2026 AI熱什麼?對開發者來說,AI x Robotics肯定是關注的重點!
當AI遇上機器人,「語言理解」與「認知推理」將成為下一代智慧機器人的核心能力,如何讓讓機器人真正理解世界、做出穩定的動作決策,並在現實環境中流暢完成一個又一個差異化任務,包括「智能雙臂協作」和「人形機器人的泛化能力」,會是2026年投入AI機器人領域者重點投入的題目。
在這篇特寫裡,我們將深入四個無法錯過的最新模型:ACT、RDT-1B和π₀。它們分別代表了模仿學習、擴散式操作模型、視覺-語言-行動融合策略等最前瞻技術,將牽動著通用機器人能否真正落地走入生活的關鍵突破。
ACT:讓機器人不再只「看一步」,而是「看一整段」
在機器人操作的世界裡,「下一步動作預測」一向是模仿學習的核心。然而,真實世界充滿摩擦、誤差、視覺遮擋、物體位置差異等挑戰。早期行為克隆(Behavior Cloning)的模式大多只預測下一個瞬間的動作,但這種短視近利的方式往往讓機器人越做越偏,錯誤會像滾雪球般累積,最後卡在一個人類根本不會犯的尷尬位置。
ACT(Action Chunking with Transformers)則像把機器人的「注意力跨度」瞬間拉長。它一次預測的不是一個動作,而是一「段」動作,就像人類在打開瓶蓋時,不會思考「手指往哪移 0.1 公分」,而是以幾秒為單位進行連貫的策略。ACT 便是透過動作分塊,讓機器人也擁有這種「段落式決策」的能力。
更重要的是,ACT 運用了 Transformer 作為主骨幹,強化了對時間序列的理解;再加上 CVAE(Conditional VAE)結構,它得以從觀察和潛在風格變量中合成一段動作,既保有多樣性,又能在推論階段設為零,獲得一致且平滑的動作。研究團隊更進一步用「時間整合」技巧,將多個重疊的動作分塊做加權平均,使動作軌跡穩定到幾乎能以肉眼看出「人類般的流暢度」。
ACT 的威力,讓機器人僅需少量數據就能掌握精細操作:開杯蓋、插電池、抓取半透明物體等任務的成功率都大幅提升。它讓模仿學習不再是「一步一步猜」,而是「提前看懂整個動作段落」。
RDT-1B:1.2B 參數的雙臂協作巨獸
如果說 ACT 是讓機器人動作更流暢,那 RDT-1B(Robotics Diffusion Transformer)就是在教機器人跳一場需要「兩隻手完美配合」的舞。
雙臂協作是機器人研究裡最難的課題之一。兩隻手臂的控制空間高維到近乎爆炸,而且同一個任務可以有上千種合理的操作方式,動作呈現高度多模態分佈。若以傳統 MSE 回歸的方式學習,模型往往被逼成「折衷姿勢」,做出看似平均、實則完全不實用的動作。
RDT-1B 的核心,在於採用 Diffusion Transformer。它不試圖找到某個「最佳解」,而是從噪聲一路去噪,生成多模態的可能動作,能以更接近人類策略的方式探索操作空間。這種生成式方式對雙臂任務尤其關鍵,因為兩隻手必須彼此協調,在複雜幾何結構間移動,並同步完成抓取、按壓、旋轉等任務。

RDT-1B技術架構(source)
最具突破性的,是它提出的「物理可解釋的統一動作空間」。研究團隊蒐集了跨機器人的大量資料,將不同機器人控制方式(關節命令、末端執行器位置、力控制等)統一映射到一個具有真實力學語意的空間裡。也因此,RDT-1B 能夠跨越機器人硬體差異進行大規模預訓練。
RDT-1B 在超過 100 萬筆資料集上預訓練後,再以 Mobile ALOHA 雙臂機器人的 6,000 筆資料微調,展現驚人的泛化能力。它能零樣本學習陌生物體,也能用極少數示範完成新動作,甚至具備理解語言指令的能力。
對於大型協作式機器人而言,RDT-1B 為「雙臂動作生成」提供了新的基礎模型級方案。
π₀:當網路知識遇上即時流匹配,機器人終於懂人話
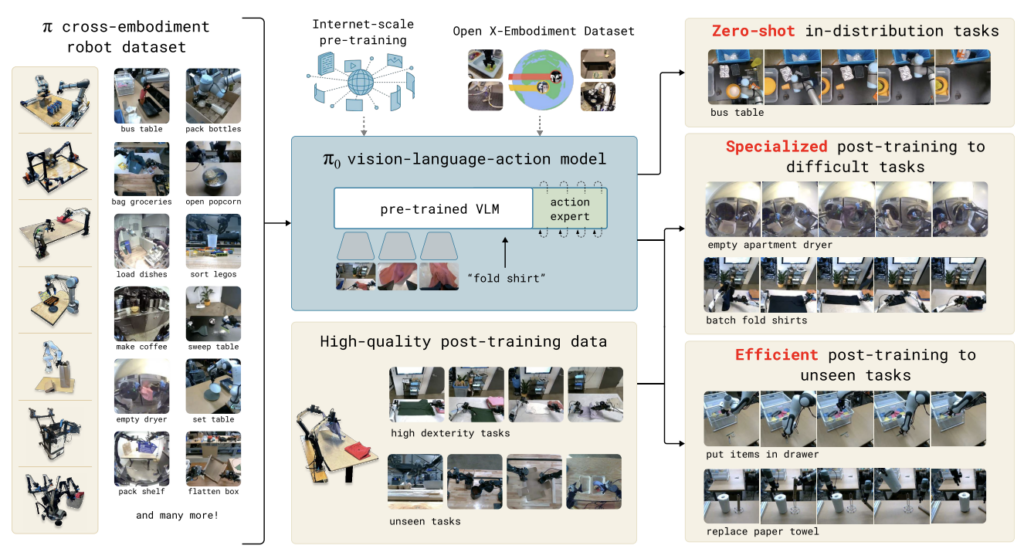
如果說前兩個模型聚焦在動作面,那 π₀(Pi-Zero)就是把機器人推向一個更接近人類的境界:它能理解你說的話、看懂情境、並生成實際動作。
π₀ 以 VLM(Vision-Language Model)作為語義骨幹,像是接上了 PaliGemma 這類經過網際網路訓練的大型模型。這代表它不僅能看懂圖像內容,也能讀懂指令的意圖,甚至具備自然語言中隱含的世界知識。於是,如果你跟機器人說「把桌上紅色杯子移到微波爐旁邊」,π₀ 不僅能辨識杯子與微波爐,也能理解「旁邊」的語義。
π0技術架構(source)
但真正關鍵的,是 π₀ 使用 Flow Matching Transformer。流匹配(Flow Matching)不像擴散模型那樣需要繁重的多步去噪,而是學習一個從基線分佈通往目標動作分佈的連續流場。這使得 π₀ 能夠以接近 50Hz 的頻率生成動作,滿足真實機器人的即時性要求。
π₀ 的另一大亮點,是它在多機器人、多任務的異質資料集上進行預訓練,因此具備跨肢體泛化能力。無論是移動底盤機器人、單臂手臂,甚至複雜的雙臂系統,它都能提取共通的操作原理,並將語言、視覺、動作的三者衍生關係統一建模。
為了提升穩定性,π₀ 甚至刻意學習「失誤場景」並建立恢復策略,讓機器人能從錯誤中重新回到正軌。這種能力對真實世界部署至關重要:人類示範永遠不如理想化的實驗室資料乾淨,而 π₀ 正是為此而設計的。
結語
剖析 ACT、RDT-1B和π₀的發展,一個共同的核心事實逐漸清晰:機器人的智能正在從「控制」升級到「理解」與「生成」。ACT 讓動作預測變得長視、連貫、具可塑性;RDT-1B 把雙臂操作推向生成式的多模態巨觀;π₀ 將語言、視覺與動作融為一體,使機器人真正理解人類意圖。
這些模型不只是技術突破,而是為「通用機器人」鋪設基礎的幾根樑柱。未來的機器人或許不再需要繁雜的手工調參、特化資料集或精密標定,而是能像人類一樣,透過整合感知、語言和動作,自主完成各種真實世界的任務。
(責任編輯:歐敏銓)

- Nordic以超低功耗邊緣AI與無線連線技術引領物聯網創新 - 2026/06/16
- AI伺服器記憶體需求持續上揚 LPDRAM供給缺口難弭平 - 2026/06/15
- 助力營建業數位轉型 耐能攜夥伴打造Edge AI工地戰情中樞 - 2026/06/12
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


