作者:Mingyu Kim,Intel高級資深工程師;武卓,AI 軟體佈道師
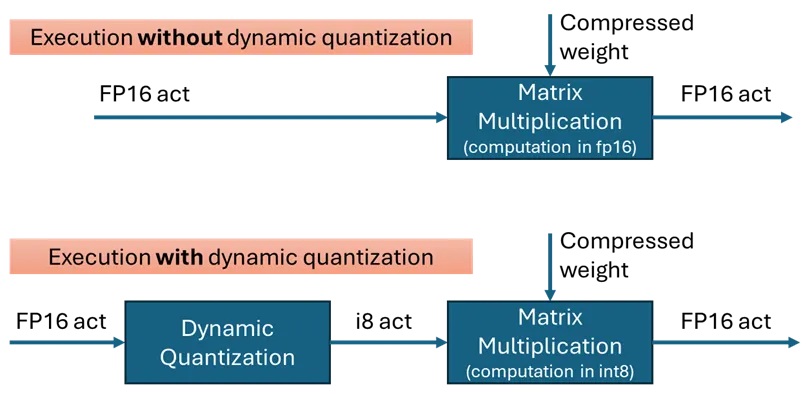
動態量化(dynamic quantization)是一種強大的最佳化技術,能顯著提升Transformer模型在英特爾(Intel) GPU的性能,包括搭載於Lunar Lake、Arrow Lake處理器,配備XMX引擎的硬體,以及Alchemist、Battlemage等系列獨立顯卡。
本文將探討:
- 什麼是動態量化,以及它在OpenVINO 2025.2中如何於GPU上運作
- 預設行為和配置選項
- 性能與精度的權衡
- 啟用或停用動態量化的程式碼範例
- 如何驗證其運作情況
備註:本文重點討論配備XMX引擎的英特爾GPU;無XMX的CPU (如Meteor Lake)或GPU上的行為可能不同。
什麼是動態量化?
動態量化透過在矩陣乘法(MatMul)運算前,將輸入啟動值(通常是fp16)即時轉換為int8來降低運算成本;當模型權重已量化為int4或int8時,這種方法特別有效。
在OpenVINO 2025.2中,量化沿著嵌入軸(embedding axis,最內層軸)進行。輸入張量會被分組,每個分組的最小/最大值用於確定量化比例(scale)和零點(zero-point)。
OpenVINO 2025.2預設行為
在配備XMX引擎的GPU上,OpenVINO 2025.2預設啟用動態量化。
- 逐token量化 (每個token一個scale)是預設模式,以最大化運算效率。
- 如果模型包含適當的MatMul 層,OpenVINO會自動插入dynamic_quantize 操作(輸入過短除外)。
⛔ 何時會被停用?
動態量化會根據輸入token長度,有條件地被應用:
- ✅ 啟用:token長度 > 64
- ❌ 停用:token長度 ≤ 64
即使是長提示詞,在生成階段(第二個token開始)也可能因 KV緩衝記憶體導致列大小(row size)減少而跳過量化。
何時啟用/停用動態量化
動態量化在以下情況中最有效:
- 長輸入序列處理(特別是提示詞 > 512 tokens的大語言模型),性能提升可達數十個百分點。
- 矩陣乘法成為推論瓶頸,如果模型的推論時間主要耗費在MatMul,動態量化可大幅加速運算。
若是以下情況效果可能不明顯:
- 非常長的提示詞,但主要耗時在其他運算,如注意力(attention)層。
- 短輸入(≤ 64 tokens)的動態量化預設為停用,運算節省有限且記憶體I/O佔據大宗。
精度考量
OpenVINO的動態量化通常能保持較高精度,但在部分模型與應用中可能有輕微下降。
降低精度損失的方法:
- 使用較小的分組大小(如 256),可提升精度但略微犧牲性能。
- 對精度極為敏感的任務,可直接停用動態量化。
如何啟用/停用動態量化
✅ 啟用動態量化
動態量化預設為啟用,但也可透過runtime的屬性自訂:
ov::Core core;
auto model = core.read_model("model.xml");
ov::AnyMap config = {
{"dynamic_quantization_group_size", 256}, // Custom group size
};
auto compiled_model = core.compile_model(model, "GPU", config);
❌ 停用動態量化
要完全停用動態量化:
ov::AnyMap config = {
{"dynamic_quantization_group_size", 0} // Turn off quantization
};
auto compiled_model = core.compile_model(model, "GPU", config);
如何驗證動態量化是否啟用
可以透過以下兩種方法來檢查OpenVINO是否啟用動態量化:
1. 執行圖(Execution Graph)
使用benchmark_app並開啟執行圖匯出,查找是否存在dynamic_quantize節點。(參考Benchmark tool docs)
2. OpenCL 攔截層(Intercept Layer)
使用OpenCL intercept layer追蹤實際的GPU kernel呼叫日誌或 device_performance_timing,若執行了會看到 dynamic_quantize。
運作原理
動態量化啟用時,OpenVINO會在圖形轉換階段在MatMul之前插入dynamic_quantize 節點,並在運作時根據以下條件執行:
- token 長度 > 閾值 → 執行量化
- token 長度 ≤ 閾值 → 跳過量化
若透過配置停用,就不會插入該節點。
實測範例
在Intel Battlemage B580 GPU (具備 XMX引擎)上執行 Qwen3–8B INT4 模型,使用prompt_lookup_decoding_lm.py 腳本:
- 在短提示詞(如「What is OpenVINO?」,速度提升不明顯
- 長提示詞(4K token的科幻小說段落):首token延遲降低約10~20%
雖然以肉眼來看差異不大,但這展現了框架對大型Transformer模型的智慧runtime最佳化能力與高效率的GPU執行路徑。
小結
OpenVINO 2025.2中的動態量化是一種簡單卻高效率的方法,可自動加速Intel GPU上的Transformer推論;在處理長提示詞或對性能要求極高的模型時,值得充分利用此功能。
(參考原文:Accelerate LLMs on Intel® GPUs: A Practical Guide to Dynamic Quantization)

- AI Agent時代來臨:看邊緣AI如何成為驅動智慧機器人的關鍵 - 2025/11/28
- OpenVINO×ExecuTorch:解鎖英特爾架構AI PC模型推論效能新境界 - 2025/11/21
- 讓生成式AI應用在Intel架構系統本地端高效率運作的訣竅 - 2025/10/16
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


