作者:Adrian Boguszewski,英特爾AI軟體佈道師
翻譯:武卓,英特爾AI軟體佈道師
什麼是AI PC?
筆者不喜歡冗長的介紹,所以儘量簡潔扼要;要了解我打造的是什麼,首先得解釋一下什麼是AI PC:AI PC是一台配備專門用於加速AI工作負載硬體的電腦,意味著我們可以高效率地運作包含AI模型的應用程式。
就是這樣…我們來看看如何組裝:透過精選的軟硬體,筆者將證明幾乎任何類型的AI應用都可以在本地運作。希望你已經迫不及待想看看了!
零件選擇
在選購硬體之前,筆者做出了一些假設:
- 本機用於運作AI推論(應用),不是深度學習訓練;
- 尺寸應盡可能小巧,便於移動;
- 成本要控制在合理範圍內;
- 選項:盡可能支援安裝雙GPU。
鑒於上述需求,以及筆者服務於Intel,因此盡可能使用Intel的硬體。
所需零件:
- 主機殼
- CPU(中央處理器)
- 主機板
- 記憶體(RAM)
- 散熱系統
- GPU(繪圖處理器)
- 電源(PSU)
- 儲存裝置
(備註:筆者受到了這篇文章的啟發)
主機殼
首選中塔主機殼,相容micro-ATX主機板,能容納較長的GPU,品牌不限。
CPU
筆者想嘗試搭載iGPU和NPU的最新Intel Arrow Lake系列,於是選用了Intel Core Ultra 7 265K。
主機板
需要一塊帶FCLGA1851插槽的micro-ATX主機板,擁有至少兩個間隔良好的PCIe插槽,以及4個DDR5記憶體插槽,品牌開放。
記憶體
64GB DDR5記憶體起步,以支援大模型推論並兼顧未來擴展。
散熱系統
可任意搭配主機殼的風冷散熱器,無品牌偏好。
GPU
筆者已有 Intel Arc A770顯卡,同時也想體驗較新的Battlemage系列,因此又選擇了Intel Arc B580。
電源
為了驅動整套系統,我選擇了1000W以上的電源,介面要能滿足主機板、CPU 和雙GPU的供電需求。
儲存
1TB的NVMe M.2固態硬碟,足夠儲存大型AI模型。
組裝過程
首先將CPU安裝到主機板插槽中,確保方向正確並牢固鎖定。然後將M.2固態硬碟插入對應插槽,並用固定螺絲將其固定。

接著將記憶體條插入主機板上的DIMM插槽,以啟用雙通道模式。隨後安裝了CPU散熱器,並塗抹了導熱矽脂,以實現最佳的導熱效果。

完成主機板預裝後,將其固定進主機殼,並將兩片獨立顯卡插入PCIe x16插槽,同時安裝電源並連接全部供電線纜。

最後連接前面板、資料和電源線,確保一切穩固連接後,系統準備上電並安裝作業系統。

軟體配置
硬體就緒後,接下來是驗證性能的時候了。
作業系統
筆者是Linux愛好者,因此安裝了Ubuntu 24.10。 (備註:Windows當然也可以!)
驅動程式安裝
初始系統只能識別CPU,可參考筆者自己寫的部落格文章安裝驅動,讓所有GPU和NPU被識別。(備註:Windows系統通常會自動識別設備,但建議更新驅動程式;這裡可以找到更多資料)
安裝OpenVINO
用於模型最佳化和推論部署,在Python環境中透過pip安裝最簡單:
python3 -m venv venv
source venv/bin/activate
pip install openvino
驗證裝置是否可用:
import openvino as ov
core = ov.Core()
print(core.available_devices)
print([core.get_property(device, "FULL_DEVICE_NAME") for device in core.available_devices])
輸出為:
['CPU', 'GPU.0', 'GPU.1', 'GPU.2', 'NPU']
['Intel(R) Core(TM) Ultra 7 265K', 'Intel(R) Graphics [0x7d67] (iGPU)', 'Intel(R) Graphics [0xe20b] (dGPU)', 'Intel(R) Arc(TM) A770 Graphics (dGPU)', 'Intel(R) AI Boost']
說明所有裝置已就緒。
應用測試
筆者運作了三個AI應用來測試推論性能:一個視覺生成模型,一個聊天機器人,以及一個傳統的目標檢測應用。
這是一個文生圖的GenAI應用,輸入提示詞生成插畫圖像。
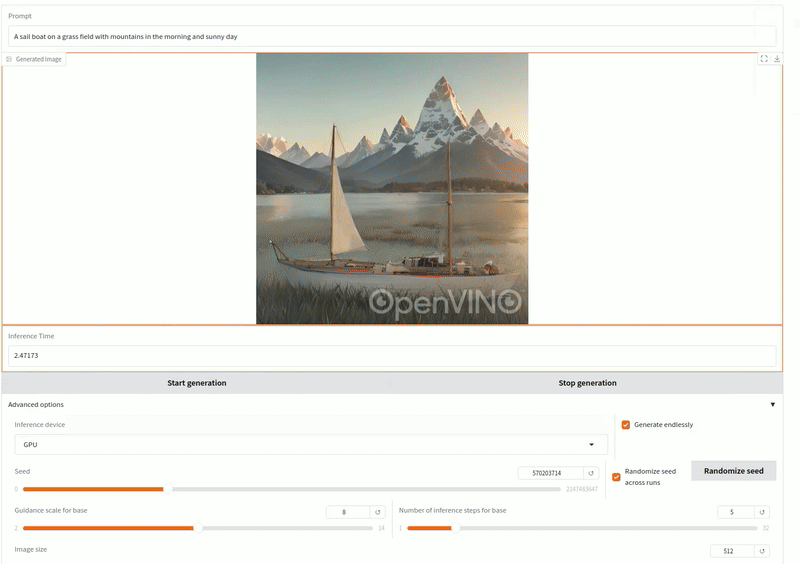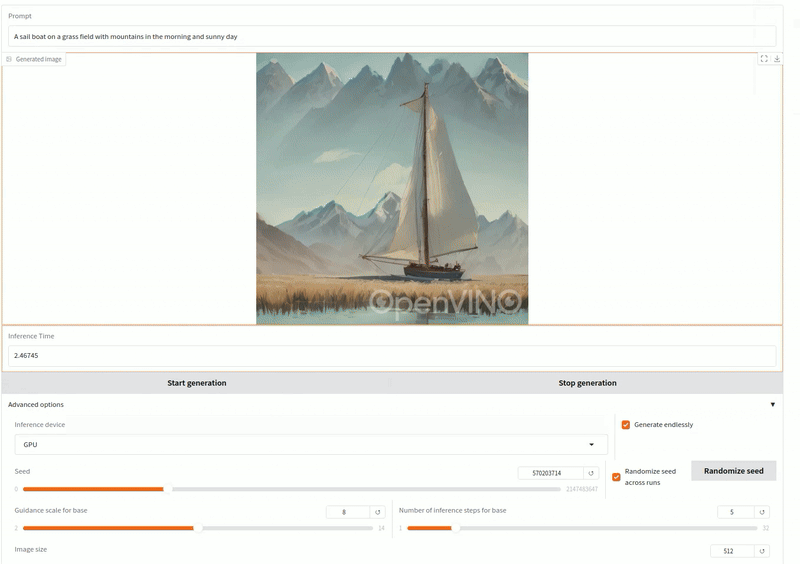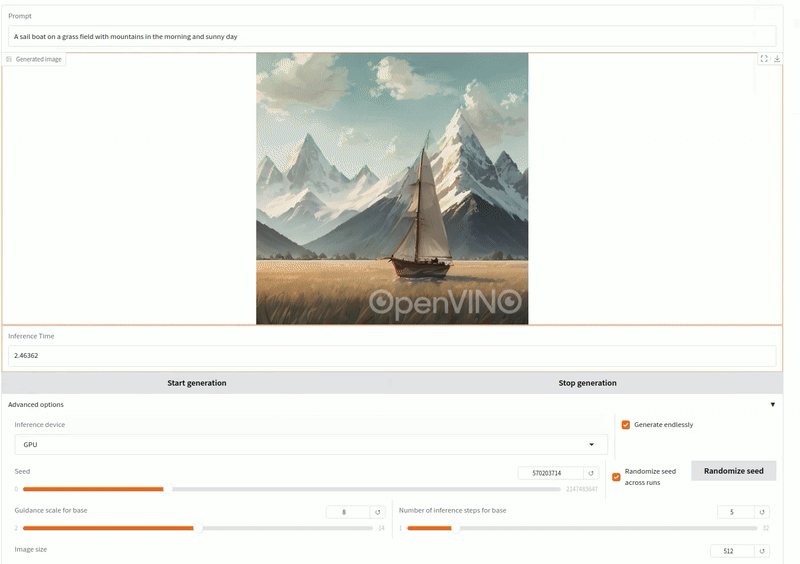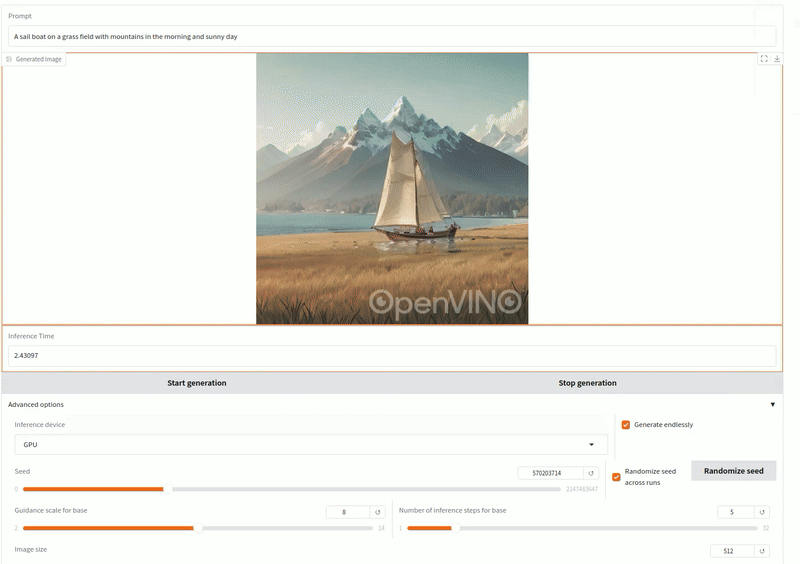
測試提示詞:「草地上航行的帆船,背景是陽光明媚的早晨群山。」使用OpenVINO/LCM_Dreamshaper_v7-fp16-ov 模型(5步驟)。
各裝置耗時(秒)如下:
- CPU:6.69
- iGPU:3.11
- NPU:3.67
- B580:0.21
- A770:0.26
每秒可生成約4-5張 512×512 圖像。(注意:性能可能因使用方式、配置和其他因素而有所不同,請參閱文章最下方的系統配置)
這是一個RAG流水線構建的聊天助手,用於醫療問答,但可配置為任意風格。
使用模型:
- LLM: meta-llama/Llama-3.2–3B-Instruct
- Embedding: BAAI/bge-small-en-v1.5
- Reranker: BAAI/bge-reranker-base
不同裝置推論速度(Token/s):
- iGPU:20
- B580:63
- A770:66
遠超人類平均閱讀速度(約 5–8 tokens/s)。(注意:性能可能因使用方式、配置和其他因素而有所不同,請參閱文章最下方的系統配置)
用於目標檢測的Ultralytics YOLO11n模型,輸入尺寸 640×640,INT8 精度。
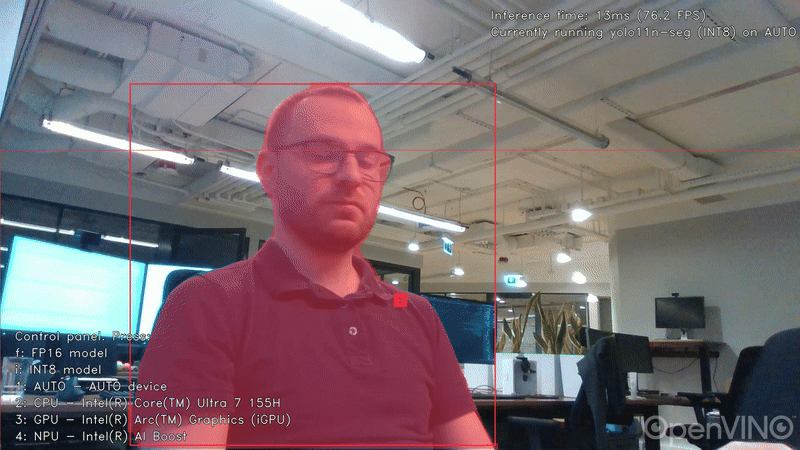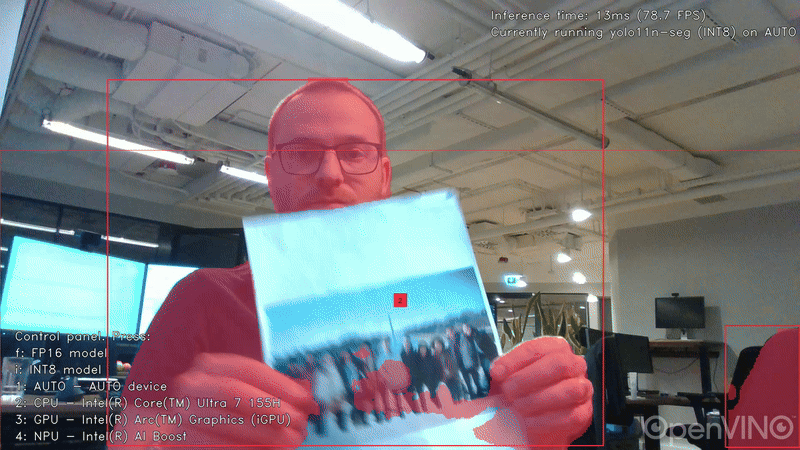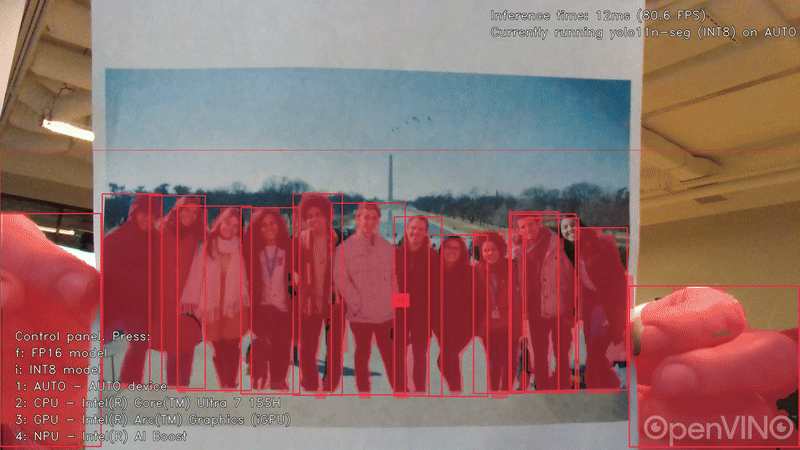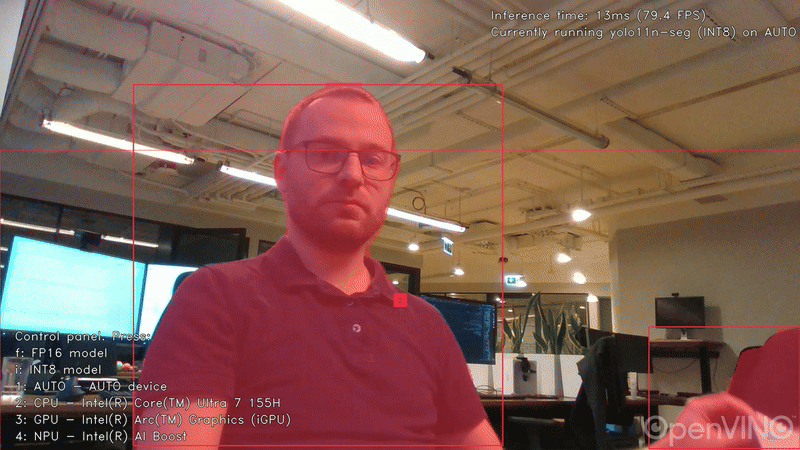
延遲模式下的影格率(FPS)如下:
- CPU:42.1
- iGPU:72.4
- B580:115.5
- A770:210.2
- NPU:49.5
但上述是採用延遲模式進行的測試,該模式針對串流應用進行了最佳化。然而,如果我們一次性獲取所有影格,例如處理一段完整視訊時,就可以使用大量處理模式(throughput mode)。筆者還使用以下指令對所有裝置在大量處理模式下進行了測試:
benchmark_app -m yolo11n.xml -hint throughput -d CPU
大量處理模式下的影格率:
- CPU:405.4
- iGPU:353.9
- B580:1963.8
- A770:918.5
- NPU:124.5
也就是說,一小時視訊可在29秒內處理完!(注意:性能可能因使用方式、配置和其他因素而有所不同,請參閱文章最下方的系統組態)
Bonus:AI訓練能力
本專案的目標是打造一台用於 AI 推論的電腦。Intel GPU自PyTorch 2.5起已支援訓練;只需將使用裝置設定為「XPU」,如下所示:
model = model.to("xpu")
data = data.to("xpu")
就可以在GPU上訓練模型,為這台AI PC增添新價值!
測試平台配置
- 主機板: MSI B860M GAMING PLUS WIFI (MS-7E42)
- CPU: Intel® Core™ Ultra 7 265K
- Sockets/Physical cores: 1/20 (20 threads)
- HyperThreading/Turbo Settings: Disabled
- 記憶體: 64 GB DDR5 @ 6400 MHz
- GPU: 1x Intel® Graphics (4 Xe cores), 1x Intel® Arc™ A770 Graphics (32 Xe cores), 1x Intel® Arc™ B580 Graphics (20 Xe cores)
- NPU: Intel® AI Boost
- TDP: 665W
- BIOS: American Megatrends International, LLC. 2.A10
- BIOS release date: 28.11.2024
- 作業系統: Ubuntu 24.10
- Kernel: 6.11.0–25-generic
- Workload — model, precision, size (HxW), BS:
Paint Your Dreams: LCM_Dreamshaper_v7, FP16, 512×512, 1
Virtual AI Assistant: Llama-3.2–3B-Instruct, INT4, dynamic shape, 1
People Counter: Ultralytics YOLO11n, INT8, 640x640x1, 1 - OpenVINO版本: 2025.1.0–18503
- 測試日期: 15.05.2025
- 測試者: Intel Corporation
(參考原文:How did I build an AI PC on my own at my home?;責編: Judith Cheng)

- AI Agent時代來臨:看邊緣AI如何成為驅動智慧機器人的關鍵 - 2025/11/28
- OpenVINO×ExecuTorch:解鎖英特爾架構AI PC模型推論效能新境界 - 2025/11/21
- 讓生成式AI應用在Intel架構系統本地端高效率運作的訣竅 - 2025/10/16
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


