作者:武卓
YOLO家族又添新成員了!作為以目標檢測領域聞名的模型家族,You Only Look Once (YOLO) 推出新模型的速度可謂是越來越快。就在1月份,YOLO又推出了最新的YOLOv8模型,其模型結構和架構上的創新,以及所提供的性能提升,使其剛問世就獲得廣大開發者的關注。
YOLOv8的性能到底怎麼樣?如果說利用OpenVINO的量化和加速,利用英特爾CPU、整合式顯卡以及獨立顯卡與同一程式碼庫無縫協作,可以獲得1000+ FPS的性能,你相信嗎?那不妨繼續往下看,我們將一步步教你利用OpenVINO在英特爾處理器上實現這樣的性能。

圖1. YOLOv8推論結果範例。
讓我們開始吧!
注意:以下步驟中的所有程式碼來自OpenVINO Notebooks開源庫中的”230-yolov8-optimization” notebook 程式碼範例,可以點擊以下連結直達原始程式碼:openvino_notebooks/230-yolov8-optimization.ipynb at main · openvinotoolkit/openvino_notebooks · GitHub
第一步:安裝相對應工具套件及載入模型
本次程式碼範例我們使用的是Ultralytics YOLOv8模型,因此需要首先安裝相對應工具套件。
然後下載及載入相對應的PyTorch模型。
MODEL_NAME = "yolov8n"
model = YOLO(f'{MODEL_NAME}.pt')
label_map = model.model.names
定義測試圖片的路徑,獲得原始PyTorch模型的推論結果。
results = model(IMAGE_PATH, return_outputs=True)
其執行效果如下:

為將目標檢測的效果以視覺化形式呈現,需要定義相對應的函數,最終執行效果如下圖所示:

第二步: 將模型轉換為OpenVINO IR格式
為獲得良好的模型推論加速,並更方便的部署在不同的硬體平台上,接下來我們首先將YOLO v8模型轉換為OpenVINO IR模型格式。YOLOv8提供了用於將模型匯出到不同格式(包括OpenVINO IR格式)的API。model.export負責模型轉換。我們需要在這裡指定格式,此外,我們還可以在模型中保留動態輸入。
model_path = Path(f"{MODEL_NAME}_openvino_model/{MODEL_NAME}.xml")
if not model_path.exists():
model.export(format="openvino", dynamic=True, half=False)
接下來我們來測試一下轉換後模型的準確度如何。執行以下程式碼,並定義相對應的前處理、後處理函數。
core = Core()
ov_model = core.read_model(model_path)
device = "CPU" # GPU
if device != "CPU":
ov_model.reshape({0: [1, 3, 640, 640]})
compiled_model = core.compile_model(ov_model, device)
在單張測試圖片上進行推論,可以得到如下推論結果:

第三步: 在資料集上驗證模型準確度
YOLOv8是在COCO資料集上進行預訓練的,因此為了評估模型的準確性,我們需要下載該資料集。根據YOLOv8 GitHub開源庫中提供的說明,我們還需要下載模型作者使用的格式的標註,以便與原始模型評估功能一起使用。
from zipfile import ZipFile
sys.path.append("../utils")
from notebook_utils import download_file
DATA_URL = "http://images.cocodataset.org/zips/val2017.zip"
LABELS_URL = "https://github.com/ultralytics/yolov5/releases/download/v1.0/coco2017labels-segments.zip"
OUT_DIR = Path('./datasets')
download_file(DATA_URL, directory=OUT_DIR, show_progress=True)
download_file(LABELS_URL, directory=OUT_DIR, show_progress=True)
if not (OUT_DIR / "coco/labels").exists():
with ZipFile(OUT_DIR / 'coco2017labels-segments.zip' , "r") as zip_ref:
zip_ref.extractall(OUT_DIR)
with ZipFile(OUT_DIR / 'val2017.zip' , "r") as zip_ref:
zip_ref.extractall(OUT_DIR / 'coco/images')
data_loader = validator.get_dataloader("datasets/coco", 1)
接下來,我們配置DetectionValidator並創建DataLoader。原始模型儲存庫使用DetectionValidator包裝器,它表示精度驗證的過程。它創建DataLoader和評估標準,並更新DataLoader生成的每個資料批次之度量標準。此外,它還負責資料預處理和結果後處理。對於類初始化,應提供配置。我們將使用預設值,但可以用一些參數替代,以測試自訂資料,程式碼如下。
from ultralytics.yolo.configs import get_config
args = get_config(config=DEFAULT_CONFIG)
args.data = "coco.yml"
Validator配置程式碼如下:
from ultralytics.yolo.utils.metrics import ConfusionMatrix
validator.is_coco = True
validator.class_map = ops.coco80_to_coco91_class()
validator.names = model.model.names
validator.metrics.names = validator.names
validator.nc = model.model.model[-1].nc
定義驗證函數,以及列印相對應測試結果的函數,結果如下:

第四步: 利用NNCF POT 量化 API進行模型最佳化
Neural network compression framework (NNCF) 為OpenVINO中的神經網路推論最佳化提供了一套先進的演算法,精度下降最小。我們將在後訓練(Post-training)模式中使用8位元量化(無需微調)來最佳化YOLOv8。
最佳化過程包括以下三個步驟:
- 建立量化資料集Dataset;
- 執行nncf.quantize來得到最佳化模型
- 使用序列化函數openvino.runtime.serialize來得到OpenVINO IR模型。
建立量化資料集程式碼如下:
from typing import Dict
def transform_fn(data_item:Dict):
"""
Quantization transform function. Extracts and preprocess input data from dataloader item for quantization.
Parameters:
data_item: Dict with data item produced by DataLoader during iteration
Returns:
input_tensor: Input data for quantization
"""
input_tensor = validator.preprocess(data_item)['img'].numpy()
return input_tensor
quantization_dataset = nncf.Dataset(data_loader, transform_fn)
執行nncf.quantize程式碼如下:
ov_model,
quantization_dataset,
preset=nncf.QuantizationPreset.MIXED,
ignored_scope=nncf.IgnoredScope(
types=["Multiply", "Subtract", "Sigmoid"], # ignore operations
names=["/model.22/dfl/conv/Conv", # in the post-processing subgraph
"/model.22/Add",
"/model.22/Add_1",
"/model.22/Add_2",
"/model.22/Add_3",
"/model.22/Add_4",
"/model.22/Add_5",
"/model.22/Add_6",
"/model.22/Add_7",
"/model.22/Add_8",
"/model.22/Add_9",
"/model.22/Add_10"]
))
最終序列化函數程式碼如下:
int8_model_path = Path(f'{MODEL_NAME}_openvino_int8_model/{MODEL_NAME}.xml')
print(f"Quantized model will be saved to {int8_model_path}")
serialize(quantized_model, str(int8_model_path))
執行後得到的最佳化的YOLOv8模型保存在以下路徑:
yolov8n_openvino_int8_model/yolov8n.xml
接下來,執行以下程式碼在單張測試圖片上驗證最佳化模型的推論結果:
quantized_model.reshape({0, [1, 3, 640, 640]})
quantized_compiled_model = core.compile_model(quantized_model, device)
input_image = np.array(Image.open(IMAGE_PATH))
detections = detect(input_image, quantized_compiled_model)[0]
image_with_boxes = draw_boxes(detections, input_image)
Image.fromarray(image_with_boxes)
執行結果如下:

驗證下最佳化後模型的精度,執行如下程式碼:
print_stats(fp_stats, validator.seen, validator.nt_per_class.sum())
print("INT8 model accuracy")
print_stats(int8_stats, validator.seen, validator.nt_per_class.sum())
得到結果如下:

可以看到模型精度相較於最佳化前,並沒有明顯的下降。
第五步: 比較最佳化前後模型的性能
接著,我們利用OpenVINO 基準測試工具Benchmark Python Tool來比較最佳化前(FP32)和最佳化後(INT8)模型的性能。在這裡,我們分別在英特爾®Xeon®第三代處理器(Xeon Ice Lake Gold Intel 6348 2.6 GHz 42 MB 235W 28 cores)上執行CPU端的性能比較。針對最佳化前模型的測試程式碼和執行結果如下:
!benchmark_app -m $model_path -d CPU -api async -shape "[1,3,640,640]"
FP32模型性能:
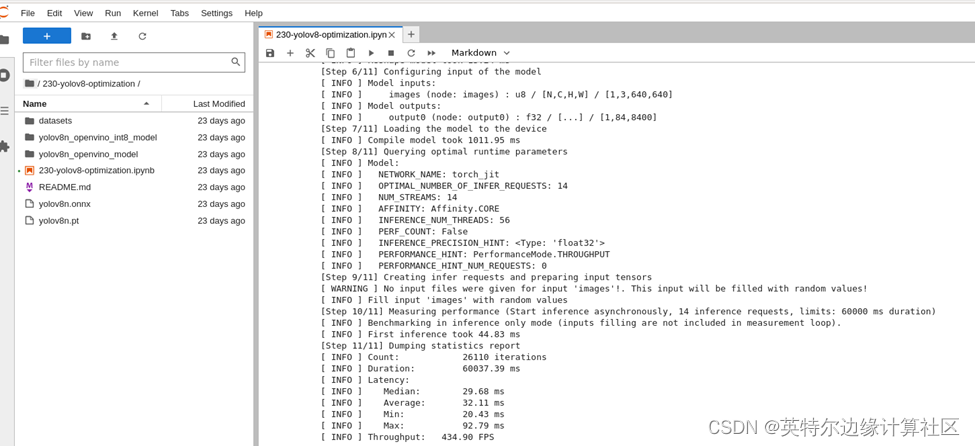
INT8模型性能:
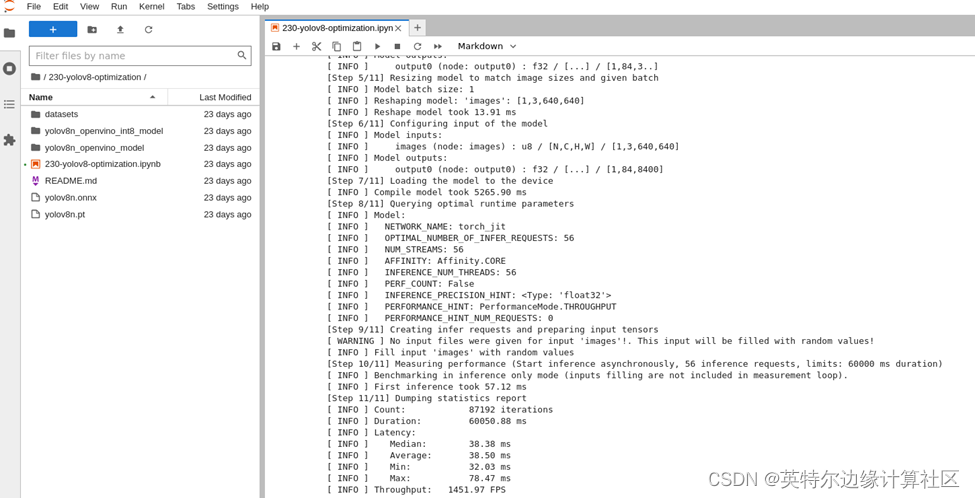
已經達到了1400+ FPS!
在英特爾獨立顯卡上的性能又如何呢?我們在Arc A770m上測試效果如下:
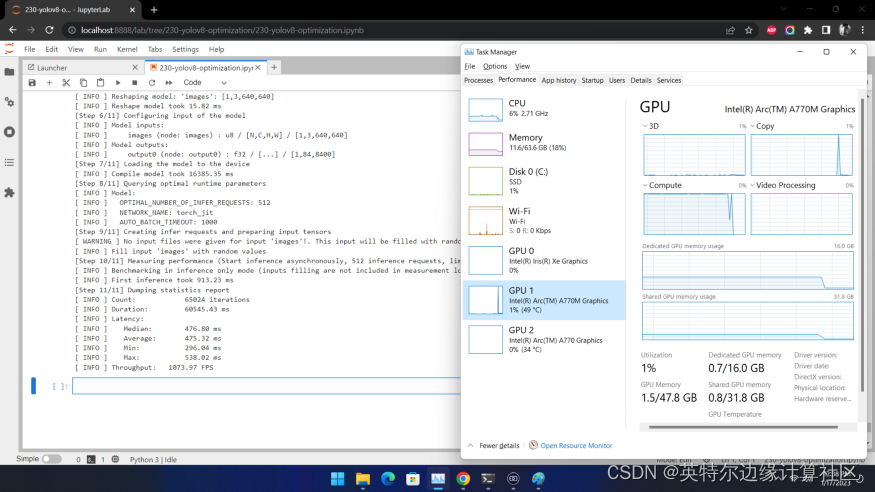
也超過了1000 FPS!
需要注意的是,想獲得如此高性能,需要將推論在吞吐量模式下執行,並使用多流和多個推論請求(即同時執行多個)。同樣,仍然需要確保對預處理和後處理管道進行微調,以確保沒有性能瓶頸。
第六步: 利用網路攝影機執行即時測試
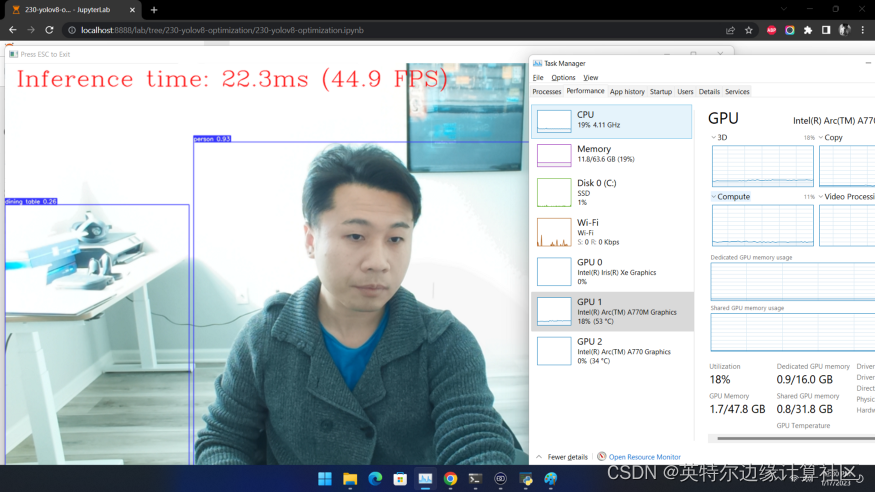
除了基準測試工具外,如果你想利用自己的網路攝影機體驗即時推論的效果,可以執行我們提供的即時執行目標檢測函數。
獲得類似如下圖的效果:
第七步: 進一步提升性能的小技巧
- 非同步推論流水線
在進行目標檢測的推論時,推論性能常常會因為資料輸入量的限制而受到影響。此時,採用非同步推論的模型,可以進一步提升推論的性能。非同步API的主要優點是,當設備忙於推論時,應用程式可以同時執行其他任務(例如填充輸入或調度其他請求),而不是等待當前推論先完成。要了解如何使用OpenVINO執行非同步推論,請參閱AsyncAPI課程。
- 使用預處理API
預處理API允許將預處理作為模型的一部分,從而減少應用程式碼以及對其他影像處理庫的依賴。預處理API的主要優點是將預處理步驟整合到執行圖中,並將在選定的設備(CPU/GPU/VPU/等)上執行,而不是作為應用程式的一部分始終在CPU上執行。這將提高所選設備的利用率。更詳細的預處理API資訊,請參閱預處理課程 Optimize Preprocessing — OpenVINO documentation 。
對於本次YOLOv8範例來說,預處理API的使用包含以下幾個步驟:
1.初始化PrePostProcessing對象
ppp = PrePostProcessor(quantized_model)
2. 定義輸入資料格式
ppp.input(0).tensor().set_shape([1, 640, 640,]).set_element_type(Type.u8).set_layout(Layout('NHWC'))
pass
3. 描述預處理步驟
預處理步驟主要包括以下三步:
- 將資料類型從U8轉換為FP32
- 將資料佈局從NHWC轉換為NCHW格式
- 透過按比例因數255進行除法歸一化每個像素
程式碼如下:
print(ppp)
4. 將步驟整合到模型中
serialize(quantized_model_with_preprocess, str(int8_model_path.with_name(f"{MODEL_NAME}_with_preprocess.xml")))
具有整合預處理的模型已準備好載入設備。現在,我們可以跳過檢測函數中的這些預處理步驟,直接執行如下推論:
"""
OpenVINO YOLOv8 model with integrated preprocessing inference function. Preprocess image, runs model inference and postprocess results using NMS.
Parameters:
image (np.ndarray): input image.
model (Model): OpenVINO compiled model.
Returns:
detections (np.ndarray): detected boxes in format [x1, y1, x2, y2, score,label]
"""
output_layer = model.output(0)
img = letterbox(image)[0]
input_tensor = np.expand_dims(img, 0)
input_hw = img.shape[:2]
result = model(input_tensor)[output_layer]
detections = postprocess(result, input_hw, image)
return detections
compiled_model = core.compile_model(quantized_model_with_preprocess, device)
input_image = np.array(Image.open(IMAGE_PATH))
detections = detect_without_preprocess(input_image, compiled_model)[0]
image_with_boxes = draw_boxes(detections, input_image)
Image.fromarray(img_with_boxes)
結語
整個步驟就是這樣,現在就開始跟著我們提供的程式碼和步驟,動手試試用OpenVINO最佳化和加速YOLOv8吧!
關於英特爾OpenVINO開源工具套件的詳細資料,包括其中我們提供的三百多個經驗證與最佳化預訓練模型詳細資料,請點擊此連結。
除此之外,為了方便大家了解並快速掌握OpenVINO的使用,我們還提供了一系列開源的Jupyter notebook demo。執行這些notebook,就能快速理解在不同場景下如何利用OpenVINO實現包括電腦視覺、語音及自然語言處理在內的一系列任務。OpenVINO notebooks的資源可在Github下載安裝 。
(責任編輯:Judith Cheng)

- OpenVINO 2025.3: 更多生成式AI,釋放無限可能 - 2025/09/26
- 用OpenVINO GenAI解鎖LoRA微調模型推論 - 2025/08/29
- 用OpenVINO GenAI解鎖LLM極速推論:推測式解碼讓AI爆發潛能 - 2025/04/23
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


