作者:歐敏銓
想像一下,如果有一天AI也有自己的「心智世界」它將不只是被動地、規矩的回應這個世界,而是能提前構思、預判下一個動作、擁有「趨吉避凶」的直覺本能!
喜歡用聽的?可收聽本文Podcast的精采對話喔(by GenAI):
2025年,AI領域正上演一場劇烈的典範轉移。NVIDIA執行長黃仁勳在GTC與CES舞台上多次強調:AI的發展即將從感知AI(Perception AI)、生成式AI(Generative AI)、代理AI(Agentic AI),走入物理AI(Physical AI)的時代,也就是一個AI能感知、理解並與現實物理世界互動的境界,讓機器人及自駕車等裝置能「行於所當行,止於所不可不止。」
這是一場讓人工智慧真正走出虛擬、跨入現實世界的革命。不過,要順利過渡到物理AI的境界,AI內部需建立起對現實物理世界的模擬能力,也就是一套「世界模型」(World Model),才能讓機器像人類一樣具備思考、預測、規劃與創造能力。
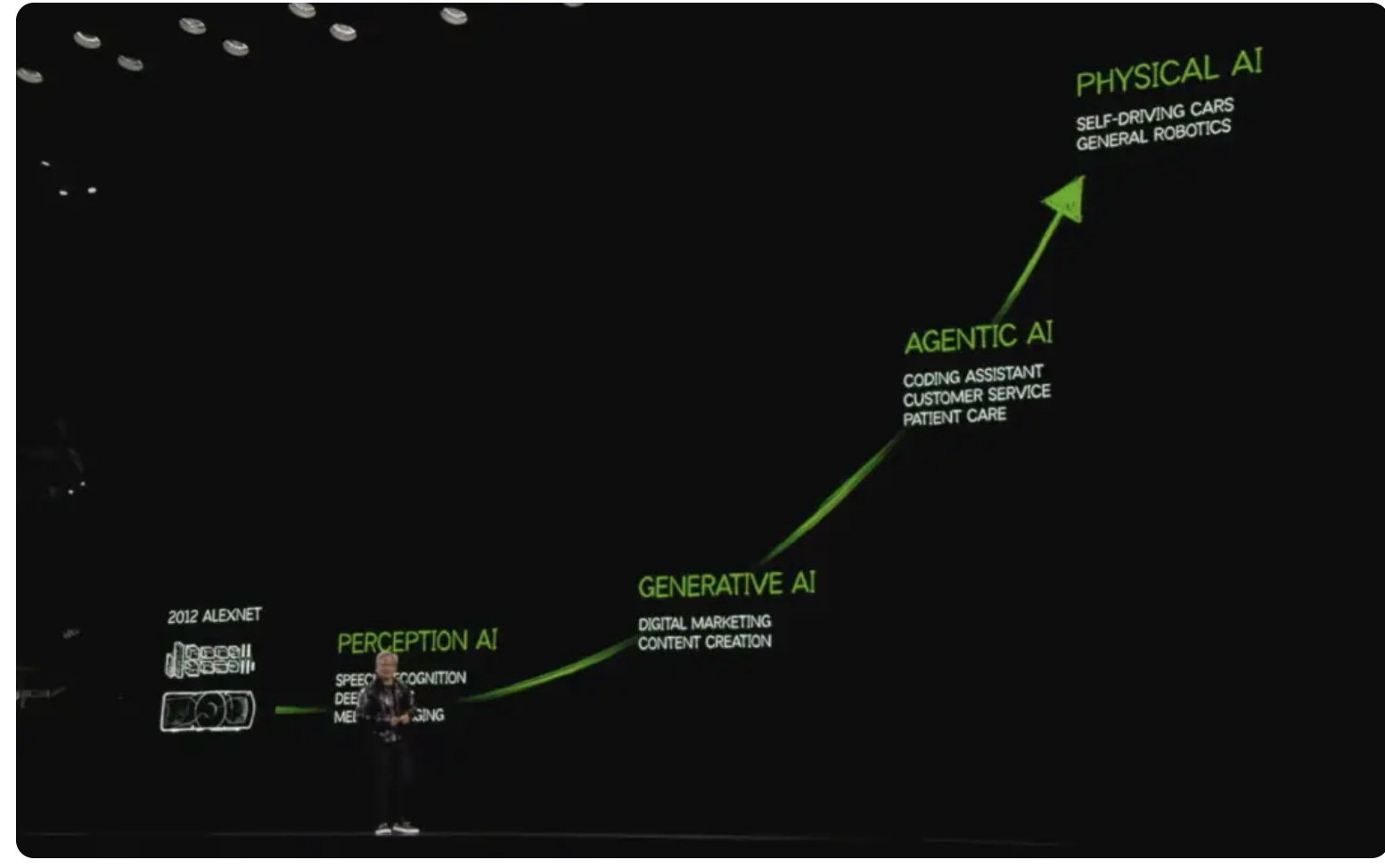
那麼,「世界模型」(World Model)究竟是什麼?又因何成了AI下個競技場的發展核心?
心智模型的啟發:AI模擬人腦的「世界之眼」
事實上,世界模型受到重視,也是來自於人類「心智模型」(Mental Model)的啟發。
對於世界如何運作、該採取什麼決策,總有著一些反覆出現的概念,例如機會成本、80/20法則、飛輪效應…等,這些概念被稱為「心智模式」。人類大腦會從感官獲取資訊,並將外部現實轉化為大腦中的「小規模模型」,藉此形成對周圍世界更具體的理解,進而對「將發生的改變」預做模擬,以便提前因應。
這樣的例子層出不窮,例如駕駛員對交通狀況的立即反應(剎車、轉向等),或是在球場上預判投球的路線並揮擊出去等——這種能力來自於大腦內部對世界的模擬,無需每一步都清楚的意識到,就能直覺性地反射因應。
機器人若要自在穿梭於人類世界,顯然必須具備這種「理解眼前將發生的事件」的能力。
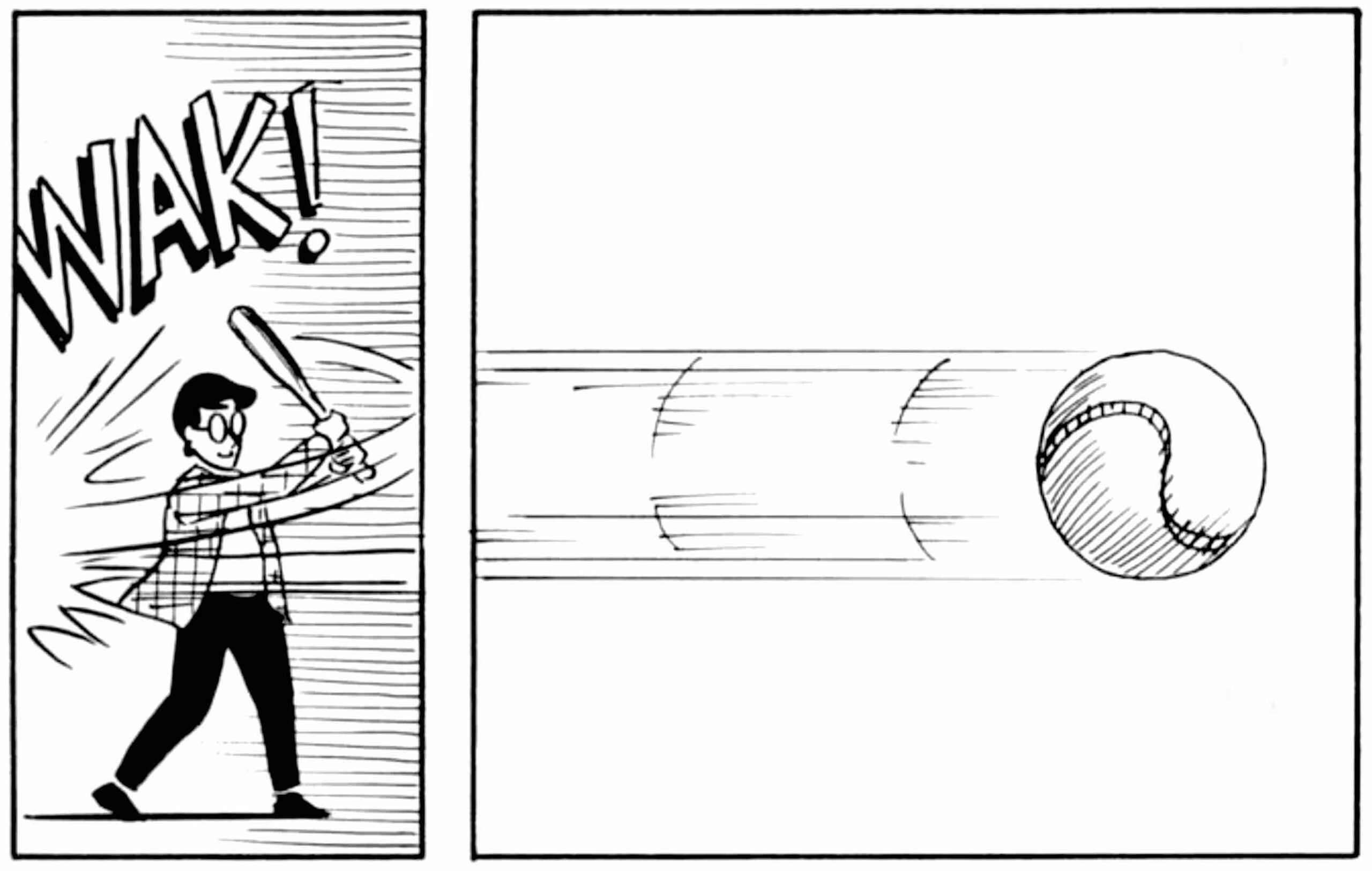
人類理解分格漫畫的時空意義,正是「心智模型」解讀外在影像的能力。(source)
世界模型的核心:AI的「想像力」與「規劃腦」
所謂世界模型,就是一套能學習環境本質、模擬未來狀態的生成模型。不同於以往只是在輸入與輸出之間快捷通路的方式,世界模型讓AI像人腦一樣生成「內部世界」,在這個虛擬環境自我訓練與思考,預判每個行動帶來的結果。這不僅讓AI更有效率地學習,也讓規劃和決策邏輯更貼近人類的直觀。
更厲害的是,經由無監督的方式訓練世界模型,AI能理解並壓縮眼前世界的高維訊號,將策略自模擬世界遷移到現實環境,用以解決所需的任務。
技術拆解:世界模型的三大腦
世界模型的發展其實已有十多年了,其重要的核心演算法是大型遞歸神經網路(RNN),它是具有高度表現力的模型,能夠學習數據中豐富的空間和時間表示。從技術結構來看,世界模型多由三大核心組件協同:
-
視覺模型(V):以變分自動編碼器(VAE)等將龐大影像或影片訊號壓縮為低維、具意義的表徵,過濾噪音,保留世界本質。
-
記憶模型(M):利用循環神經網路(RNN)或Transformer架構模擬環境的時序動態,預測未來的走向與分佈,洞察行動影響。
-
控制器(C):在世界模型生成的虛擬場景中規劃出最高效的操作策略,免去直接在現實反覆嘗試的繁複與危險,加速學習步伐。
這種模組化設計,讓世界模型在不斷「虛擬演練」中增強預見力,控制器則專心磨練決策直覺,兩者相輔相成。
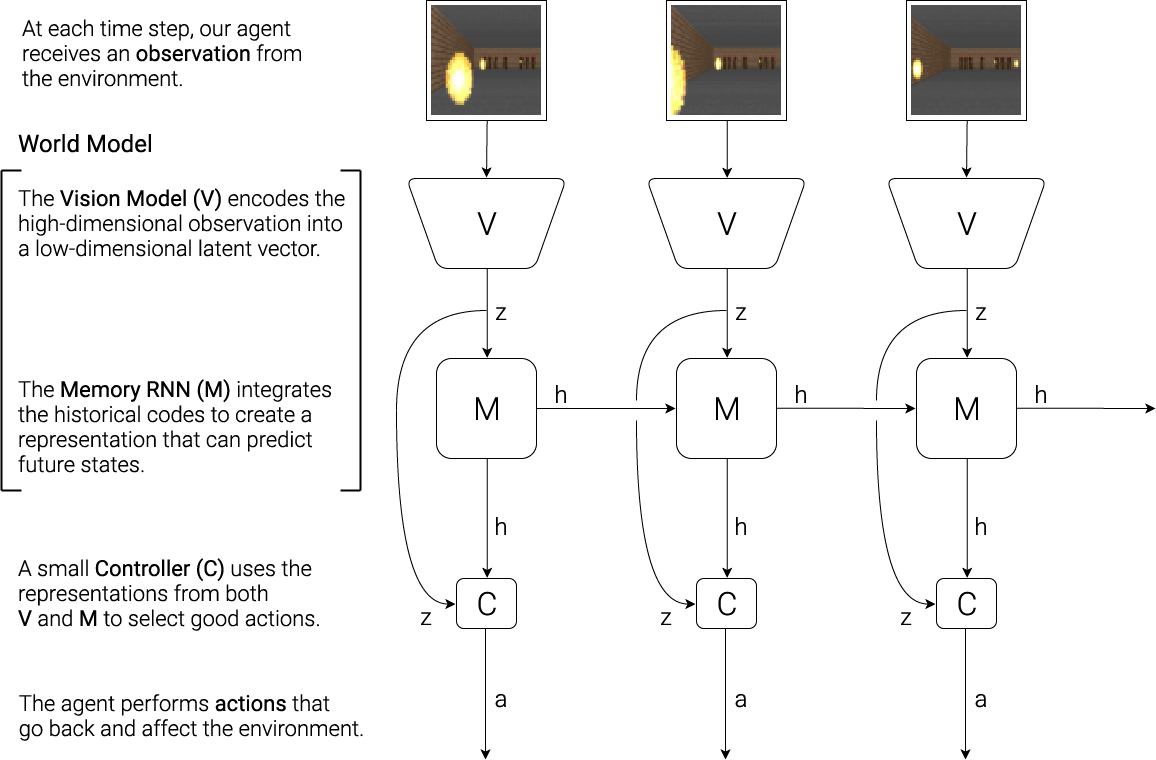
世界模型運作流程示意圖(source)
世界模型的應用現場:現實與虛擬的無縫接軌
這場世界模型革命正蔓延至各行各業:
-
強化學習與電玩:世界模型最著名的演示之一是由David Ha 和 Jürgen Schmidhuber在他們的論文《世界模型》中提出的。他們使用內部世界模型而非直接強化學習,訓練人工智慧玩賽車遊戲和VizDoom。人工智慧學會了預測遊戲狀態,模擬不同的策略,然後執行最佳策略,從而實現更有效率的學習。
-
自駕車技術:自駕汽車不僅依感測器數據反應,而是模擬各種交通動態、環境變化,提前規劃路徑與避險行為。
-
機器人應用:冶金工廠、深海探索、太空維修等高風險場合,AI能在虛擬場景中實戰模擬,降低現場成本與危險。
-
科學與醫學發現:AI世界模型正被用來預測蛋白質摺疊、模擬分子結構、氣候走勢等,成為人類解開未來鎖匙的新利器。
Meta、NVIDIA 與 Google 佈局世界模型
當今世界模型(World Model)成為AI界熱門新賽道,正吸引Meta、NVIDIA、Google等多家科技巨頭投入重金與頂尖人才發展。以下簡要介紹各家領頭企業在世界模型的最新進展:
Meta:V-JEPA 2 世界模型
-
V-JEPA 2是Meta於2025年推出的世界模型,具備理解、預測並規劃現實世界動作的能力。
-
它以超過100萬小時的影片為核心訓練資料,主攻機器人和自駕車,能做到「零樣本」(zero-shot)控制規劃,機器人在新環境、陌生物體下也能完成複雜任務。
-
Meta強調V-JEPA 2能掌握「物理直覺」,例如能理解球離桌就會掉落、遮擋下物體依然存在,並能根據結果預判和規劃後續行為。
-
Yann LeCun表示,這類世界模型將成為讓AI像人類般思考和行動的核心技術。
NVIDIA:Cosmos 世界基礎模型
-
Cosmos平台是NVIDIA最新「世界基礎模型」(World Foundation Model)平台,強調開放、可定制性和大規模合成數據的產生能力。
-
Cosmos以2,000萬小時現實人類互動/環境/工業/機器人影片作為訓練資料,能預測和模擬虛擬世界中的物理互動,幫助自駕車和機器人發展。
-
Cosmos結合自回歸(Auto-regressive)和擴散式(Diffusion-based)模型,除了提升物理一致性,還能支援合成視覺場景快速生成,極大壓縮開發週期與成本。
-
NVIDIA也推出如Cosmos-Transfer1這類專為機器人強化學習預訓練的條件世界模型。
Google(DeepMind):全力打造多模態世界模型
-
Google DeepMind於2024年底成立專責「世界模型」AI團隊,由前OpenAI Sora負責人Tim Brooks帶領,以多模態(文本、圖像、影片等)融合為發展重點,並積極招募人才,目標是打造能模擬真實物理世界的大型生成模型.
-
DeepMind開發的Genie模型,能模擬虛擬世界和現實物理互動,應用於即時媒體互動、電玩、虛擬訓練場、機器人與自駕場景等。
-
Google Gemini大旗也正大舉往「世界模型」方向發展,企圖將理解和推理、決策機制統合進行,最終目標是建構下一代可理解情境、採取行動的通用AI助手。
未來展望
世界模型的挑戰仍然不少,包括模型精度、長期記憶、泛化能力等等,都是需要攻克的難題。但隨著大型數據、強算力及跨領域人才湧入,這場由Meta、NVIDIA、Google等巨頭主導的新賽道已全面展開。
未來,世界模型不僅將成為AI生成邏輯與決策理性的「作業系統」,也將成為構築AGI通用智能的地基。當AI能夠像人類般「腦海作夢」,為現實行動鋪設策略,這個讓機器具有想像力的內在世界,將再度翻轉外在世界,例如,人與機器的界限將更加模糊了。
》延伸閱讀:
Physical AI近了!如何打造「通用又專才」的機器人?
World Modeling: The Future of AI

- AI如何讓機器人更有「人」味:跨越雙手協同鴻溝! - 2026/03/17
- 2026 Edge AI MCU技術趨勢與廠商方案現況比較 - 2026/03/12
- 大自然的逆向工程:Festo用20年打造的仿生螞蟻、蜜蜂與水母 - 2026/03/10
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


