作者:曾成訓(CH.Tseng)
本文說明邊緣運算的定義、比較 Intel 的 Neural Compute Stick 一代與二代的效能,並介紹如何建置及使用 PC 端的 compiler 及 edge 端的樹莓派環境。
維基百科對於 Edge computing(邊緣運算)這個名詞的定義是這樣的:
一種分散式運算的架構,將應用程式、數據資料與服務的運算,由網路中心節點,移往網路邏輯上的邊緣節點來處理。邊緣運算將原本完全由中心節點處理大型服務加以分解,切割成更小與更容易管理的部份,分散到邊緣節點去處理。邊緣節點更接近於用戶終端裝置,可以加快資料的處理與傳送速度,減少延遲。在這種架構下,資料的分析與知識的產生,更接近於數據資料的來源,因此更適合處理大數據。
維基的解釋似乎專業又繞口,但邊緣運算其實有個重要特點:事多錢少離家近。事多錢少指的是它們的工作類型單純卻又繁忙,多為過濾資料或進行初步計算分析的工作,但隨時得面對突如其來的資料而不得休息;離家近,則是指邊緣運算多位於最接近資料產生來源的附近,以便就近即時處理。
換而言之,邊緣運算是位於那些最接近資料來源的小型計算中心,主要功能在於收集、儲存、過濾、擷取、簡單的運算,將處理過的資料與雲端系統進行有效率的交換。原本單純的雲端在加入了邊緣計算後,整個系統將變得更加的即時,彈性,且更具效率。
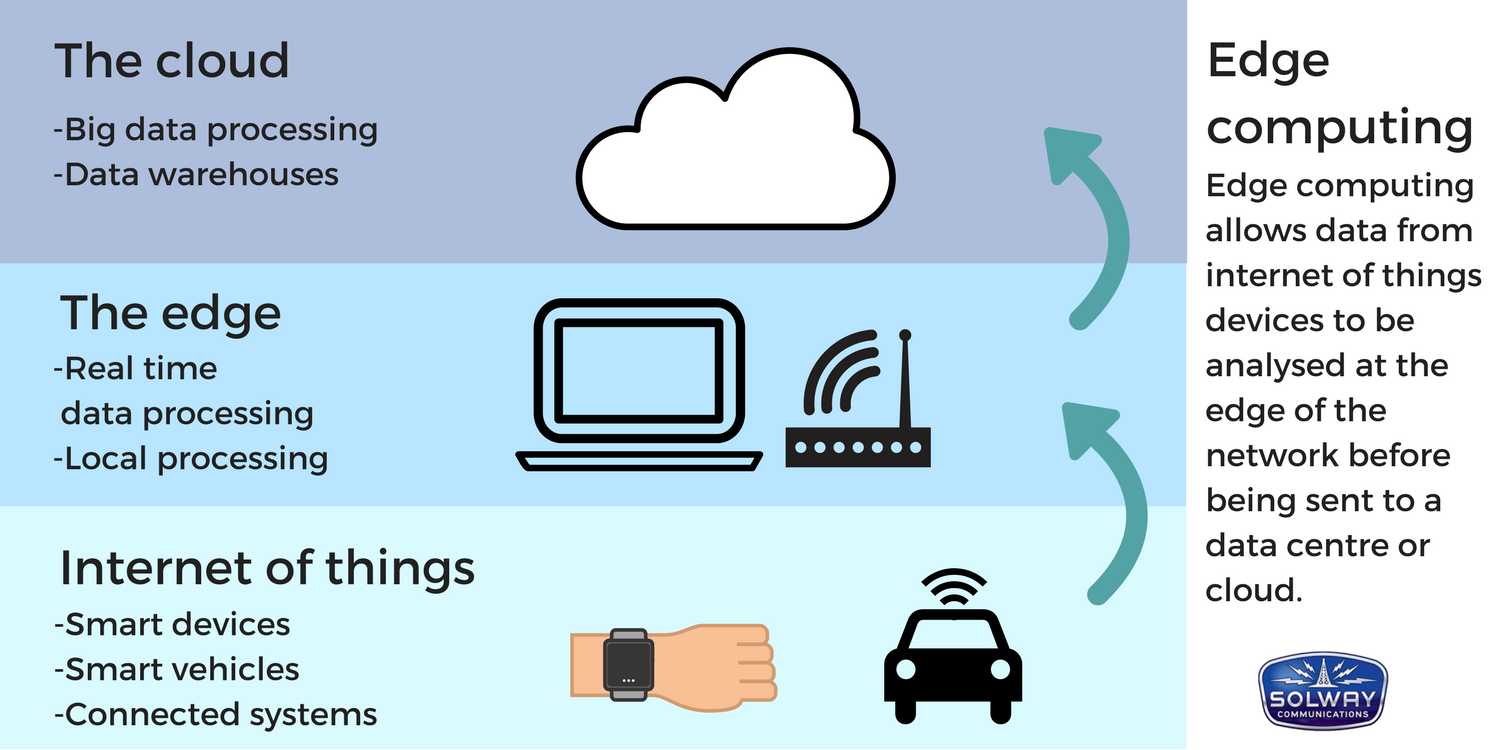
邊緣運算的架構(圖片來源:SOLWAY COMMUNICATIONS)
以樹莓派來說,其硬體配備作為傳統的 IoT 邊緣運算中心是相當適合的,不過隨著 AI 浪潮的興起,巨量的資料以及大量的前處理需求,使得樹莓派這類的微型電腦力有未逮,此時便需要擴充其運算能力才能處理圖片或影像等大量且複雜的維度運算,Intel 的 Neural Compute Stick 便因應此需求而生,號稱每秒運行 1000 億次浮點運算(GFLOPS) 可作為 Deep learning on the Edge。
Intel Neural Compute Stick 介紹
Intel 的 Neural Compute Stick(以下簡稱為 NCS)是 2006 年收購 Movidius 後所推出的產品,第一代 NCS 甫推出便受到高度矚目,被視為 AI edge computing 推理運算的最佳接班人。第二代甫於去(2018)年底推出,其效能如下圖官網所示,執行 Image classification 及 Object Detection 的效能分別較第一代高了五倍與四倍。
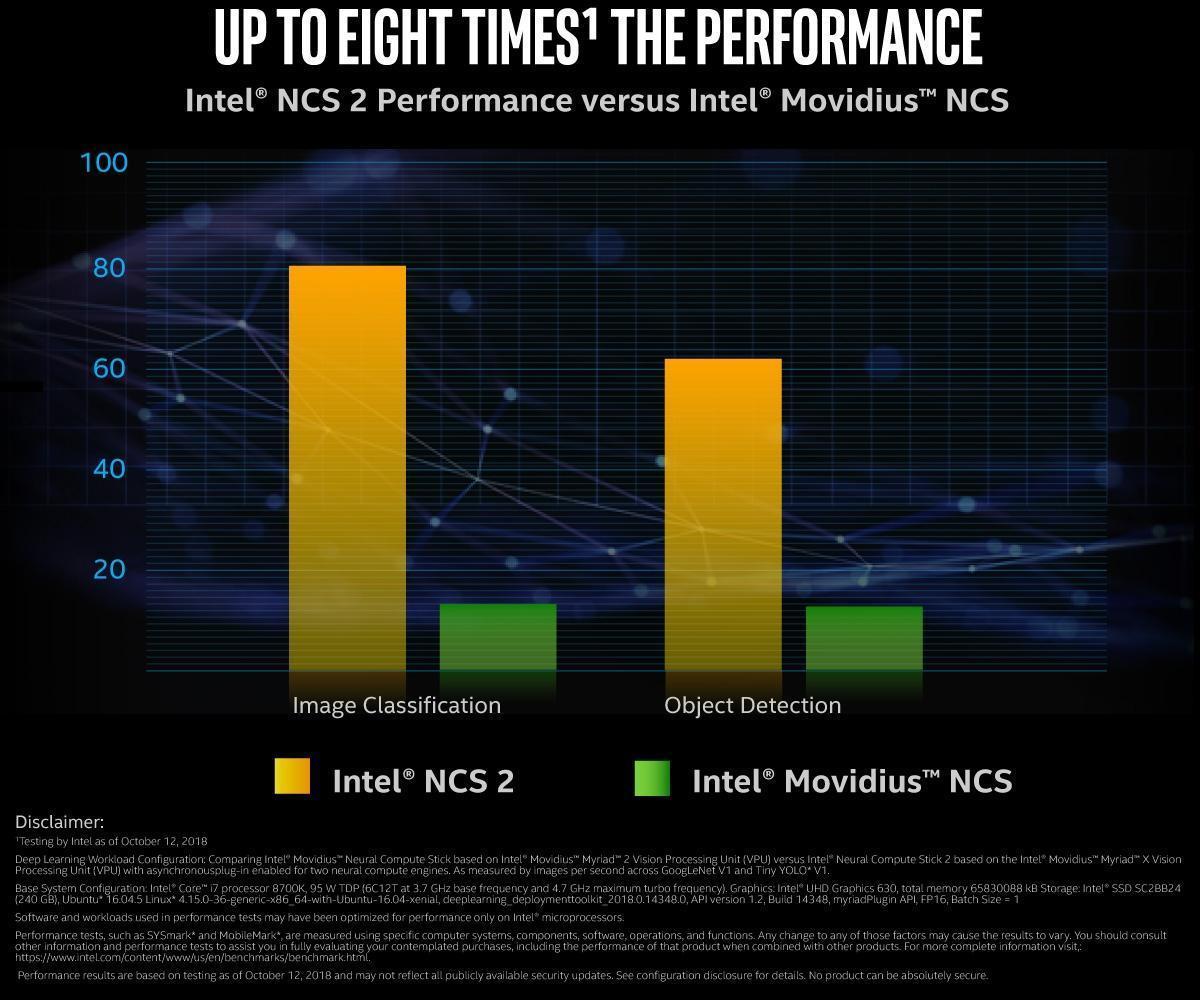
NCS 2 執行 Image classification 及 Object Detection 的效能分別較第一代高了五倍與四倍(圖片來源:Intel)
一代 NCS 與二代
如果你迫不急待的買了甫推出的 Intel Neural Compute Stick 2,興致沖沖地插到樹莓派上準備安裝使用,奉勸你可以暫時先死了這條心,因為新版的二代 NCS 尚不支援樹莓派:
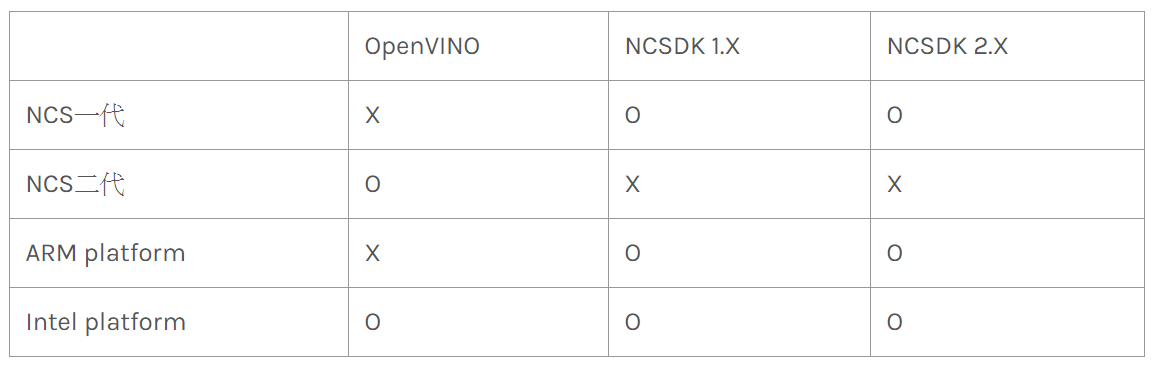
NCS 一代與二代支援系統的比較(圖片來源:曾成訓提供)
第一代的 NCS 搭配的是 NCSDK,而第二代搭配的是 Intel 全新推出的 OpenVINO,第一代 NCS 僅能使用 NCSDK 無法使用最新的 OpenVINO,第二代 NCS 僅僅支援 OpenVINO 不支援 NCSDK,此外新推出的 OpenVINO 也不支援 ARM CPU,因此導致二代 NCS 無法在樹莓派 ARM 處理器上使用。
這是新舊兩代版本的 NCS 外觀,上方為二代,下方為一代。二代突顯了 Intel 的名稱而且己經見不到 Movidius 的名稱;此外,第一代 made in USA,而第二代 made in China。

NCS 一代與二代外觀的差別(圖片來源:曾成訓提供)
由於最新版 NCS 二代並不支援 ARM CPU 的樹莓派(目前僅支援 Intel 系列),故本文仍是以一代 NCS 為範例,示範如何在 PC 端 compiler NCS 所需要的 Graph 檔之後放置於樹莓派上執行。
NCS 的環境可分為兩部分:compiler 端和 edge 端,compiler 多為 PC 主機,將訓練好的 Caffe 或 TensorFlow 模型 compiler 成 NCS 可以執行的 graph 檔;edge 端則為另一台 PC 或更小型的微電腦如樹莓派等,載入 graph 在 NCS 上執行。
Complier 環境建置
負責轉檔的 PC 環境並不需要 Neural Compute Stick,只要安裝 NCSDK(Intel® Movidius™ Neural Compute SDK)即可,如果您想在 stick 上 run 看看各種範例模型,可下載 NC App Zoo(Neural Compute Application Zoo),裏面有 Tensorflow、Caffe、YOLO等數十種模型範例及使用說明。
1. 操作環境:Ubuntu 16.04.10
2. 可選擇下載安裝 1.x 或最新的 2.x 版
- NCSDKNCSDK 1.x版:git clone
- NCSDK 2.x版:git clone -b ncsdk2
3. 安裝:sudo make install
安裝成功後的畫面(圖片來源:曾成訓提供)

也可以在 /usr/local/bin 下找到 mvNCCompile 的執行檔(圖片來源:曾成訓提供)
ps. 如果您在 Ubuntu 安裝時出現如下的 error:
Your current combination of Linux distribution and distribution version is not officially supported!Error on line 42. Will exit
make: *** [Makefile:48: install] Error 1
請修改 ncsdk/install.sh,將此行的 1604
if [ “${OS_DISTRO,,}” = “ubuntu” ] && [ ${OS_VERSION} = 1604 ]; then
修改為你目前使用的版本(忘了請輸入:cat /etc/*release)再 sudo make install 即可。不過,最新的 Ubuntu 18.X 版在安裝時似乎裝不起來,建議用舊的版本。
Edge 端環境建置及設定
首先,下載安裝好最新版的 Raspbian OS,再將 Neural Compute Stick 插到樹莓派後開機,如下圖所示:

(圖片來源:曾成訓提供)
1. 安裝下列套件(您可將下列內容放置於 shell 檔中一次執行比較方便)
安裝套件程式碼
sudo apt-get update
sudo apt-get upgrade –y
sudo apt install python-pip python3-pip
sudo apt-get install -y libusb-1.0-0-dev libprotobuf-dev
sudo apt-get install -y libleveldb-dev libsnappy-dev
sudo apt-get install -y libopencv-dev
sudo apt-get install -y libhdf5-serial-dev protobuf-compiler
sudo apt-get install -y libatlas-base-dev git automake
sudo apt-get install -y byacc lsb-release cmake
sudo apt-get install -y libgflags-dev libgoogle-glog-dev
sudo apt-get install -y liblmdb-dev swig3.0 graphviz
sudo apt-get install -y libxslt-dev libxml2-dev
sudo apt-get install -y gfortran
sudo apt-get install -y python3-dev python-pip python3-pip
sudo apt-get install -y python3-setuptools python3-markdown
sudo apt-get install -y python3-pillow python3-yaml python3-pygraphviz
sudo apt-get install -y python3-h5py python3-nose python3-lxml
sudo apt-get install -y python3-matplotlib python3-numpy
sudo apt-get install -y python3-protobuf python3-dateutil
sudo apt-get install -y python3-skimage python3-scipy
sudo apt-get install -y python3-six python3-networkx
sudo pip3 install opencv_contrib_python
sudo apt-get install -y libatlas-base-dev
sudo apt-get install -y libjasper-dev
sudo apt-get install -y libqtgui4
sudo apt-get install -y libqt4-test
sudo apt-get install -y python3-pyqt5
sudo pip3 install imutils
sudo apt install -y cython
sudo -H pip3 install cython
sudo -H pip3 install numpy
sudo -H pip3 install pillow
sudo pip3 uninstall tensorflow
sudo pip3 install tensorflow-1.7.0-cp35-none-linux_armv7l.whl
rm tensorflow-1.7.0-cp35-none-linux_armv7l.whl
2. 確認 OpenCV 及 Tensorflow 的安裝是否完成
python3 >>> import cv2 >>> import tensorflow
3. 加大 swap size
sudo nano /etc/dphys-swapfile
將 CONF_SWAPSIZE 由預設的 100(MB)增加為 1024(MB)以上,接著重啟 dphys-swapfile
service:
sudo /etc/init.d/dphys-swapfile restart
4. cd ~; git clone -b ncsdk2 http://github.com/Movidius/ncsdk
cd ncsdk/
nano ncsdk.conf → 將 #MAKE_NJOBS=1 前方的 mark # 移除
sudo make install
之後,會看到如下方的訊息,表示安裝完成
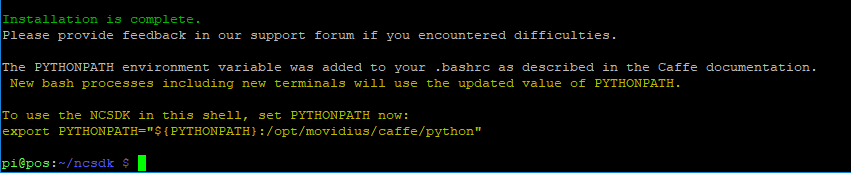
(圖片來源:曾成訓提供)
修改 sudo nano /etc/dphys-swapfile
將 CONF_SWAPSIZE 還原為預設的 100(MB)再重啟 dphys-swapfile service:
sudo /etc/init.d/dphys-swapfile restart
5. 可選擇下載安裝 1.x 或最新的 2.x 版 NCSDK
- NCSDK 1.x 版:git clone
- NCSDK 2.x 版:git clone -b ncsdk2
6. 安裝:sudo make install
這個 install 的過程在樹莓派上相當久,約需要 2-3 小時
7. 測試是否 work
cd ~/ncsdk/examples/apps/hello_ncs_py/ make run
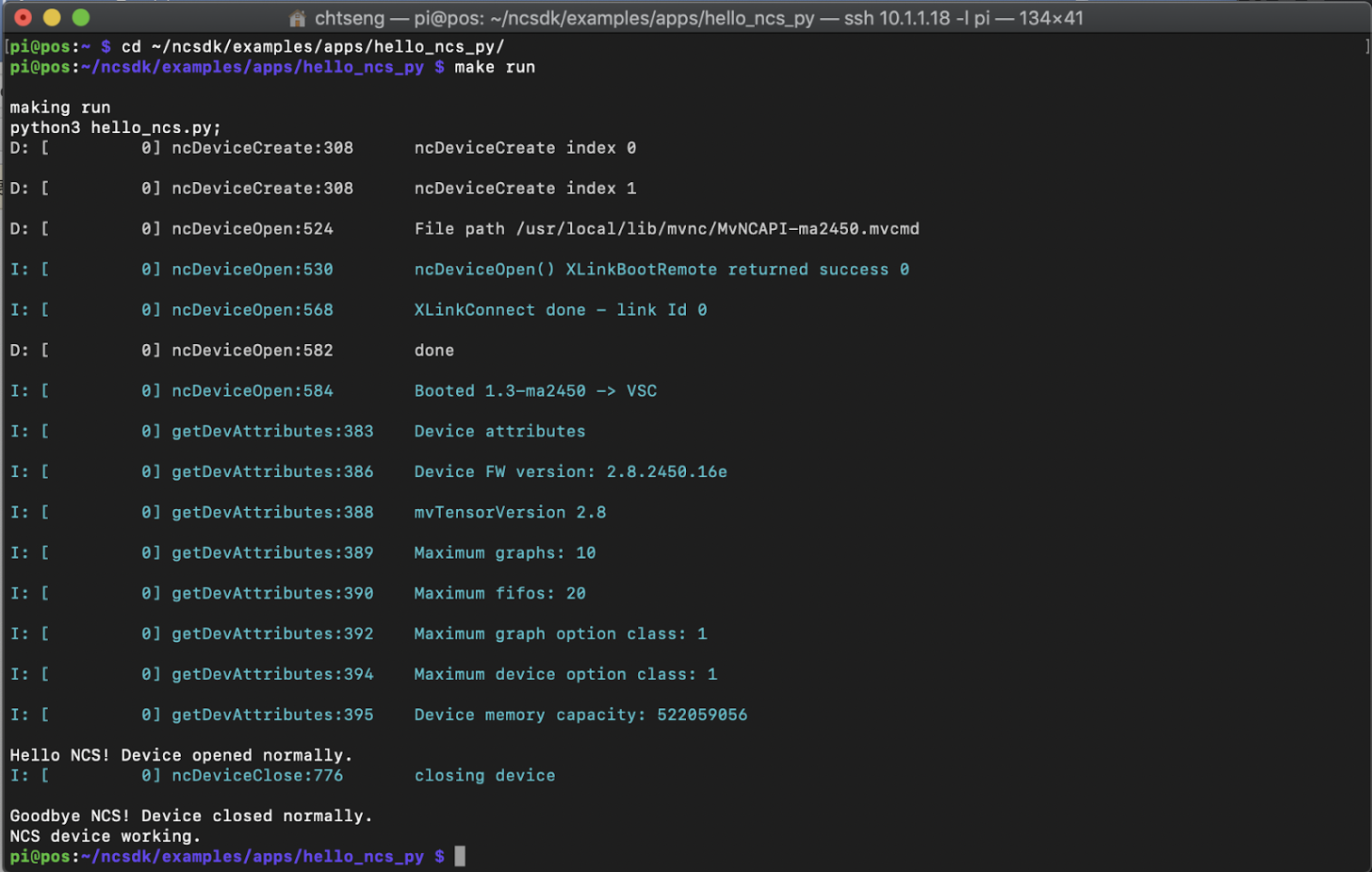
測試是否成功(圖片來源:曾成訓提供)
各種 model 使用範例
1. NCSDK
NCSDK 2.X 的 examples 目錄下提供了以下的範例:
apps/ → 基本的測試程式hello_ncs_cpp及hello_ncs_py
caffe/ → ALexNet、GoogLeNet、SquuzeNet
tensorflow/ → inception_v1、inception_v3
這幾個 example 經測試可直接在樹莓派上 complier 出 graph 檔並執行,並不需要另外在 PC 上 compiler。例如下方為樹莓派上 compiler 及執行 Inception V3 範例。
(make run)
參考範例
pi@pos:~/ncsdk/examples/tensorflow/inception_v3 $ make run test -f output/inception-v3.meta || ((wget http://download.tensorflow.org/models/inception_v3_2016_08_28.tar.gz && tar zxf inception_v3_2016_08_28.tar.gz && rm inception_v3_2016_08_28.tar.gz) && ./inception-v3.py)
–2018-12-22 16:00:07– http://download.tensorflow.org/models/inception_v3_2016_08_28.tar.gz 正在查找主機 download.tensorflow.org (download.tensorflow.org)… 172.217.160.112, 2404:6800:4012:1::2010
正在連接 download.tensorflow.org (download.tensorflow.org)|172.217.160.112|:80… 連上了。
已送出 HTTP 要求,正在等候回應… 200 OK
長度: 100885009 (96M) [application/x-tar]
Saving to: ‘inception_v3_2016_08_28.tar.gz’
inception_v3_2016_0 100%[===================>] 96.21M 813KB/s in 6m 21s
2018-12-22 16:06:28 (259 KB/s) – ‘inception_v3_2016_08_28.tar.gz’ saved [100885009/100885009]
/usr/lib/python3.5/importlib/_bootstrap.py:222: RuntimeWarning: compiletime version 3.4 of module ‘tensorflow.python.framework.fast_tensor_util’ does not match runtime version 3.5
return f(*args, **kwds)
/usr/lib/python3.5/importlib/_bootstrap.py:222: RuntimeWarning: builtins.type size changed, may indicate binary incompatibility. Expected 432, got 412
return f(*args, **kwds)
/usr/lib/python3/dist-packages/h5py/__init__.py:34: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.
from ._conv import register_converters as _register_converters
test -f graph || mvNCCompile –new-parser -s 4 output/inception-v3.meta -in=input -on=InceptionV3/Predictions/Reshape_1
/usr/lib/python3/dist-packages/scipy/_lib/_numpy_compat.py:10: DeprecationWarning: Importing from numpy.testing.nosetester is deprecated, import from numpy.testing instead.
from numpy.testing.nosetester import import_nose
/usr/lib/python3/dist-packages/scipy/stats/morestats.py:16: DeprecationWarning: Importing from numpy.testing.decorators is deprecated, import from numpy.testing instead.
from numpy.testing.decorators import setastest
/usr/lib/python3.5/importlib/_bootstrap.py:222: RuntimeWarning: compiletime version 3.4 of module ‘tensorflow.python.framework.fast_tensor_util’ does not match runtime version 3.5
return f(*args, **kwds)
/usr/lib/python3.5/importlib/_bootstrap.py:222: RuntimeWarning: builtins.type size changed, may indicate binary incompatibility. Expected 432, got 412
return f(*args, **kwds)
/usr/local/bin/ncsdk/Controllers/Parsers/TensorFlowParser/Convolution.py:46: SyntaxWarning: assertion is always true, perhaps remove parentheses?
assert(False, “Layer type not supported by Convolution: ” + obj.type)
/usr/local/bin/ncsdk/Controllers/Parsers/Phases.py:322: SyntaxWarning: assertion is always true, perhaps remove parentheses?
assert(len(pred) == 1, “Slice not supported to have >1 predecessors”)
mvNCCompile v02.00, Copyright @ Intel Corporation 2017
****** Info: No Weights provided. inferred path: output/inception-v3.data-00000-of-00001******
output/inception-v3.meta
output tensor shape (1, 1, 1, 1001)
Fusing DeptwiseConv + Pointwise Convolution into plain Convolution
Fusing Add and Batch after Convolution
Fusing Pad and Convolution2D
Fusing BatchNorm and Scale after Convolution
Replacing BN with Bias&Scale
Fusing Permute and Flatten
Fusing Eltwise and Relu
Eliminate layers that have been parsed as NoOp
Evaluating input and weigths for each hw layer
————————————–
———————-
———————-
# Network Input tensors [‘input:0#327’]
# Network Output tensors [‘InceptionV3/Predictions/Reshape_1:0#653’]
Blob generated
./run.py Number of categories: 1001
Start download to NCS…
/usr/local/lib/python3.5/dist-packages/mvnc/mvncapi.py:416: DeprecationWarning: The binary mode of fromstring is deprecated, as it behaves surprisingly on unicode inputs. Use frombuffer instead
tensor = numpy.fromstring(tensor.raw, dtype=numpy.float32)
*******************************************************************************
inception-v3 on NCS
*******************************************************************************
547 electric guitar 0.98828125
403 acoustic guitar 0.007789612
715 pick, plectrum, plectron 0.0015392303
421 banjo 0.00095939636
820 stage 0.00069093704
*******************************************************************************
Finished
2. NCAPPZOO
- NCSDK V1:git clone
- NCSDK V2:git clone -b ncsdk2
不像 NCSDK 的 examples,NCAPPZOO 的範例大部份須先在 PC 端 compiler,再將檔案 copy 回樹莓派上執行。如果不確定,您可以在樹莓派各 model 目錄下先執行 make run 試看看。
3. AgeNet
以 AgeNet 為例,該 model 無法直接在樹莓派 compiler,必須在 PC 端 compiler 之後,再將需要的檔案放置於樹莓派端來執行。
- PC端:
a. cd ~/ncappzoo/caffe/AgeNet
b. sudo make
c. 將這兩個檔案:
~/ncappzoo/caffe/AgeNet/graph
~/ncappzoo/data/age_gender/ilsvrc_2012_mean.npy
copy 到樹莓派的~/ncappzoo/caffe/AgeNet/
- 樹莓派端:
a. cd ~/ncappzoo/caffe/AgeNet
b. 修改 run.py,修改 ilsvrc_2012_mean.npy 的 path 如下:
ilsvrc_mean = numpy.load(EXAMPLES_BASE_DIR+’ilsvrc_2012_mean.npy’).mean(1).mean(1)
c. python3 run.py 執行看看
程式會自動下載此圖檔,並預測其年齡。

——- predictions ——–
the age range is 25-32 with confidence of 99.9%
4. Tiny YOLO V2
Tiny YOLO V2 為 NCSDK V2 新增支援的模型,同樣無法直接在樹莓派 compiler,請依照下方步驟來執行。
- PC端:
a. cd ~/ncappzoo/tensorflow/tony_yolo_v2
b. sudo make
c. 將目錄下所產生的 tiny_yolo_v2.graph 拷貝到樹莓派相同路徑下(~/ncappzoo/tensorflow/tony_yolo_v2)。
- 樹莓派端:
a. cd ~/ncappzoo/tensorflow/tony_yolo_v2
b. python3 run.py

chair 252.95474672600892 233.27657267046558 560.7038196196356 661.3331978559199(圖片來源:曾成訓提供)
5. Facenet
先在 PC 端 compiler 產生 graph 檔之後,放置於樹莓派端,就可以在樹莓派上體驗快速的人臉辨識了!NCSDK 所收錄的這個 model 改自 https://github.com/davidsandberg/facenet,作者使用 Inception ResNet v1 作為 Facenet 提取特徵的模型,並提供了兩種 Pre-trained models 分別用 CASIA-WebFace 及 VGGFace2 datasets 所訓練,不過在您下 make 指令時自動下載的 pre-trained model 版本是較舊的 20170512-110547.zip。
- PC端:
a. cd ~/ncappzoo/tensorflow/facenet
b. sudo make
c. 將目錄下所產生的 facenet_celeb_ncs.graph 拷貝到樹莓派相同路徑下(~/ncappzoo/tensorflow/facenet)
- 樹莓派端:
a. cd ~/ncappzoo/tensorflow/facenet
b. python3 run.py

(圖片來源:曾成訓提供)

(圖片來源:曾成訓提供)

- 【模型訓練】訓練馬賽克消除器 - 2020/04/27
- 【AI模型訓練】真假分不清!訓練假臉產生器 - 2020/04/13
- 【AI防疫DIY】臉部辨識+口罩偵測+紅外線測溫 - 2020/03/23
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!



2019/02/01
若要用樹梅派,請問 NCS一代可加速 yolo-v3 tiny嗎?
2019/02/19
Alan您好:
可以加入我們MakerPRO的社群,在裡頭,有許多厲害的Maker們可以為您解答與討論
謝謝您的提問
MakerPRO 編輯部