作者:尤濬哲
大家好,小弟夜市小霸王,如果大家有聽過我的名字可能都是在ESP32領域吧!不過這次很高興受到MakerPRO歐大的邀請,請小弟對ADLINK這台ROS系統在Edge AI上的應用及效能評測,這真是對我莫大的光榮。主要這台機器是我們台灣AI工業電腦的產品,同時也是全球邊緣運算電腦的佼佼者剛上市不久的最新產品,就讓小弟能第一手實機操作到,實在是機會難得,相信大家一定非常期待。
本文將介紹ROS解決方案及OpenVINO架構,以及大家最期待的YOLOv3 benchmark,好吧,廢話不多說,我們開始吧。
ROS/ROS2邊緣運算方案
在AI風起雲湧的時代,各個產業也都想著要如何AI改善體質,在紅海中殺出重圍脫穎而出,以目前AI的架構來說,可以分成雲端(Cloud)運算及邊緣(Edge)運算,雲端運算適合處理大量複雜的資料,但同時間也可能因為雲端資料處理或網路延遲等問題,因而較不適合需要即時運算的系統。
以「自動駕駛車」這個議題為例,如果我們採用雲端運算方式,將現場環境照片傳輸到雲端伺服器,分析後再回傳告知行進方向,這樣的架構雖然可以利用雲端伺服器來做精確推算,但是網路延遲可能會產生嚴重問題。
舉例來說,一台以時速100Km行進中車輛,如果網路發生延遲1秒,汽車在這1秒內經前進27公尺了,如果前方發生事故,是無法即時閃避的,而且網路也不是百分之百覆蓋,一旦進入無網路訊號的山區也會發生危險。此外雲端運算資料都存在雲端資料庫,有些廠商也會對資料安全要求較高者也不合適。
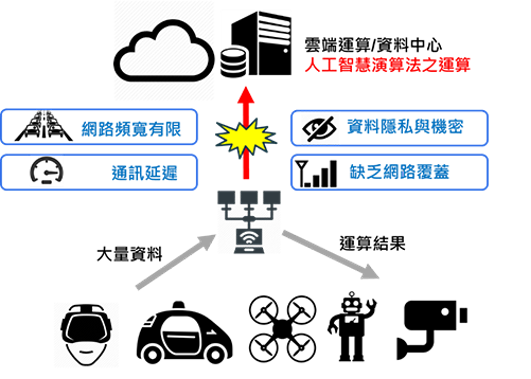
雲端運算可能的問題。(圖片來源)
因此這類需要即時運算的系統就必須採用邊緣運算架構,所謂邊緣運算就是在AI應用現場建立本地端系統,即時對現場狀況進行預測及反應,不需要透過網路傳輸到伺服器進行演算,邊緣運算架構雖然能即時反應,但這樣卻會造成兩個問題,分別是:1.運算能力; 2.能源消耗。
1. 運算能力:
邊緣運算不像雲端,雲端可以有大機房,一望無際的伺服器及資料庫來支援運算,而邊緣運算的機器必須整合在現有環境。以自動駕駛車為例,我們不可能背一座機房來做道路辨識與環境掃描,只能選擇一台體積不能太大的機器,以利整合進汽車的空間內。這樣來說的話,機器的運算能力就會受到限制,因此如何作到運算能力與機器大小的Trade off就是一門學問了。
2. 能源消耗:
相同的,在雲端機房我們可以直接連線市電,怕機器太熱還有冷氣可以吹。但是邊緣機器通常是吃電池的,不能消耗太多電能,總不能為了讓機器能辨識道路,結果消耗太多能源,導致車輛無法行駛,這樣就本末倒置了。
以ADLINK這台NeuronBot機器人而言,就必須要把邊緣運算裝置縮小且還要保持一定的運算能力,並且保持在低功耗的狀態,才能讓機器人完成交付的工作。

採用Intel OpenVINO架構的NeuronBot 機器人。(圖片來源:ADLINK)
要達成機器小、高運算能力、低能源消耗的邊緣運算裝置真的不容易,不過這次ADLINK及Intel合作,採用OpenVINO的ROS/ROS2架構,則是非常好的解決方案。
OpenVINO
如果談到AI運算加速,大家應該都會先想到的是NVIDIA顯示卡,主要是利用GPU內的CUDA單元進行AI加速運算。不過CPU的龍頭老大Intel其實早就開始佈局,2006年即收購VPU廠商Movidius,並在2017年中推出了第一代神經元運算棒(NCS)及在2018年底推出了第二代產品,主要適用在樹莓派這類電腦中進行AI加速,例如在樹莓派中執行YOLO辨識。

結合樹莓派及intel神經元運算棒。(圖片來源:【邊緣運算】如何在樹莓派使用 NCS 神經運算棒)
而OpenVINO則是Intel所推出的AI運算架構,可以支援以Intel CPU、GPU、VPU等產品建立AI加速運算引擎,由於大部分的PC都是採用Intel的CPU,算是採購電腦時必備零件。不過顯示卡就並非必備,例如一些較為中低階產品大部分都是直接使用內建顯示晶片,並無NVIDIA顯示卡,如此在進行AI運算時,效能就明顯不足,OpenVINO則是能補足這一段缺口,讓Intel產品就能直接進行AI加速。
目前OpenVINO可以支援Tensorflow(Keras)、Caffe、MXNet等AI架構,也就是說讀者如果已有訓練好的Tensorflow Model,只要經過轉換,就可直接以OpenVINO中執行Inference運算,釋放Intel的CPU效能,以目前產品線來說,OpenVINO可以支援的產品包括以下系列:
- 6th-11th Generation Intel® Core™
- Intel® Xeon® v5 family
- Intel® Xeon® v6 family
- Intel® Pentium® processor N4200/5, N3350/5, N3450/5 with Intel® HD Graphics
- Intel Movidius NCS
讀者應該不難發現OpenVINO的主要加入裝置是內建Iris的顯示晶片,因此若讀者要使用OpenVINO進行AI加速,必須要注意CPU是否有內建Iris。
除了CPU規格之外,目前OpenVINO也能支援Linux系統,就如筆者手上這台ADLINK RQP-T37來說,預設就是安裝Ubuntu 20.04版。這台的CPU採用i7-1185G7E為第11代Core 處理器,且內建Intel® Iris® Xᵉ 顯示晶片,在低功率運作時僅須12W電力,在電源消耗上十分適合邊緣運算系統,若單純以算力來說,這顆第11代i7的CPU執行效能約等於4-8片神經元運算棒(基於不同的深度學習模型),非常具有優勢。

ADLINK ROScube外型。
RQP-T37可以說ADLINK 在ROScube系列的最高等級產品,出廠直接配備DDR4 3200Mhz 32G RAM及高速M.2 256G NVMe固態硬碟。由於低功耗設計,系統採全金屬無風扇散熱系統,運作時完全無聲,這樣也就避免風扇故障而造成過熱所帶來的系統失效成本。而金屬外殼除了散熱外,也能耐衝擊,非常適合用在AMR(自主移動機器人)及AMIR(自主移動工業機器人)等領域中。

ROScube規格表。(圖片來源:ROScube Pico TGL)
解說完ROScube的規格及外型後,讀者最關心的應該是他在AI運算上的效能表現了吧,下一節我們將使用YOLOv3模型來進行效能分析。
YOLOv3效能比較
YOLO(You only look once)是由Joseph Redmon等人所提出以Darknet架構所建立的物件辨識工具。目前最新版本是YOLOv5,而本次測試則是採用目前較為廣泛使用的YOLOv3,後續篇章我們也會使用不同版本的YOLO來測試(榨乾)這台機器的效能。
本次測試是用來比較Intel OpenVINO加速對於YOLO辨識效能的影響,因此我們會針對開啟及關閉OpenVINO的狀態分別做一次測試。而測試的影片為SmartCityDemo.mp4,讀者可以從筆者的Google Drive中下載,與本機器的效能做個比較。

測試影片:SmartCityDemo.mp4 (1280×720 30fps)
SmartCityDemo.mp4為一段道路交通影片,影片為1280×720 30fps畫質的影片,我們都了解影像辨識畫面解析度越高時,所要辨識的區域就越大,所消耗的時間就越長,因此1280×720高解析度會相對吃力,不過這也能顯示出OpenVINO開啟後的效果。
YOLOv3(FP16-INT8)測試
首先測試的設定是開啟OpenVINO下以YOLOv3(FP16-INT8)在CPU內建的Iris Xe Graphics 上INT8資料格式的執行結果。

開啟OpenVINO的YOLOv3執行辨識結果

CPU使用變化量
在開啟OpenVINO的狀況下,整段的平均FPS都落在43上下,效能相當不錯。更重要的是從系統監視器來觀察CPU使用量,大約都在40-50%之間,偶爾畫面中物件較多時,其比例會較高,但並不影響使用者操作其他功能,例如上網看Youtube也是相當順暢。
下一個測試則是在關閉OpenVINO的狀況下,使用純CPU進行YOLO辨識,其辨識效能FPS均無法超過20,平均大約17-18之間,大約等同於OpenVINO開啟的一半左右。

未開啟OpenVINO的YOLOv3執行辨識結果。
觀察CPU的使用則可以發現,當YOLO辨識開始執行,CPU就會直接飆昇到100%,且辨識過程一直維持CPU全力工作的狀態,而這樣的結果就會導致其他工作視窗鈍鈍的無法順利操作。

CPU使用變化量。
小結
綜合本次測試,在開啟OpenVINO的狀況下,YOLOv3辨識可以獲得42.5FPS的成績,對於一般需要即時辨識系統來說已經相當足夠。另外一個優勢則是可以大量降低CPU的使用量,讓系統仍然可以進行其他工作,例如將辨識結果存入資料庫、或者傳到雲端等。一旦系統使用純CPU運算,不僅FPS會下降,更重要的則是CPU使用量無法降下來,此時不僅會造成其他服務可能會Crash之外,也會導致裝置的能源使用量大增,這樣就無法達到邊緣裝置的基本要求了。
本期只是進行初步的測試及介紹,讓讀者了解Intel在AI加速這塊的OpenVINO新架構對於邊緣運算的優勢,下一篇文章將會針對OpenVINO進行模型最佳化轉換的效能實測,證明Intel-based PC及NB也能拿來當AI辨識引擎沒問題(文章連結)。
(責任編輯:謝涵如)

學歷:中山大學資訊管理研究所 博士
- 舊瓶裝新酒還是新瓶裝舊酒?Jetson Orin Super效能實測 - 2025/03/12
- 低成本空氣品質感測器 – 夏普 GP2Y10開箱實驗 - 2023/03/16
- 【ESP32專欄】ESP32 MQTT與深度睡眠 - 2022/06/20
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


