作者:許哲豪
目前當紅的人工智慧(Artificial intelligence,AI)主要聚焦在深度學習(Deep Learning,DL)領域,想學習深度學習技術的人,第一步通常會遇到一大堆框架(Framework)卻不知如何選擇,而究竟什麼是框架?框架如何用來表示模型?哪些才是主流框架?本文將會完整告訴你,協助找出最符合自己需求的框架。
何謂深度學習框架?
深度學習簡單示意圖。(圖片來源:廖庭儀製作)
大家都知道只要準備一張紙和一隻筆,加上源源不斷的靈感,就能將想法轉化成文字,創作出一篇令人感動的文章。但現在手寫創作的人越來越少,只好選用一項電子書寫(數位表達)的工具來創作。以Windows舉例,可能用的是Note Pad(筆記本)、Word或PDF Editor,如果是學術寫作的人可能較常用的是Latex,在網頁上創作則可能是Html。
文章的好壞並不會因為工具的改變而有所不同,卻會影響寫作效率以及排版美觀,改變讀者對這篇文章的評價。雖然文章內容(基本元素)可輕易的在不同工具中轉換,但遇到字體格式、圖片、公式等特殊排版需求時,可能出現檔案轉不過去等問題,同時難以用來表達音樂、影像、視頻。
在解決深度學習的問題中,較常見的是非時序性辨識問題,以及時序性的分析或預測問題。為了方便表達模型(Net /Model)的結構、工作訓練以及推論流程,因此產生了框架,用來正確表達深度學習的模型,就像在Windows上寫文章需要有Note Pad、Word等,編輯影音內容要有威力導演、After Effect等一樣。
名詞解譯
非時序性辨識:針對影像、結構性資料等資料辨識。
時序性辨識:針對語音、翻譯、視頻等資料辨識。
因此,許多學術單位、開源社群甚至Google、Microsoft、Facebook這類知名大公司也紛紛推出自家的框架,以確保在這場AI大戰中能佔有一席之地。而有另一派人馬,想要產生另一種可輕易轉成各家的框架,例如微軟的Word可以另存網頁檔(*.html)、可攜式文件格式(*.pdf)、純文字檔(*.txt)等。在介紹各家框架前,先來認識一下深度學習的模型究竟用了哪些元素?就像玩樂高積木前,要先知道有哪些模塊可用,後續在學習各個框架的表示語法時才不會一頭霧水。
常見深度學習模型介紹
首先介紹兩個較著名的模型,包括非時序性的卷積神經網路(CNN) LeNet-5 [1]以及時序性的遞歸神經網路(RNN),方便說明模型中常用到的元素與流程,如何用深度學習框架來表示。
卷積神經網路(CNN)
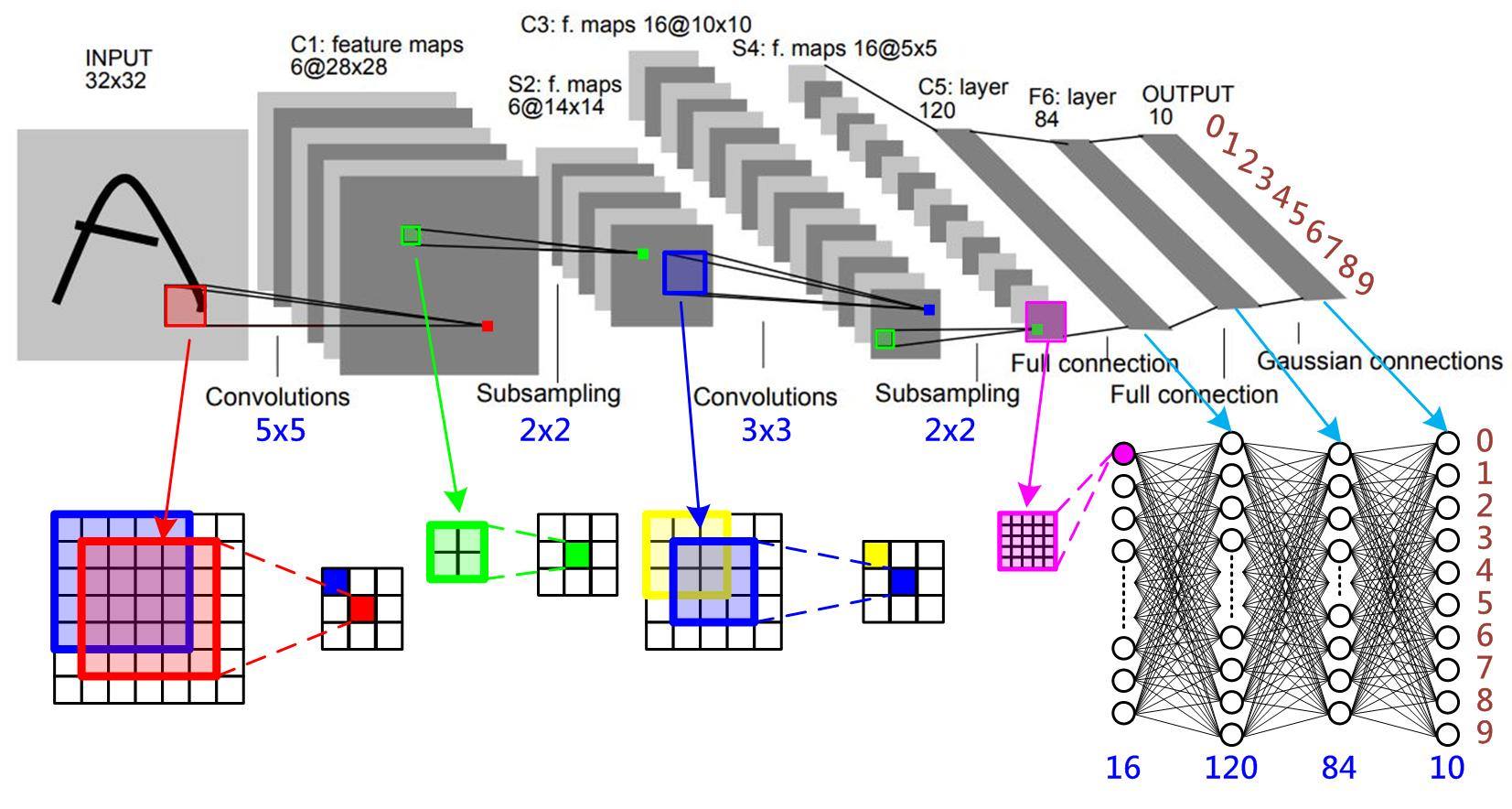
圖一 卷積神經網路(CNN) LeNet-5 [1] (圖片來源:OmniXRI整理繪製)
首先,說明卷積特徵圖 C1層,C1層上的紅點,是由輸入層(INPUT)紅色框(5×5個像素)乘上5×5的卷積核加總後而得,依序由輸入影像的左至右、上至下共用一個卷積核進行卷積,一次移動一個像素(Stride=1),如此即可產生一張特徵圖,而C1層共用了六組卷積核,因此產生六張28×28像素的特徵圖。再來將影像進行池化,較常見的方式就是把相鄰四點(如圖一綠色框所示)中最大的點當成新點,稱為Max Pooling,同時把影像長寬都減為一半,成為S2層。
接下來,對S2層以16組3×3卷積核進行卷積,產生C3層,共有16組10×10像素的特徵圖。同樣地再對C3層進行池化產生S4層,變成16組5×5像素的特徵圖,最後再以16組5×5卷積核把S4層的16個特徵圖卷積變成16個輸入點,再以傳統全連結神經網路進行連結。C5層就是以16個輸入點和隱藏層120點進行全連結,並依指定的激活函數將輸出傳到下一層,接下來再和下一組隱藏層F6的84點進行全連結,最後再和輸出層(OUTPUT)的十個輸出點進行全連結,並正規化輸出得到各輸出的機率,即完成整個LeNet-5模型(網路)結構。
綜合上述內容可得知一個基本的卷積神經網路會有輸入層、卷積層、池化層、全連結層及輸出層。卷積層要定義卷積核大小、移動距離、輸出特徵圖數量。而池化層同樣需要定義核的大小(一般是2×2)、移動距離(一般是2)及池化方式(可以是取最大值或平均值)。全連結層部份則需要定義節點數量及激活函數類型(如:reLu、sigmoid等),最後輸出層除了要定義正規化機率值(如:Softmax)外,還要定義損失函數以作為訓練模型用。
名詞中英文對照
卷積神經網路:Convolutional Neural Networks(CNN)
遞歸神經網路:Recurrent Neural Networks(RNN)
特徵圖:Feature Map
節點:Node
池化:Pooling,Subsampling
全連結神經網路:Full Connection Neural Networks
隱藏層:Hidden Layer
激活函數:Activation Function
輸入層:Input Layer
卷積層:Convolution Layer
池化層:Pooling Layer
全連結層:Full Connected Layer
輸出層:Output Layer
積核大小:Kernel Size
移動距離:Stride
輸出特徵圖:Output
損失函數:Loss Function
前面提到的卷積神經網路CNN是一種前饋(Forward)的單向網路,其輸出結果不會影響輸入,但如果遇到如語音、翻譯、視頻這類時序問題時,CNN就搞不定了,此時就該輪到遞歸神經網路(RNN)登場了。
遞歸神經網路(RNN)
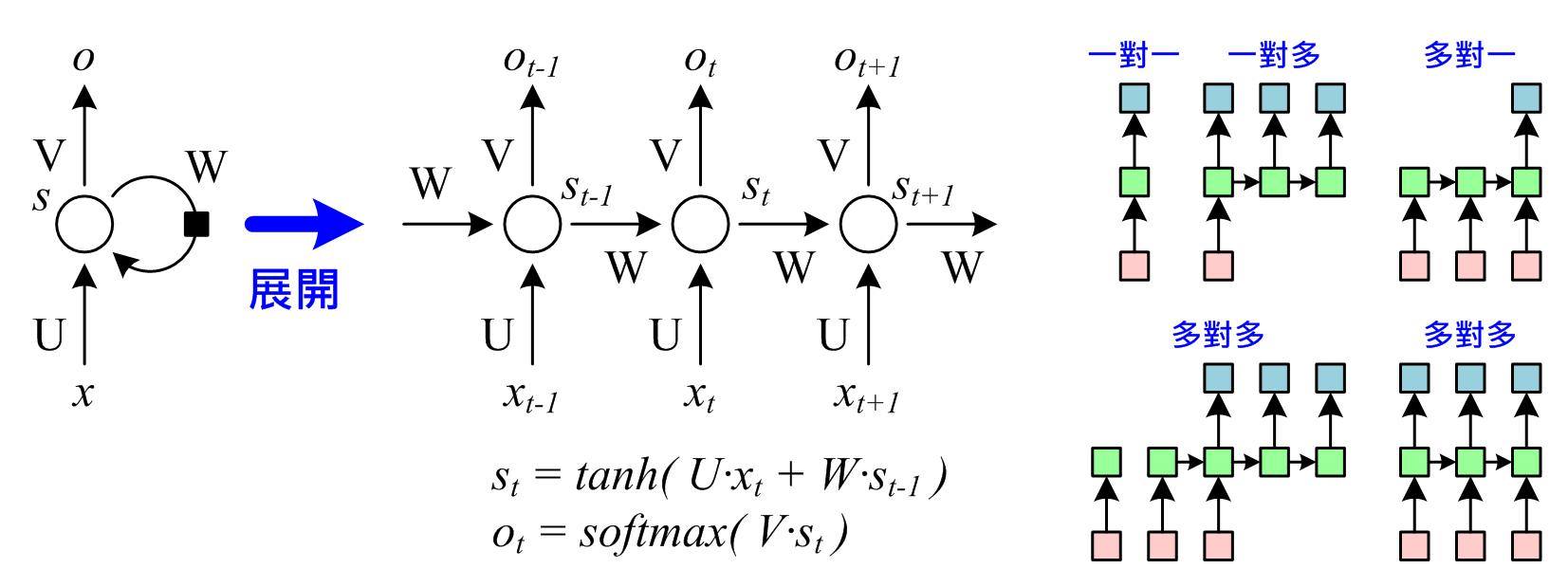
圖二 遞歸神經網路(RNN)及型態 (圖片來源:OmniXRI整理繪製)
(圖二)左圖所示就是RNN最基本入門的模型,把此次輸出的結果經過加權後,再和下一次的輸入一起計算出下一次的輸出,以串起輸入資料的時序關連。從展開圖可更清楚看出其關連,當前輸出(ot)是由目前狀態(st)乘上權重(U)加上前一狀態(st-1)輸出乘上權重(W)後,經過雙曲正切(tanh)函數並乘上輸出權重(V),最後取Softmax算式得出,依此類推可展開成任意級數的網路。
(圖二)右圖所示,RNN可以有很多種輸出型態,一對一就等於單純的前饋網路沒有時序關係,另外也可以一對多、多對一、多對多等不同的輸出方式,應用於時序性內容分類,例如語句情緒意圖、音樂曲風、視頻動作分析、影像加註標題等,或是型態移轉(Style Transfer),例如語言翻譯、文章音樂創作等。
對RNN而言,需要定義展開的級數、隱含層(或稱為狀態S)到隱含層權重矩陣(W)、輸入層到隱含層權重(U)、隱含層到輸出層權重(V)、激活函數(例如:tanh等)類型,以及輸出層機率正規化方式(例如:Softmax等)。
常見深度學習框架及選用考量

圖三 常見深度學習框架(圖片來源:OmniXRI整理製作)
許多人準備開始進入深度學習世界時,最常問的問題就是到底要挑選哪一種框架來入門?有如(圖三)、(表格一)所示,從最大的開源社群Github上,就可找到二十種星星數超過一千的深度學習框架,包括TensorFlow、Keras、Caffe、PyTorch、CNTK、MXNet、DL4J、Theano、Torch7、Caffe2、Paddle、DSSTNE、tiny-dnn、Chainer、neon、ONNX、BigDL、DyNet、brainstorm、CoreML等,而排名第一名的TensorFlow更有近十萬個星星。由此可知,深度學習非常受到大家重視,當選擇深度框架時可以從好幾個面向來考慮,以下將會分別介紹。
1. 程式語言
首先是開發時所使用的程式語言,如果要執行「訓練」及「推論」效率好些,則可能要用C++。若要上手容易、支援性強,則要考慮Python,從(表格一)中可看出有3/4的框架都支援Python。
若習慣使用Java開發程式,那大概就只有TensorFlow、DL4J和MXNet可選了。目前有一些框架(如TensorFlow、Caffe等)底層是C++,應用層API是用Python,這類框架能取得不錯的開發及執行效率。
若想改善底層效率時,還要考慮依不同硬體,學會OpenCL或Nvidia的CUDA/cuDNN等平行加速程式寫法。
2. 執行平台
再來考慮的是可執行的作業系統及硬體(CPU、GPU)平台,目前大多數的框架都是在Linux CPU+GPU的環境下執行,部份有支援單機多CPU(多執行緒)或多GPU協同計算以加速執行時間,甚至像TensorFlow、CNTK、DL4J、MXNet等框架還有支援叢集(Cluster)運算。
許多雲端服務商(Google、Amazon、Microsoft等)也是採取這類組合,方便佈署開發好的應用程式。另外也有些非主流的框架(如:tiny-dnn)只支援CPU而不支援GPU,這類框架的好處就是移植性較強,但工作效率很差,較適合小型系統。
如果是用Windows的人,英特爾(Intel)及微軟(Microsoft)也分別有提供BigDL及CNTK,若使用Mac系統則要考慮使用CoreML。不過最近Google的TensorFlow為了吃下所有的市場,已經可以支援Linux、Windows、Mac甚至是Android,因此成為開源排行榜第一名。
3. 模型支援
目前常見的深度學習模型包含監督型(如CNN)、時序型(如RNN/LSTM)、增強學習(如Q-Learning)、轉移學習、對抗生成(GAN)等,但不是每個框架都能全部支援。
舉例來說:老牌的Caffe適合做監督型學習,但對於時序型學習就不太合適,遇到對抗生成模型時就更使不上力。若不清楚那些框架可支援的模型類型,可參考(表格一)的對應網址,前往各官網了解使用上的限制。
4. 框架轉換
如果遇到需要串接不同平台或框架時,則要考慮選用具有提供跨框架功能。目前有幾大陣營,像Keras可支援TensorFlow、Theano、MXNet、DL4J、CNTK,而微軟和臉書聯盟推的ONNX可支援Caffe2、CNTK、PyTorch等,但Google的TensorFlow卻不願加入該聯盟。
另外,雖然框架之間可以轉換,但不代表轉換後的執行效率會和直接使用某個框架一樣好,此時只能依實際需求來取捨是否拿彈性換取效能。
5. 社群支援
最後要考慮選用的框架社群是否活躍,是否很久沒有維護(升級),甚至被預告即將淘汰,像Theano雖然功能強大也有很多人在用,但目前確定已不再更新版本,因此建議不要再跳坑了。另外對於英文不好的朋友,選用框架的社群討論區、文字教程、操作視頻等是否有中文支援也是很重要的,以免遇到問題不知向誰求救。
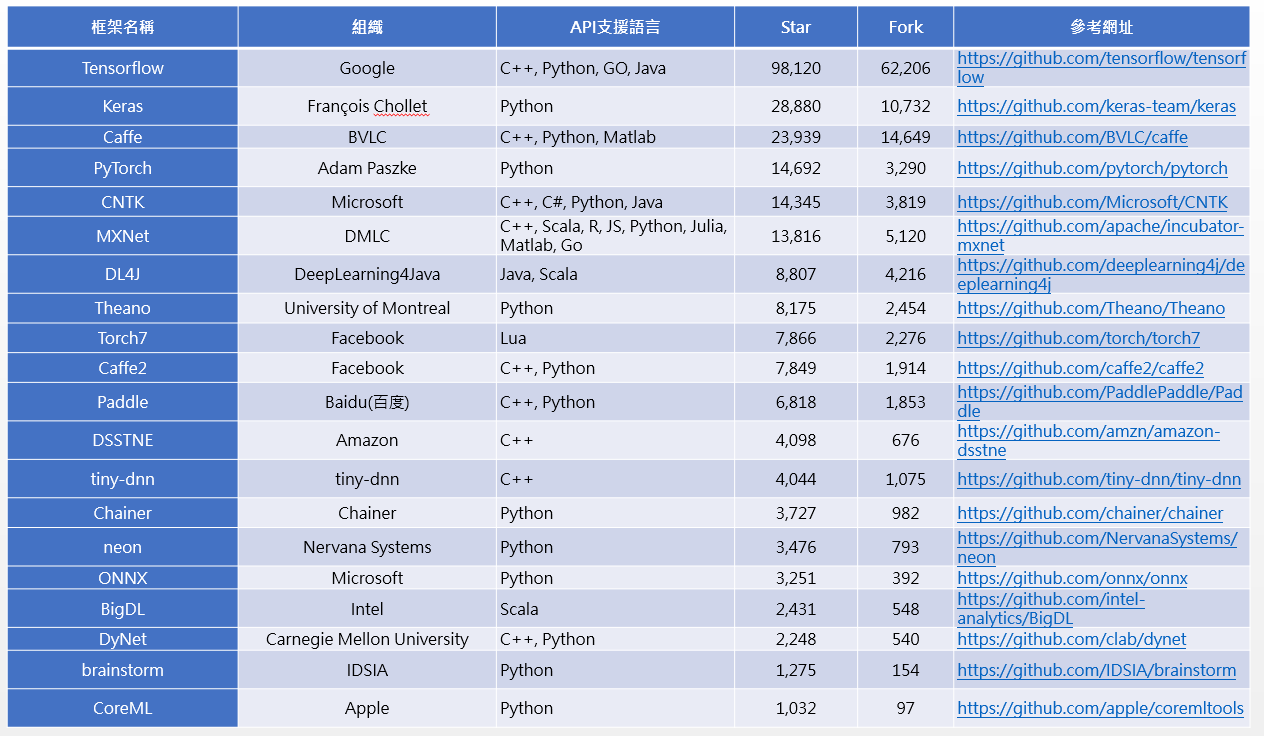
表格一 深度學習框架比較表(圖片來源:OmniXRI整理製作,廖庭儀重製;統計日期:2018/05/02)
總結
對於新手來說,目前用Python+Keras+TensorFlow是最多人的選擇,網路上也可取得最多資源(包含中文),可支援的作業系統、硬體平台、模型以及數學函式庫也是最豐富的。特色是彈性大,相對容易開發,也是最容易佈署在雲端的解決方案。
但這樣的組合並非完全沒有缺點,例如CNTK的執行效率相較於MXNet略差,而Python需佔用較多記憶體,不利於佈署在本地端(或嵌入式系統)進行邊緣計算,因此如何選擇合適的框架,有賴於大家多花點心思了。
(參考文獻在這裡,本文同步發表於歐尼克斯實境互動工作室(OmniXRI);責任編輯:廖庭儀)

主持歐尼克斯實境互動工作室(OmniXRI):http://omnixri.blogspot.com
Edge AI Taiwan邊緣智能交流區:https://www.facebook.com/groups/edgeaitw/
- 【Arduino UNO Q專欄04】人臉偵測開關燈具 - 2026/06/22
- 【Arduino UNO Q專欄03】板載點矩陣LED應用 - 2026/06/08
- 【Arduino UNO Q專欄02】軟體開發初體驗 - 2026/05/21
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


