作者:賴桑
人腦不像 NN 只會單向思考,那 NN 能像人腦一般靈活嗎?其實是可以的,本章將再介紹新的 NN ,且會有 Keras 實作,馬上來看看這個可以向前、向後跑,還可以隨著內容修訂自己反應的「 RNN 」吧!
看了這麼多的 NN 範例,問題是,人腦…好像不是單向思考的吧!說得沒錯,人腦的神經元可比起電腦的電路更優異,舉個最簡單的例子:你之所以可以看懂這些文字、圖形,甚至我們的程式碼與運算原理說明,那是因為歷來你的大腦裡面,累積了這方面的知識。
講到知識這個詞,有可能像是 kNN 那樣只要背下來就可以嗎?有可能像是 ANN 那樣只要針對已知的分類項目然後把答案湊出來就行嗎?當然不成,你想想,你有記憶以來,透過學習(學校、人們…給你的說明跟示範),都會不斷地對你記憶中所知道的內容進行校正。
好比說:小時候大家會習慣去吃手手,然後媽媽一看到就會說:「手手髒髒,不能放到嘴巴裏」,長大到了高中,美術課被剪刀劃到手,為了止血所以你就吸手指…對不對?同樣是吃手手這件事情,為什麼會不一樣?
因為隨著時間變化,周遭的人事物相對對你產生不同的回饋刺激,讓你對於吃手手這個行為所體認的效果不同,所以人類的知識,能像之前介紹的 NN 那樣,只能單向一直計算或記憶嗎?答案當然是不能。
那怎麼辦?剛剛就提到「回饋刺激」這幾個字,假如 NN 的神經元,是可以向前、向後跑,還可以隨著內容不斷地修訂自己的反應…不就結了嘛!對,這就是遞歸神經網路(Recurrent Neural Networks, RNN)的構想由來。
RNN 的具體化描述
那是怎麼做的呢?其實一點也不意外:
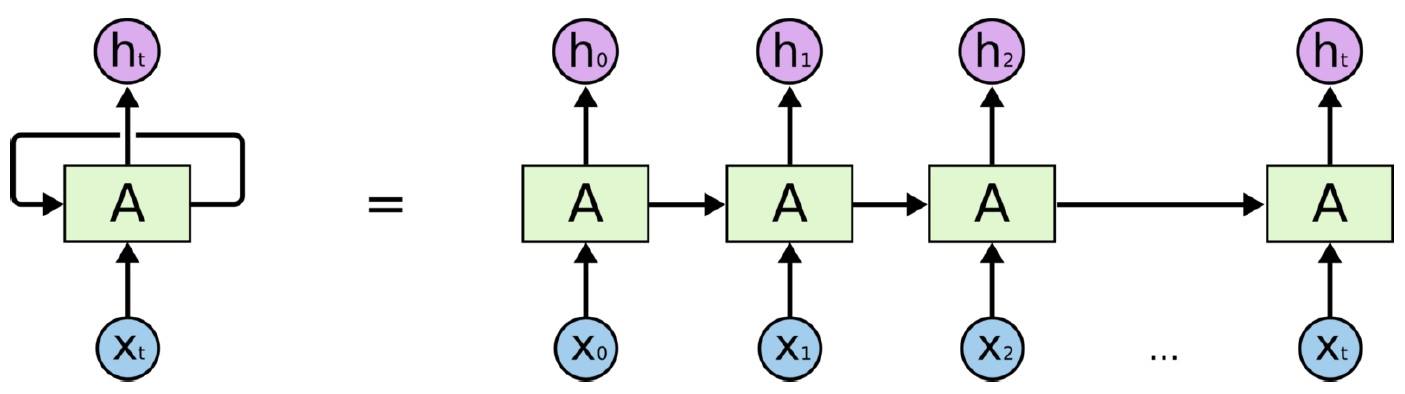
RNN 具體化表示(圖片來源:賴桑提供)
注意看到圖形中有小寫 t 的標示沒?這表示 RNN 本身有針對不同時間點的記憶效果,假如我們由最初系統通電的時間開始看,系統通電時當時 t 為 0,如此一來,就可以整理出像是這樣的等效圖形囉?
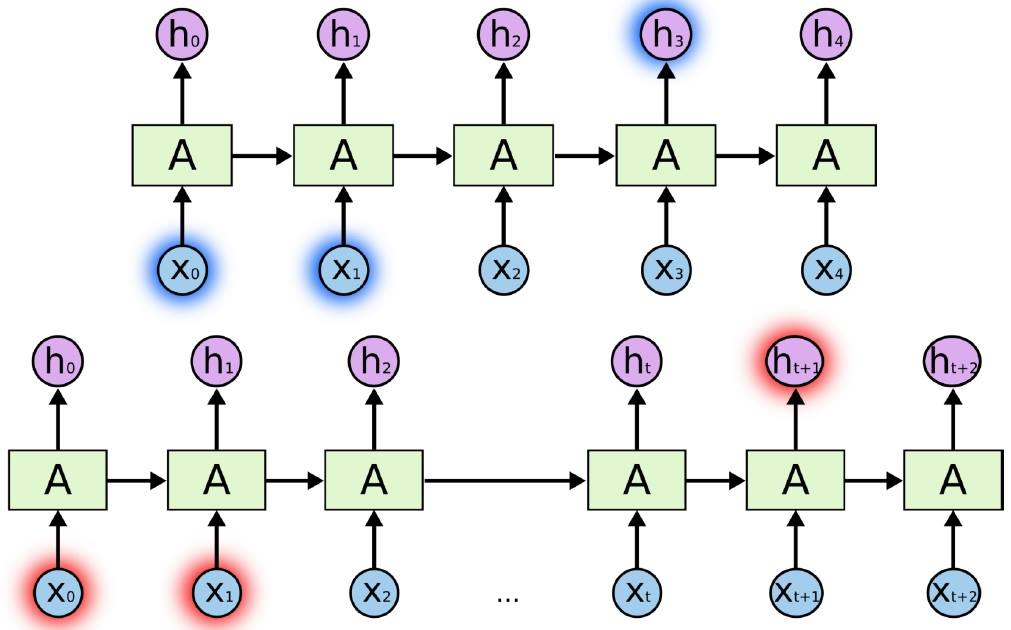
RNN 本身有記憶效果(圖片來源:賴桑提供)
這好像在第一集就看過,就是那個吃女生豆腐挨拳頭的 – 卷積的意思是一樣的?沒錯!其實 RNN 與 CNN 有異曲同工之妙,而且再告訴各位另外一點:監督式學習(Supervised Learning)的 NN,實際上並不像一些課本都寫針對分類或者迴歸的用法才對(本專欄的唯一正確答案就是:從來沒有所謂正確答案),只要小小換一下用法,後面我們會看到例子,迴歸的可以當分類用,分類的也能當迴歸用。
不懂,那怎麼說迴歸跟分類是可以共用,你忘了:輸出層 Output layer 、隱藏層 Hidden layer 誰規定放幾個?通通沒有吧!比較一下兩者的用途跟輸出效果就很清楚了:
| 迴歸 | 分類 | |
| 輸出效果(你想要的) | 連續性的數值,好比說溫度變化就是實數域R下的數據 | 離散的結果,比方說:書本、桌子、椅子…這很明顯是不同實體,或者代表的意義 |
| 用途 | 推算合理的數據 | 找尋合適的決策 |
| 怎麼評估品質? | 跟實際值的差異越小就越好 | 分辨的結果越不會造成混淆越好→針對指定的目標,所評估的機率值越高,辨認人臉的時候,如果有貓臉也出現,人臉所得的機率值會比貓臉更高 |
說回來 RNN,很明顯地 RNN 只是把資料的變化看成一個個時間斷點所導致的按順序排列而已!那你一定會覺得這樣有什麼好處?設想一下:我們人類在對話(自然語言 Natural language )經常會講到前因後果,甚至句子中還會有代名詞出現吧?那…電腦要能夠處理這些…是不是該要具有對時間斷點上的不一樣,而能產生記憶的效果?所以,那電腦產生新聞稿、自己寫小說…是不是很適合 RNN 了?
記住: AI 的時代,沒有最好,只有合適或不合適而已。簡單看一個 RNN 的範例,了解一下透過 Keras 寫 RNN 到底容不容易:
# -*- coding: utf-8 -*-
"""Untitled1.ipynb
Automatically generated by Colaboratory.
Original file is located at
https://colab.research.google.com/drive/1_GjM9bnFnp9UBTC0PS1I3k_GaSEKRz2S
"""
from keras.models import Sequential
from keras.layers import Embedding, SimpleRNN
model = Sequential()
model.add(Embedding(10000, 32))
model.add(SimpleRNN(32, return_sequences=True))
model.add(SimpleRNN(32, return_sequences=True))
model.add(SimpleRNN(32, return_sequences=True))
model.add(SimpleRNN(32))
model.summary()
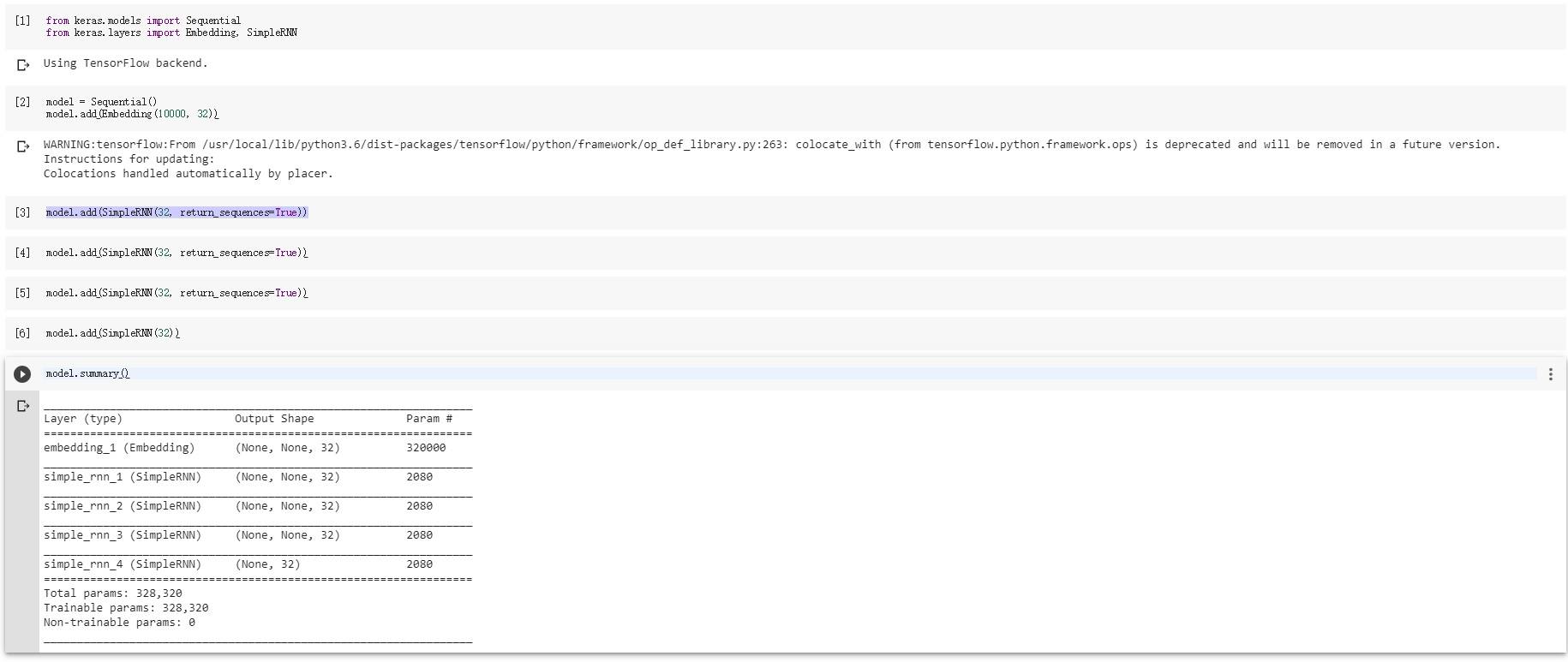
透過 Keras 寫 RNN 其實不難(圖片來源:賴桑提供)
不難吧!不過, FU 不太夠;另外鼓勵大家自己跑一個案例,美國史坦佛大學發表讓電腦看到圖片後,自動造句來描述照片裏面是甚麼,就是 RNN 的運用: https://github.com/karpathy/neuraltalk ,跑起來會像是這樣,注意看底下的字句就是 RNN 產生的喔:

圖片下面的描述是自動判別生成的(圖片來源:賴桑提供)
RNN 的缺陷
應該不少眼尖的人注意到了, RNN 這個設計聽來很厲害,但是…現實上是有可能掛點的,那就是金魚腦袋 — 越前面的成果對最新結果所產生的影響越小,當所經過的時間越長,那麼最前面的成果對於最新產生的結果影響幾乎為0…那麼記憶哩…不見了!這就是有名的梯度消失問題( Vanishing gradient problem )。
什麼叫做梯度?又是怎麼不見的?「梯度」白話地說,就是現實生活上的陡峭程度,也就是變化劇烈與否的程度,舉個動漫的例子: https://www.facebook.com/Cute.Animate.01/videos/1938589032836585/

順著梯度的方向滑,速度會較反方向快(圖片來源:FB 動漫資訊站暨周邊)
滑雪的時候,我們站在高處透過重力加速度可以向下滑去,從上方連結中的影片可以看到,順著梯度向下滑是較快的,反方向則會較慢向下滑,所以梯度是有方向性的,而且還可以看出來變化前後的關係。那麼,如果這高低差不大的話…需要煞車嗎?
這時候,我們想一下:電腦開始透過 RNN 來解決我們的問題,我們所想的一定是:逐步一直跑,跑越後面越接近輸出層 Output layer 的時候,越容易看出來執行效果。
那…假如這變化程度…不清楚了,是不是等於高低差也就是梯度不大?那前後的結果,不就根本差異不大,甚至是一樣的嗎?那要電腦來幫我們跑什麼?這就代表 RNN 有可能因為使用時間不斷地加長,進而導致整個系統跟呆子一樣,給他什麼就輸出什麼,甚至還可能更糟糕,為了要解決問題,反而還製造更多問題。

RNN 有可能因為使用時間不斷地加長(圖片來源:賴桑提供)
所以 RNN 雖然是可行的,但是現實情況上那可不見得了(權重 weight 可能暴增很高),因此近年來不少 人提出改良版本:
- 雙向型:主要輸入不僅與過去的輸入有關,甚至與將來的輸入有關,例如我們需要預測一個句子中間缺失的詞語。
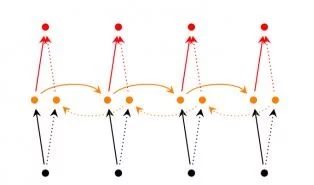
雙向型(圖片來源:賴桑提供)
- 深度型;改良自雙向型,只是每個步驟都需要訓練多層的網絡,所以會讓模型更強大,也就是說…需要更多的數據來訓練。

深度型(圖片來源:賴桑提供)
- LSTM 型;目前最多人推崇的,把 RNN 的隱藏層 Hidden layer 改良後,解決了使用時間增長會導致前面講的金魚腦袋問題,原理是:人腦會遺忘,所以我們讓電腦也會遺忘。通過一種閘道 Gate 的設計,決定電腦需要記住,或遺忘多久時間前的記憶,之後重新聯合先前的狀態、記憶和輸入。
小結
本章我們開始透過 Keras 寫作 NN 了,也了解到原來透過 Keras 就能簡便地對想要的模型進行描述,以此達到目的。另外 RNN 目前可說是最受歡迎的應用之一,但其實仍有不少缺陷,不過能是可以逐步克服的。最後,所謂迴歸跟分類其實就是手心跟手背,一樣是手上肉,只不過用途不同而已。
(責任編輯:楊子嫻)

- 【開箱評測】用Mbed上手開發DSI 2599開發板 - 2020/08/03
- 【OpenVINO™教學】自製麵包影像辨識POS機的應用 - 2019/12/24
- 【邊緣運算】OpenVINO好夥伴 — athena A1 Kit x86單板 - 2019/11/18
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!



2019/07/16
簡賢易懂的文章 謝謝分享