond Lo、Ryan Loney、Ansley Dunn、Wanglei Shen
OpenVINO 五週年紀念日即將來臨的此刻,我們想花點時間對您在過去五年中對OpenVINO的持續使用表示最深的感謝。到目前為止,這是一段不可思議的旅程,我們很自豪您能成為我們社群中的一員,來自社群的持續支持讓我們的下載量超過了100萬次。
在紀念這個重要的里程碑之際,我們很興奮地宣佈OpenVINO最新版本──OpenVINO 2023.0問世!它具有一系列新的特性和功能,能讓開發者更輕鬆地部署和加速人工智慧(AI)。
2023.0版本的重點是透過最大限度減少離線轉換、擴大模型支援和推進硬體最佳化來改善開發者之旅。完整的版本說明可點此連結查看,重點如下:
- 儘量減少AI開發者在採用和維護程式碼時所需的修改,並與各種深度學習框架保持更好的一致性。
- 全新的TensorFlow體驗:簡化從訓練到部署TensorFlow模型的工作流程。
- 可以用Conda Forge!對於習慣使用Conda的C++開發者來說,更容易安裝OpenVINO Runtime。
- 更廣泛的處理器支援:對Arm處理器的支援現在包含在OpenVINO CPU推論運算中,涵蓋動態形狀(dynamic shapes)、完整的處理器性能和廣泛的程式碼範例/Notebook教程
- 擴展對Python的支援:增加了對Python 3.11的支援,以獲得更多潛在的性能改善。
- 在包括NLP在內的更多模型上輕鬆實現最佳化和部署,並藉由新的硬體功能獲得更多的AI加速。
- 更廣泛的模型支援:支援生成式AI模型、文本處理模型、Transformer模型等。
- 支援GPU的動態形狀:使用GPU時,不需要將模型改為靜態形狀,這在編寫程式碼時提供了更多的靈活性,特別是NLP模型。
- NNCF是首選量化工具:將訓練後量化(POT)整合到神經網路壓縮框架(Neural Network Compression Framework,NNCF)中,有了它,透過模型壓縮,更容易取得大幅度的性能提升。
- 透過自動裝置搜尋(automatic device discovery)、負載平衡,以及跨CPU、GPU等的動態推論平行,可以直接看到性能的提升。
- CPU外掛程式中的執行緒調度:藉由在Intel第12代酷睿(CORE)及以上版本的CPU的效率核心(E-cores)、性能核心(P-cores)或兩者一起執行推論來最佳化性能或功耗。
- 預設推論精度:預設為不同的格式,以在CPU和GPU上提供最佳性能。
- 模型快取擴展:減少GPU和CPU的首次推論延遲。
探索OpenVINO 2023.0新功能
現在,讓我們對上面介紹的一些新功能進行深入研究。
全新的TensorFlow體驗
現在,TensorFlow開發人員可以更容易地從模型訓練轉移到模型部署,無需離線將TensorFlow或TensorFlow Lite格式的模型檔轉換為OpenVINO IR格式──這會在執行時自動轉換。現在,您可以開始試驗Model Optimizer,以改善有限範圍模型的轉換時間,或者直接在OpenVINO Runtime或OpenVINO Model Server中載入標準TensorFlow/TensorFlow Lite模型。
下圖顯示了一個簡單的範例:

圖1:部署TensorFlow/TensorFlow Lite模型的通用工作流程
AI開發者可以找到更多對生成式AI模型的更多支援,例如 、BLIP、Stable Diffusion 2.0、 具備ControlNet的Stable diffusion ,以及對文本處理模型的支援、對Transformer模型的支援,例如S-BERT、GPT-J等,還有對Detectron2、Paddle Slim、Segment Anything Model (SAM) 、YOLOv8 、RNN-T等模型的支援。

圖2:由stable-diffusion-2-inpainting模型生成的無限變焦視訊效果。

圖3:基於兩個條件生成的影像,用OpenPose從輸入影像提取關鍵點的ControlNet工作流程,然後作為額外條件與文字提示詞一起導入Stable Diffusion模型。

圖4:用Segment Anything Model (SAM)模型分割既定圖片的一切。
預設推論精度
最新的更新包括在各種裝置上的推論性能的顯著提高,這些裝置現在預設以高性能模式運行。這意味著對於GPU裝置,使用FP16推論,而CPU裝置使用BF16推論(如果可用)。以前,使用者必須自己將IR轉換為FP16,才能使GPU在FP16模式下執行。現在,所有裝置都可以自動選擇預設推論精度,此選擇與IR精度沒有關係。在高性能模式可能影響推論精度的極少數情況下,使用者也可以調整推論精度提示。
此外,開發者可以單獨控制IR精度。預設情況下,我們建議將其設置為FP16,以便為浮點模型減少2倍的模型大小。值得注意的是,IR精度並不影響裝置執行模型的方式,而是透過降低權重精度來壓縮模型。

圖5:自動轉換IR模型為預設推論精度。
選用NNCF作為量化工具
NNCF為OpenVINO中的神經網路推論最佳化提供了一套先進的演算法,精度下降最小,被設計為能搭配來自PyTorch、TensorFlow、ONNX與 OpenVINO的模型。
在此之前,OpenVINO有單獨的工具用於訓練後最佳化(post training optimization,POT)和量化感知訓練。我們將這兩種方法合併到NNCF中,其中提供的壓縮演算法如圖5所示。這有助於減少模型大小、記憶體佔用面積和延遲,並提高運算效率。
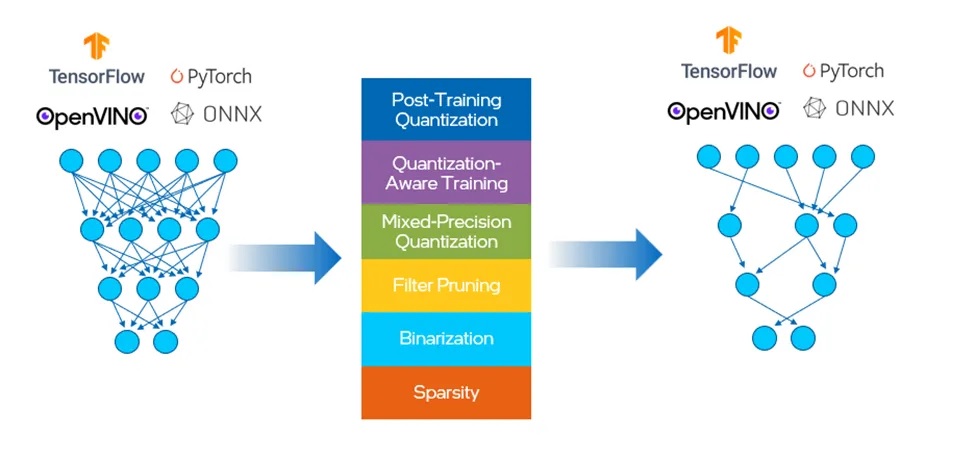
圖6:NNCF提供的壓縮算演算法。
訓練後量化演算法從代表性資料集中擷取樣本,並將其饋入網路中,然後根據所得的權重和啟動值(activation values)對網路進行校準。一旦校準完成,網路中的值就被轉換為8位元整數格式。NNCF的基本訓練後量化流程,是將8位元量化應用於模型的最簡單方法:
- 設定環境並安裝依賴項
pip install nncf
- 準備校準資料集
import nncf
calibration_loader = torch.utils.data.DataLoader(...)
def transform_fn(data_item):
images, _ = data_item
return images
calibration_dataset = nncf.Dataset(calibration_loader, transform_fn)
- 執行以取得量化模型
model = ... #OpenVINO/ONNX/PyTorch/TF object
quantized_model = nncf.quantize(model, calibration_dataset)
關於如何使用NNCF進行模型量化和壓縮的教程可以在這裡找到,其中我們驗證了將訓練後量化應用於YOLOv5模型,精度幾乎沒有下降(如圖7)。
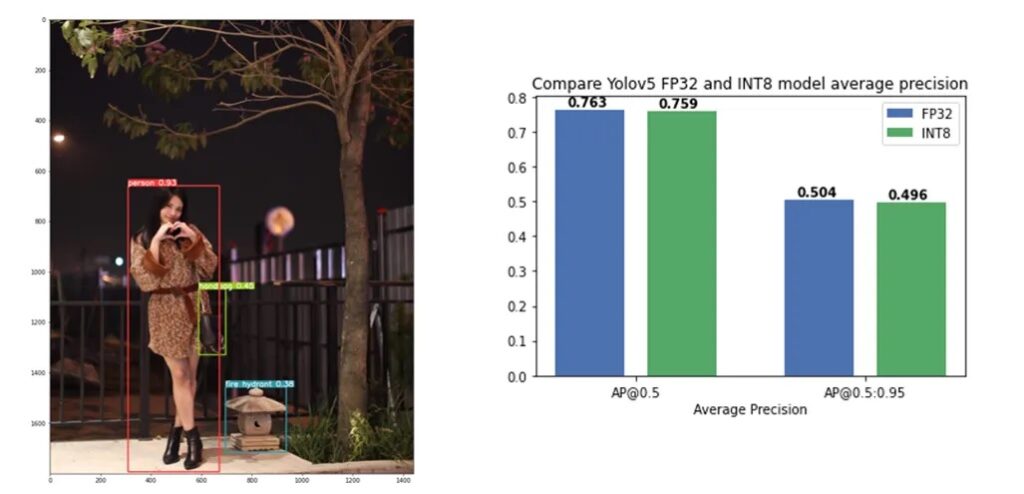
圖7:將訓練後量化應用於YOLOv5模型,精度幾乎沒有下降。
CPU外掛程式中的執行緒調度
提升Intel平台的多執行緒調度(multi-thread scheduling)。
有了新的ov::hint::scheduling_core_type屬性,可以透過選擇在{ov::hint::SchedulingCoreType::ANY_CORE, ov::hint::SchedulingCoreType::PCORE_ONLY, ov::hint::SchedulingCoreType::ECORE_ONLY}上執行推論來配置性能優先或能效優先,用於Intel 12代及以上的CORE CPU或HYBRID平台。
透過將ov::hint::enable_hyper_threading屬性設置為 “True”,實體與邏輯核心都可以在Intel平台的性能核心上啟用,帶來性能提升。
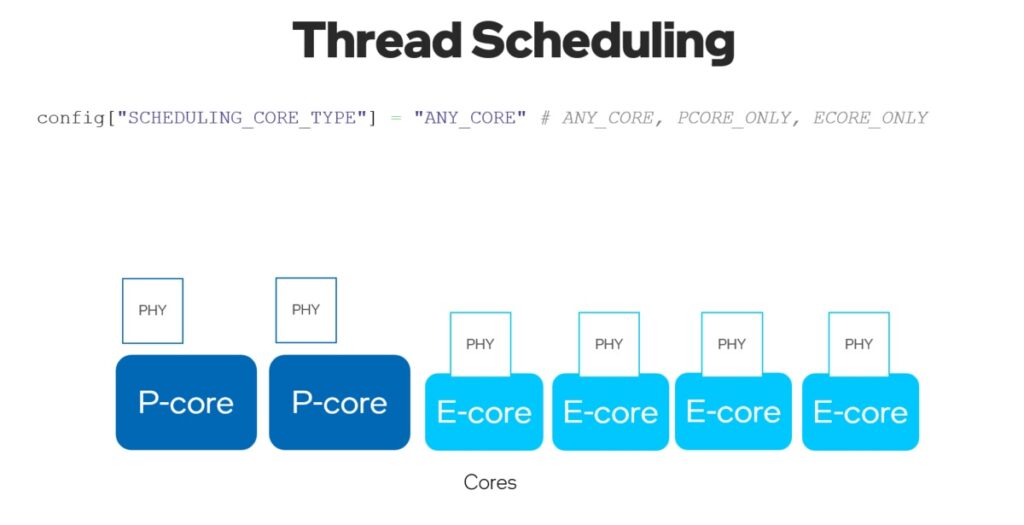
圖8:在CPU外掛程式已改善的多執行續啟用 “SCHEDULING_CORE_TYPE “和 “ENABLE_HYPER_THREADING”。
另一個新屬性是ov::hint::enable_cpu_pinning。預設情況下,ov::hint::enable_cpu_pinning被設置為 “True”, 這意味著用於執行多個深度學習模型推論請求的多個執行緒,將由 OpenVINO 執行時間(TBB)調度。在這種模式下,具有多個執行緒的一個深度學習模型的推論將被視為一整個圖,其中每個執行緒將綁定到 CPU 處理器,而不會導致快取遺失(cache missing)和額外開銷(overhead)。但是,在同時執行兩個神經網路推論的情況下,可能在相同的 CPU 處理器上調度不同深度學習模型推論請求的多個執行緒,從而導致對相同處理器資源上的競爭(如圖 9所示)。
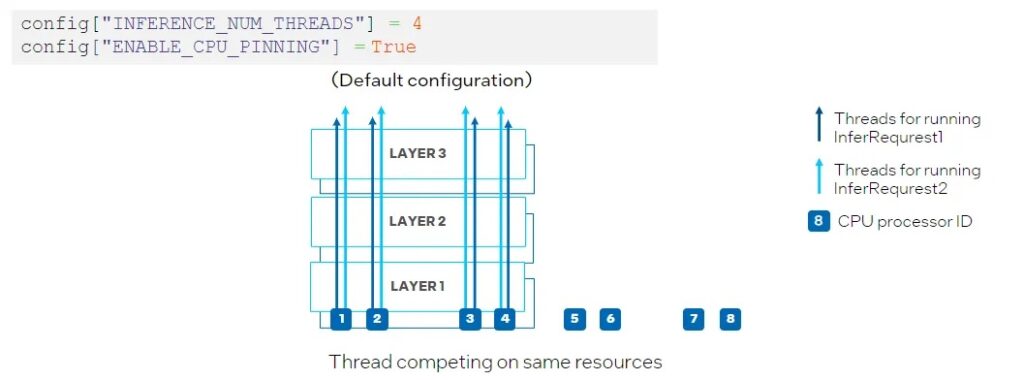
圖 9:在CPU外掛程式中設置 “ENABLE_CPU_PINNING “為 “True”,為多執行緒啟用TBB調度。
為了避免 CPU 處理器資源競爭,我們可以透過將 ov::hint::enable_cpu_pinning 設置為 “False”來禁用處理器綁定屬性,並讓作業系統為神經網路的每個執行緒調度處理器資源。在這種模式下,同一深度學習模型不同層上的推論可能會在不同的處理器之間切換,從而導致快取遺失和額外的開銷(如圖 10 ),此時開發者可以根據實際的測試結果,選擇最合適的方案進行部署。
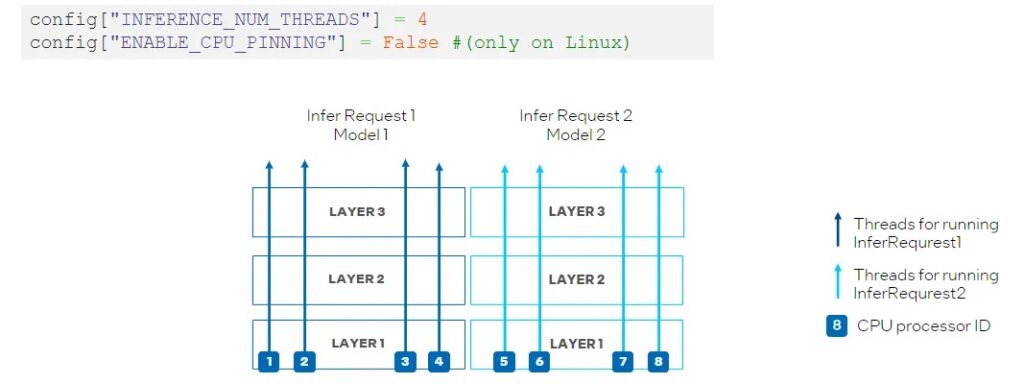
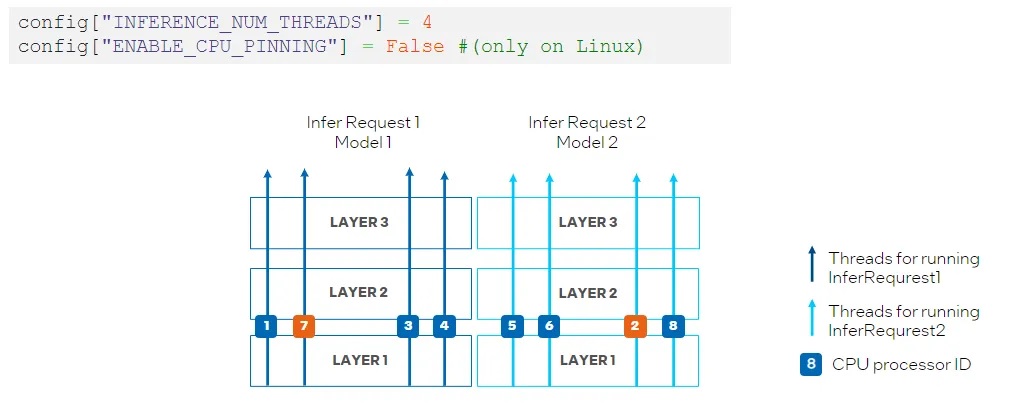
圖10:在CPU外掛程式中設置 “ENABLE_CPU_PINNING “為 “False”,由作業系統調度多執行緒。
升級到OpenVINO 2023.0
OpenVINO能讓您的AI應用自始至終都能充分發揮作用。有了您的持續支援,我們可以為各地的開發人員提供有價值的升級。憑藉其智慧和全面的功能,OpenVINO就像您身邊有一位自己的性能工程師。
您可以使用以下指令升級到OpenVINO 2023.0:
pip install — upgrade openvino-dev
但是請確定檢查過所有的依賴項,因為升級可能會更新OpenVINO之外的其他套件。如果您希望安裝C/ C++ API,拉一個預構建的Docker鏡像或從其他儲存庫下載,請連結下載頁面尋找適合您需求的套件。如果您正在尋找模型部署指令,請查看新的文件。
額外資源:
Provide Feedback & Report Issues
(參考原文:Accelerate AI: Introducing OpenVINO™ 2023.0)

- OpenVINO 2025.3: 更多生成式AI,釋放無限可能 - 2025/09/26
- 用OpenVINO GenAI解鎖LoRA微調模型推論 - 2025/08/29
- 用OpenVINO GenAI解鎖LLM極速推論:推測式解碼讓AI爆發潛能 - 2025/04/23
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


