作者:高煥堂、鄭仲平
在上一篇文章裡,說明了以英特爾(Intel)研發的新產品和相關技術來提升AI模型的訓練效率;其中的兩項核心產品是:
- 軟體:Intel-Extension-for-PyTorch模組。
- 硬體:Intel(R) Data Center GPU Flex 170。
本篇文章將說明如何善用這兩項產品來實現效能的大幅提升,然後仍然接續上一篇的<ResNet + LoRA>微調訓練的範例來展現它們的特性,並說明其使用方法和流程。
簡介IPEX
IPEX (Intel-Extension-for-PyTorch)用來搭配Intel硬體產品,以提供最佳化和功能來大幅提升其運作效能。例如,它透過PyTorch的<xpu>裝置來發揮Intel GPU的潛能,大幅加速AI模型的訓練和推論。其典型的開發環境是:使用Docker Desktop 和WSL2在基於Intel GPU的Windows電腦上執行PyTorch模型。
此外,其最佳化的硬體系列產品還包括Intel AVX-512的機器學習指令VNNI,以及AMX和XMX等AI引擎。即使您使用一般CPU,也能獲得最佳化的效果。在CPU上,這IPEX是根據偵測到的ISA自動將運算子分派到底層核心,因而擴展利用Intel硬體上提供的向量化和矩陣加速單元。於是,在運作時達到細粒度的執行緒控制和權重共享,來提高運作效能。
在AI模型軟體開發上,如果使用Python語言,只需在程式中匯入(Import)這個IPEX模組即可。而在C++程式中,只需要連結(Link)到這擴充模組的C++程式庫即可。IPEX模組是一項Github上的開源專案,人人都可以下載程式源碼以及相關使用說明文件。
IPEX搭配Intel GPU的開發環境
以Intel Arc GPU為例
剛才說明了AI模型訓練師可以活用IPEX來搭配Intel的CPU與GPU系列產品,然後透過PyTorch的<xpu>裝置來最佳化它們,發揮其潛在威力,將效能與效率提升至全新的境界。例如,使用Intel Arc GPU在Windows上執行影像偵測、辨識,以及生成多模態內容。在應用上,諸如增強遊戲與尖端創作體驗,來滿足眾人的遊戲探險之旅。

圖1:Intel Arc GPU晶片
接下來,就以Intel Arc GPU在Windows上的運作為例,來說明其環境建置的步驟。
開發環境的建置
Step-1:在Windows電腦上安裝Intel Arc GPU驅動程式(Driver)。
Step-2:在電腦上啟用WSL2。
Step-3:建置帶有WSL2的Docker Desktop。這Docker益處是它簡化了安裝過程。它掌管各項必要的步驟,包括啟動PyTorch所需要的相關程式庫。因而在Intel GPU上啟動和執行PyTorch模型時,變得更簡單而且高效率。
Step-4:然後,使用Docker Desktop和WSL2,在基於<IPEX + Intel GPU>的Ununtu系統環境裡訓練及執行PyTorch模型。
Step-5:撰寫一個簡單的測試程式。
- 首先安裝Intel-Extension-for-PyTorch模組,其相關的Pytorch版本為:

- 然後,撰寫簡單測試程式如下:

此範例先從torchvision.models裡載入resnet50預訓練模型。當其執行到指令:
model = ipex.optimize(model)
就會使用IPEX來對ResNet50模型進行最佳化。於是,讓這resnet50能發揮Intel CPU等硬體特性來加速訓練和推論。
在IPEX+GPU環境裡訓練ResNet50+LoRA
剛才的簡單測試程式,是在IPX+CPU環境裡進行推論測試的。接著,就來把CPU更換為GPU,並且實機進行<ResNet50 + LoRA>整合模型的微調訓練。
在上一篇文章的範例中,曾經在CPU環境裡訓練了這<ResNet50 + LoRA>模型。本篇文章將改變為在GPU環境訓練一樣的<ResNet50 + LoRA>模型。
於是,AI模型訓練師就能活用IPEX來搭配Intel的CPU與GPU系列產品,然後透過 PyTorch的<xpu>裝置來最佳化它們,發揮其潛在威力,將效能與效率提升至全新的境界。
Step-b1:準備訓練資料(Training data) 這與上一篇文章範例的訓練資料集是一樣的。茲複習一下,首先在本機裡準備了/oopc/m_data/train/圖像集,包含三個類別—斑馬、貓頭鷹和蘑菇:  各類別都有80張圖像,例如斑馬圖像:
各類別都有80張圖像,例如斑馬圖像:  總共有240張圖像。然後把它複製到Ubuntu的文件夾裡:
總共有240張圖像。然後把它複製到Ubuntu的文件夾裡:
base_path = '/home/eapet/resnet_LoRA/m_data/'
就能在不同訓練環境裡使用一致的訓練資料集了。
Step-b2: 定義<ResNet50+LoRA>模型,並展開訓練
本範例的<ResNet50 + LoRA>整合模型,與上一篇文章中的模型是一致的,訓練資料集也是一致的。請您參閱上一篇,來複習一下ResNet50和LoRA的功能和用法。而在本範例裡,只是從原來的CPU更換為GPU而已。此範例的程式碼如下:
# lora_RESNET_basic_003_train_xpu.py
import numpy as np
import torch
import torch.nn as nn
from torchvision import transforms
from torchvision.datasets import ImageFolder
from torch.utils.data import Dataset, DataLoader
from torchvision.models import resnet50, ResNet50_Weights
import time
data_path = '/home/eapet/resnet_LoRA/m_data/train/'
base_path = '/home/eapet/resnet_LoRA/m_data/'
# Make torch deterministic
# 設定:每次訓練的W&B初始化都是一樣的
_ = torch.manual_seed(0)
#-------------------------------------
# 載入ResNet50預訓練模型
# Step 1: Initialize model with the best available weights
weights = ResNet50_Weights.IMAGENET1K_V1
resnet_model = resnet50(weights=weights)
# 遷移學習不需要梯度(不更改權重)
for param in resnet_model.parameters():
param.requires_grad = False
#-------------------------------
resnet_model.eval()
#------------------------------------------
# 準備Training data
# 把圖片轉換成Tensor
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor()
])
data_set = ImageFolder(data_path, transform=transform)
length = len(data_set)
print("\n")
print(length, "張圖片\n")
bz = 60
test_loader = DataLoader(data_set, batch_size=bz, shuffle=True)
#--------------------------------------
def process_lx(labels):
lx = labels.clone()
for i in range(bz):
if(labels[i]==0):
lx[i]=340
elif(labels[i]==1):
lx[i]=24
elif(labels[i]==2):
lx[i]=947
return lx
for idx, (images, la) in enumerate(test_loader):
break
labels = process_lx(la)
print(labels)
#-----------------------------------
def test():
correct = 0
total = 0
wrong_counts = [0 for i in range(3)]
with torch.no_grad():
for idx, (images, la) in enumerate(test_loader):
labels = process_lx(la)
prediction = resnet_model(images)
for idx, zv in enumerate(prediction):
if torch.argmax(zv) == labels[idx]:
correct +=1
else:
#print(idx)
wrong_counts[la[idx]] +=1
total +=1
#print(correct)
print('\n', f'Accuracy: {round(correct/total, 3)}')
for i in range(len(wrong_counts)):
print(f'wrong counts for the digit {i}: {wrong_counts[i]}')
#------------------------------------------
print('\n------ 原模型測試: ------')
test()
#==========================================
class Lora(nn.Module):
def __init__(self, m, n, rank=10):
super().__init__()
self.m = m
self.A = nn.Parameter(torch.randn(m, rank))
self.B = nn.Parameter(torch.zeros(rank, n))
def forward(self, inputs):
inputs = inputs.view(-1, self.m)
return torch.mm(torch.mm(inputs, self.A), self.B)
lora = Lora(224 * 224 * 3, 1000)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(lora.parameters(), lr=1e-4)
#========================================================
print('\n------ 外掛LoRA模型,協同訓練: ------')
import intel_extension_for_pytorch as ipex
loss_fn = loss_fn.to("xpu")
lora = lora.to("xpu")
lora, optimizer = ipex.optimize(lora, optimizer=optimizer)
resnet_model = resnet_model.to("xpu")
resnet_model = ipex.optimize(resnet_model)
base = 0
epochs = 100
begin = time.time()
for ep in range(epochs+1):
total_loss = 0
for idx, (images, la) in enumerate(test_loader):
labels = process_lx(la)
images = images.to("xpu")
labels = labels.to("xpu")
pred = resnet_model(images) + lora(images)
loss = loss_fn(pred, labels)
loss.backward()
optimizer.step()
optimizer.zero_grad()
total_loss += loss.item() * bz
if((base+ep)%5 == 0):
loss_np = total_loss / 120
print('ep=', base+ep,'/',base+epochs, ', loss=', loss_np)
end = time.time()
print("TTT =", end-begin)
#------ Saved to *.CKPT ---------------------------
FILE = base_path + 'LORA_for_RESNET_ep50.ckpt'
torch.save(lora.state_dict(), FILE)
print('\nsaved to ' + FILE)
#-------------------------------------
def test22():
correct = 0
total = 0
wrong_counts = [0 for i in range(3)]
with torch.no_grad():
for idx, (images, la) in enumerate(test_loader):
labels = process_lx(la)
images = images.to("xpu")
labels = labels.to("xpu")
prediction = resnet_model(images) + lora(images)
for idx, zv in enumerate(prediction):
if torch.argmax(zv) == labels[idx]:
correct +=1
else:
wrong_counts[la[idx]] +=1
total +=1
print('\n', f'Accuracy: {round(correct/total, 3)}')
for i in range(len(wrong_counts)):
print(f'wrong counts for the digit {i}: {wrong_counts[i]}')
#------------------------------------------
print('\n------ 原模型測試: ------')
test22()
#---------------------------
#END
此範例使用Pytorch的指令:
lora = lora.to("xpu")
來設定由GPU來執行這LoRA模型。繼續使用指令:
lora, optimizer = ipex.optimize(lora, optimizer=optimizer)
來對LoRA模型軟體進行最佳化。
同樣地,也使用Pytorch指令來最佳化resnet_model模型。以及設定由GPU來執行這resnet_model模型。如下圖所示:
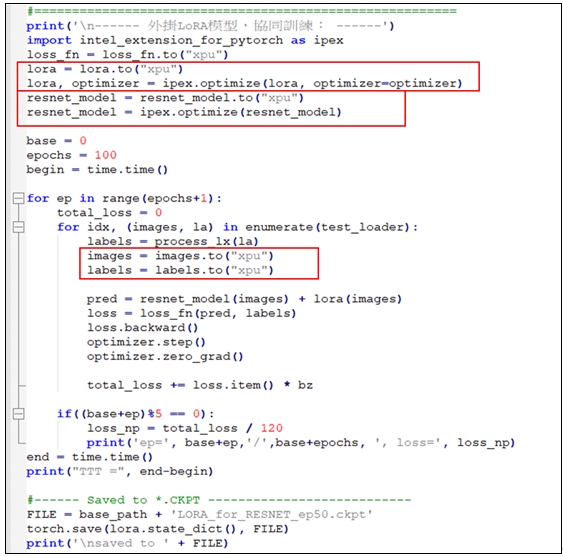
請仔細觀察這程式的執行情境:它使用IPEX + GPU,並搭配Windows或Ubuntu作業系統來展開協同訓練。例如,在Ubuntu環境裡,使用命令(Command):
![]()
就展開訓練100回合,執行結果顯示如下圖:
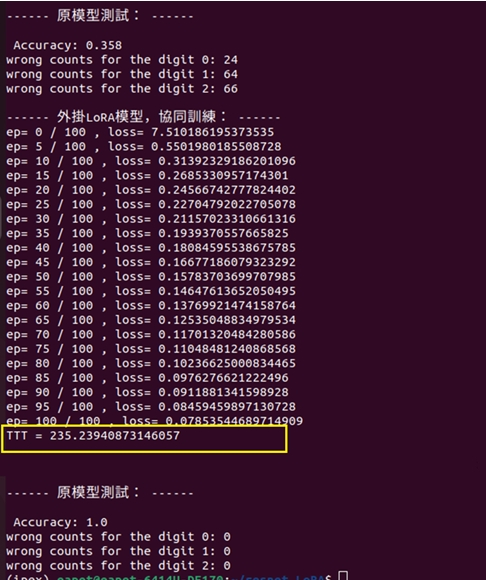
圖4:訓練環境是:IPEX + GPU
從圖4可看出,本範例採取IPEX + GPU的軟硬體搭配的模式,針對相同的<ResNet50 + LoRA>模型,一樣進行訓練100回合,其訓練的耗時為:235秒。茲回憶上一篇文章中的訓練,其耗時為:405秒。已呈現出很明顯的加速效益了。
結語
從本篇的實機訓練的輸出結果,我們可以觀察到:在上一篇文章裡,曾在單純CPU環境下進行訓練,我們把LoRA外掛到ResNet50,然後進行協同訓練100回合,其訓練的耗時為:405 秒。
而在本範例裡,採取IPEX + GPU的軟硬體搭配的模式,針對相同的<ResNet50 + LoRA>模型,一樣進行訓練100回合,其訓練的耗時很明顯,已經下降為:235秒。
經由這實機訓練,呈現出<IPEX + GPU>明顯的最佳化效益。
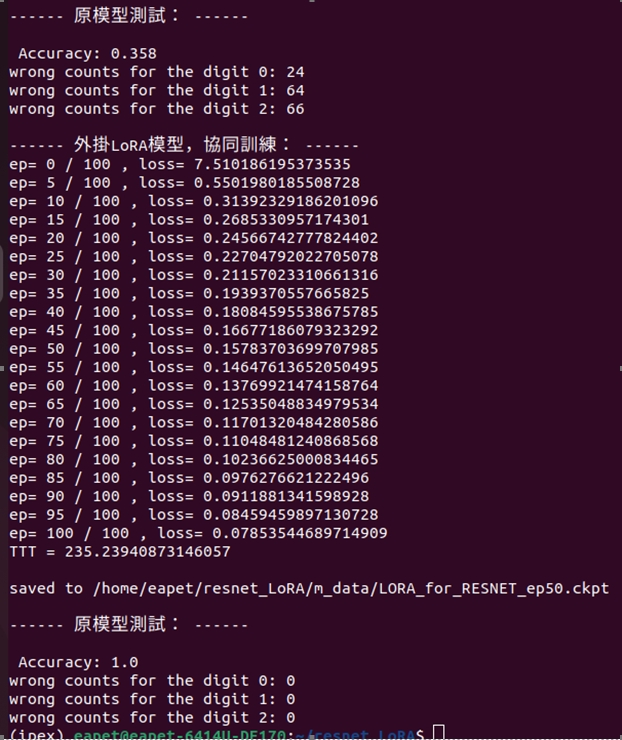
1. ResNet50在未加掛LoRA協同訓練時,正確率0.358,圖片為斑馬的誤辨次數為24次,貓頭鷹誤判次數64,蘑菇誤判則為66。
2. 訓練時間TTT = 235.23940873146057秒。
3. 訓練後,誤判數為0。
呈現各種等級GPU環境的訓練效能提升的幅度,成為促進AI生態未來發展的強大力量。

近5年來,從事於AI普及化教育工作,目前擔任銘傳大學AI課程、長庚智慧醫療研究所AI課程授課老師。也擔任永春國小、東園國小、立志中學、君毅中學、永春高中等學校的AI師資培育工作。
- LoRA微調三步驟:以大語言模型MT5為例 - 2024/05/02
- 為什麼Gemma採取Decoder-Only Transformer架構呢? - 2024/04/08
- 如何從0訓練企業自用Gemma模型 - 2024/04/03
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


