作者:武卓,英特爾AI軟體傳教士
大型語言模型(LLM)徹底改變了人類文字生成的方式,使其在聊天機器人、虛擬助手和內容生成等場景中變得不可或缺。然而,要將這些龐大的模型微調用於特定任務,通常需要大量的運算資源和訓練時間。但如果你可以在不重新訓練整個模型的情況下,高效率地完成微調呢?這正是 LoRA(Low-Rank Adaptation)大顯身手的地方。
LoRA透過導入一組小型可訓練矩陣,為大模型提供了一種羽量級、低成本的客製方式,大幅降低了記憶體佔用。現在,借助OpenVINO GenAI,你可以無縫整合LoRA配接器,實現對大語言模型的快速個性化客製。開發者還可以一次性載入多個LoRA配接器,並在執行時快速切換,無需重新編譯基礎模型。無論你是在構建智慧客服機器人、生成個性化內容,還是自動化知識管理流程,以OpenVINO搭配LoRA配接器,都能幫助你用更少的資源,實現更多可能。
接下來,我們一起來看看,使用OpenVINO GenAI執行LoRA配接器進行LLMs推論,究竟有多簡單!
步驟1:複製 OpenVINO GenAI GitHub儲存庫
要使用OpenVINO GenAI API實現推測式解碼,首先需要複製openvino.genai GitHub儲存庫。該儲存庫包含具備LoRA配接器的文字生成的實作範例,支援Python和C++,可幫助開發者快速上手並部署高效的LLM推論方案。
git clone https://github.com/openvinotoolkit/openvino_genai.git
cd openvino_genai
步驟2:為AI模型轉化安裝依賴項(Python)
要執行OpenVINO GenAI配備LoRA的LLM推論範例,需要配置環境並安裝必要的工具、儲存庫和相關依賴項。請按照以下步驟正確安裝所需元件:
1. 創建 Python 虛擬環境
虛擬環境可以隔離專案依賴,確保一個乾淨、無衝突的開發環境。使用以下指令創建並啟動虛擬環境:
python3 -m venv venv_export
source venv_export/bin/activate # For Windows: openvino_env\Scripts\activate
2. 安裝必要的儲存庫
為了將模型匯出為OpenVINO相容格式,需要安裝相關依賴項。執行以下指令安裝必要的儲存庫:
pip install --upgrade-strategy eager -r ../../export-requirements.txt
此指令確保所有必需儲存庫都已安裝並可正常使用,包括OpenVINO GenAI、Hugging Face工具和Optimum CLI。這些元件將支援具備LoRA的LLM推論之實現,使開發者能夠高效率匯出和最佳化模型,從而加速LLM推論過程。
步驟3:下載和準備LLM及其LoRA配接器
對於文字生成,我們將使用Llama-3.2-3B-Instruct模型,該模型可透過以下指令一鍵下載,並轉換為OpenVINO IR格式:
optimum-cli export openvino --model meta-llama/Llama-3.2-3B-Instruct --weight-format int4 --group-size 64 --ratio 1.0 Llama-3.2-3B-Instruct/INT4
除此之外,還有其他支援LoRA配接器的大語言模型,完整清單見此頁面,歡迎自由嘗試。
稍等片刻後,模型將出現在本地磁碟上,可直接用於文字生成。如果後續不再需要進行模型轉換或最佳化,可以將 venv_export 資料夾從磁碟中刪除——這些依賴項並不是執行推論所必須的。
步驟4: 使用LoRA配接器執行LLM推論
首先,建議創建一個Python虛擬環境來執行AI推論。與用於模型下載和轉換的環境不同,這裡只需要安裝一個Python套件 —— openvino.genai。
python -m venv venv
venv\Scripts\activate
pip install -r ../../deployment-requirements.txt
openvino_genai.AdapterConfig用於在openvino_genai.LLMPipeline中管理LoRA配接器。可以透過它添加或移除配接器,也可以調整它們的權重係數alpha。alpha 混合係數是一個縮放因數(scaling factor),用於控制LoRA配接器在推論時對模型輸出的影響程度。
- 較高的alpha值會增強配接器的影響力,適用於當前任務與基礎模型的預訓練任務差異較大時;
- 較低的alpha值則能弱化配接器的干預,更好地保留基礎模型原有的行為特性。
可以在配置中添加一個LoRA配接器,並為其設置特定的alpha 值,以實現更加客製化的文字生成。
目前,OpenVINO GenAI支援以Safetensors格式保存的LoRA配接器。可以選擇Hugging Face Hub上公開的預訓練配接器,或自行訓練配接器。
那怎麼為某個LLM模型找到開源的LoRA 配接器呢?其實很簡單:
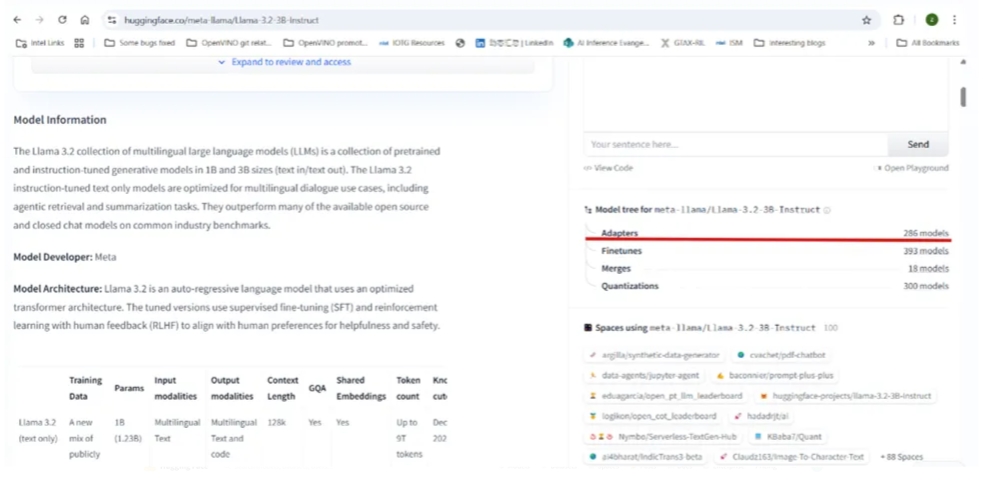
以Llama-3.2–3B-Instruct為例,打開該模型的Hugging Face “Model card”頁面,向下滾動頁面,在右側會看到名為“Model tree”的模組,如下圖所示。其中的第一個部分就是“Adapters”。
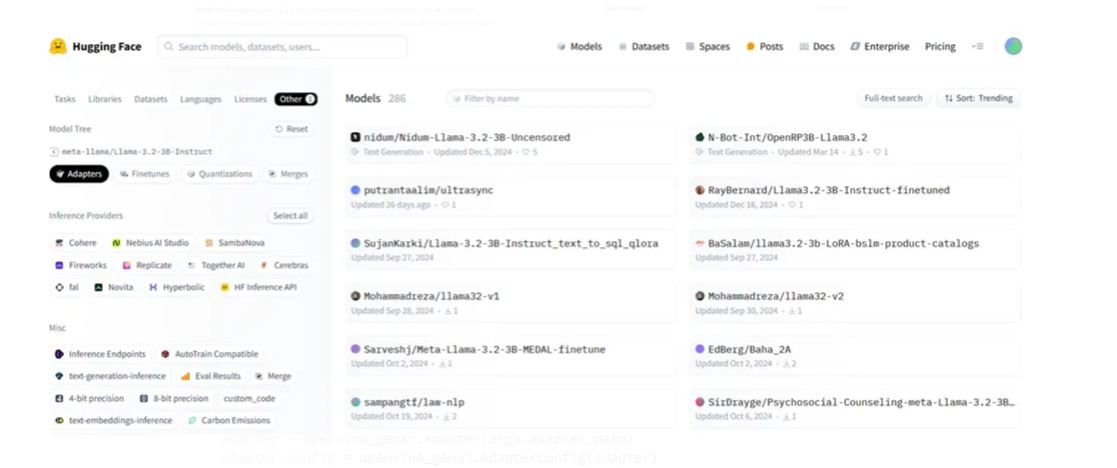
點擊該連結後,你將跳轉到Hugging Face上該模型所有開源LoRA配接器的清單頁面(如下圖所示)。在這裡,你可以點擊每個LoRA配接器的連結,選擇最適合你應用場景的版本。
處理LoRA配接器的程式碼範例如下:
adapter = openvino_genai.Adapter(args.adapter_path)
adapter_config = openvino_genai.AdapterConfig(adapter)
將LoRA整合到GenAI API的文字生成推論流程中,只需一行程式碼:
pipe = openvino_genai.LLMPipeline(args.models_path, device, adapters=adapter_config) # register all required adapters here
在本文中,我們選擇了適用Llama-3.2–3B-Instruct的LoRA配接器。使用如下指令,即可呼叫 “bosmet/lora_model_llama-3.2–3B-Instruct” LoRA配接器和INT4量化的Llama-3.2–3B-Instruct模型來生成文字:
python lora_greedy_causal_lm.py./Llama-3.2-3B-Instruct/INT4 adapter_model.safetensors prompt
請注意,在載入預訓練配接器之前,務必確保其與基礎模型架構相容。例如,如果你使用的是Llama-3.2–3B-Instruct模型,那麼必須選擇為該模型類型訓練的LoRA配接器。否則,如果配接器是為其他類型的LLM模型訓練的,將無法在推論流程中正確整合與執行。
步驟5:使用C++構建和執行帶有LoRA的文字生成
儘管Python是一門功能強大的程式語言,非常適合進行程式碼實驗,但在很多情況下,C++更常應用於桌面應用程式的開發。以下是一個使用LoRA進行文字生成的C++ 範例程式碼:
std::string device = "CPU"; // GPU can be used as well
using namespace ov::genai;
Adapter adapter(adapter_path);
LLMPipeline pipe(models_path, device, adapters(adapter)); // register all required adapters here // Resetting config to set greedy behaviour ignoring generation config from model directory.
// It helps to compare two generations with and without LoRA adapter.
ov::genai::GenerationConfig config;
config.max_new_tokens = 100;
pipe.set_generation_config(config);
std::cout << "Generate with LoRA adapter and alpha set to 0.75:" << std::endl;
std::cout << pipe.generate(prompt, max_new_tokens(100), adapters(adapter, 0.75)) << std::endl;
std::cout << "\n-----------------------------";
std::cout << "\nGenerate without LoRA adapter:" << std::endl;
std::cout << pipe.generate(prompt, max_new_tokens(100), adapters()) << std::endl;
有關使用LoRA構建文生圖的C++應用程式所需內容的詳細指南,請參考此處。
結論
透過將LoRA配接器與OpenVINO GenAI 結合使用,可以高效率地將LLM與特定任務配接,同時顯著降低資源消耗。無論你是在開發AI聊天機器人、虛擬助手,還是內容生成工具,LoRA都能提供一種靈活且強大的微調解決方案。歡迎深入探索OpenVINO GenAI API,嘗試整合多種 LoRA 配接器,全面提升你的AI應用能力。
寫程式愉快!

- OpenVINO 2025.3: 更多生成式AI,釋放無限可能 - 2025/09/26
- 用OpenVINO GenAI解鎖LoRA微調模型推論 - 2025/08/29
- 用OpenVINO GenAI解鎖LLM極速推論:推測式解碼讓AI爆發潛能 - 2025/04/23
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


2025/09/08
第一段git路徑好像改了:https://github.com/openvinotoolkit/openvino.genai.git