作者:Liliya Wu,Arm AI生態系推廣工程師
今日全世界的邊緣與終端人工智慧(AI)出現爆炸性成長,為了因應這波邊緣與終端AI裝置浪潮,Arm特地設計了microNPU 這個全新等級的機器學習(ML)處理器,為面積受限的嵌入式與物聯網裝置加速ML推論。
有了Arm Ethos系列的不同等級microNPU,你可以輕鬆地以Arm Cortex與Arm Neoverse架構為基礎,在各種嵌入式裝置與系統中打造低成本、高效率的AI解決方案。Ethos-U提供可擴充的不同性能等級與記憶體介面,可整合低功耗Cortex-M系統單晶片,以及高性能的Arm Cortex-A、Cortex-R與Arm Neoverse架構系統單晶片。

圖1:Arm Ethos-U系列microNPU晶片架構。
Vela編譯器概述
要在Ethos-U上部署神經網路(NN)模型,第一步須使用Vela來編譯你已備妥的模型。Vela是一種開源Python工具,可以將神經網路模型最佳化為能在內含Ethos-U NPU的嵌入式系統上執行之特定版本。
完成編譯之後,此最佳化模型將包含TensorFlow Lite客製運算子(operator),以透過Ethos-U microNPU支援模型內可以加速的部分;模型中無法加速的部份則維持不變,將利用適當的核心在CPU上執行。
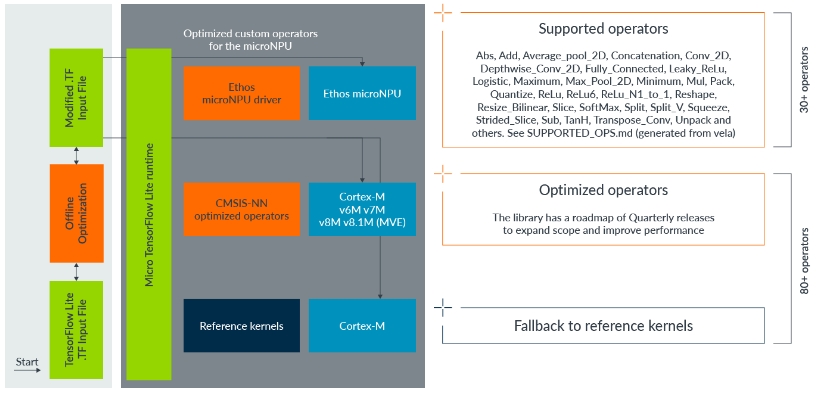
圖2:運算子工作流程。
我們持續增加Vela支援的運算子;若要檢視Vela目前支援的運算子清單,請在安裝好Vela後,於電腦的CLI視窗(如Windows的cmd或Linux終端機)輸入下列指令以產出報告,該報告會存在你目前的工作目錄下,檔案名稱為「SUPPORT_OPS.md」。
vela --supported-ops-report
然而,你可能會發現這份報告中的某些運算子有侷限性;倘若限制條件未符合,該運算子就會排程到CPU上運作。請注意,在此情況下並不代表整個模型無法執行,只是你的網路有一部份無法在Ethos-U上執行,那些未獲得支援的部份會改在CPU上運作。
可使用以下指令檢查模型中有哪些運算子會退回到CPU上:
vela network.tflite --show-cpu-operations
同屬工作流程
要在Arm Ethos-U microNPU上部署你的NN模型,Vela是第一個、也是不可或缺的步驟。在這篇文章中我們會展示如何使用Vela編譯你的模型之同屬工作流程。
Vela可以在Linux、Mac OS與微軟Windows 10作業系統上執行,你可以藉由下列指令,從PyPi社群輕鬆完成安裝;你也可以取得原始碼,並從Arm ML平台發現更多進階的安裝方法。
pip3 install ethos-u-vela
請注意,在開始安裝前,你的電腦應當符合「Prerequisites」項目所列出的先決條件。有關版本的細節,你可以利用下列指令進行檢視。
vela --version
以下是同屬工作流程圖。
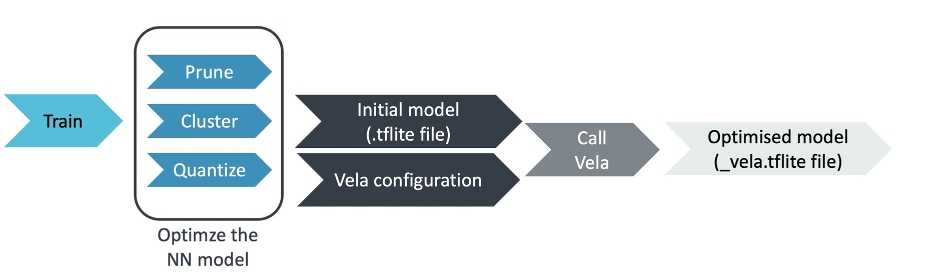
圖3:同屬工作流程。
1.準備你的NN模型
為了運用Ethos-U microNPU進行加速,你的網路運算子必須量化至8位元或16位元(帶正負號)。請在指令行輸入.tflite檔案來執行Vela,它包含你已最佳化的神經網路。
你可以透過以下兩種方式來準備.tflite初始模型:
- 若你已有自己的預訓練模型,很多現成的工具可以幫你取得已徹底量化的模型,如TensorFlow模型最佳化工具套件。你也可以在這裡追蹤我們的最佳化部落格,來最佳化你的客製NN模型。
- 若你沒有自己的模型,根據你特定的ML應用,Arm ML Zoo與TensorFlow Hub可以用.tflite格式提供你各種ML模型;你可以下載並把它們當成是自己的模型直接使用。
2. 準備你的Vela組態檔案
對Ethos-U系列而言,Vela是種可以高度客製化的離線編譯工具,你可以重寫Vela的組態檔案,輕鬆客製化Ethos-U嵌入式系統的各種屬性,如記憶體延遲與頻寬,但我們極力建議你把它客製化到儘可能接近你計劃部署之NN模型的實際硬體系統。
Vela的組態檔案格式是Python ConfigParser .ini檔案格式。.ini檔案主要包含兩個區段:系統組態與記憶體模式,用以辨識組態,以及用來指定屬性的鍵值配對(value pair)選項。請留意,所有的區段與鍵/值對都有大小寫之分。
同樣的,以下有兩種方式可以協助你準備你的Vela組態檔案。
- 使用預設的Vela組態檔案:我們提供一個預設的「vela.ini」檔案,以描述某些同屬級別的嵌入式裝置與系統。你可以直接把它當成你的vela組態檔使用;在下列表格中看到我們目前提供的預設「vela.ini」檔案的選擇。更多有關每項選擇的詳細屬性資訊,可以檢視vela.ini檔案。

- 使用客製Vela組態檔案:倘若目前vela版本中的既有同屬組態選擇無法滿足你的硬體系統需求,你可以編寫自己的客製Vela組態檔案。同時,使用下方指令來指定你客製Vela組態檔案的路徑。請參考「Configuration File」中的詳細編寫指示來完成你的客製Vela組態檔案。設定時應該要與程式化區域組態暫存器的驅動程式保持一致,以便控制模型資料存取該使用哪個AXI埠(詳情請參考Ethos-U程式設計人員模型)
vela network.tflite --config your_vela_configuration_file.ini
3.配置與執行
Vela提供使用者許多命令列介面(CLI)以配置每個特定的呼叫程序;你可以在「Command Line Interface」中找到更完整的說明。
在眾多參數中,除了必要的「Network」參數,我們必需正確地設定下列關鍵的參數選項,以便反映真實的硬體平台組態;這一點相當重要,若你沒有另外指定這些參數,它會以內部的預設值執行,而那些預設值每個版本都不盡相同。請參閱每個版本的「Vela選項」文件,了解每一個參數的預設值。

目前我們提供下列選擇,供你設定硬體加速器組態與最佳化策略時使用。

以下是配置與呼叫的實例:
vela network.tflite \
–-output-dir ./output \
--accelerator-config ethos-u55-256 \
--optimise Performance \
--config vela.ini \
--system-config Ethos-U55_High_End_Embedded \
--memory-mode Shared_Sram
在使用上述指令呼叫前面看到的Vela之後,你將在你指定的目錄「./output」取得最佳化的輸出模型,輸出的檔案為_vela.tflite格式。在此同時,你的電腦主控視窗會出現一個Vela編譯程序日誌。
有時日誌會出現一些警訊,請仔細檢視,它們會說明編譯器為了打造最佳化網路所做出的決定,例如要把哪些運算子呼叫回CPU。
現在就來嘗試!
作為你在Ethos-U上部署NN模型的第一步,Vela編譯器本身除了是開放源碼,且容易上手。現在就開始試用,來體驗Arm Ethos-U如何為嵌入式系統帶來大幅躍升的機器學習能力吧!
(參考原文:Vela Compiler: The first step to deploy your NN model on the Arm Ethos-U microNPU;中文版校閱者為Arm主任應用工程師林宜均;責編:Judith Cheng)
- 【Arm的AI世界】按步驟學習在Arm Ethos-U85上部署PaddlePaddle模型 - 2026/07/08
- 【Arm的AI世界】打造車用裝置端多模態助理 - 2026/06/16
- 【Arm的AI世界】運算平台開發者必看:無須硬體也能進行OpenBMC+UEFI模擬與驗證! - 2026/04/09
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


