Edge AI談的是讓邊緣裝置也能具有AI的執行功能,但這類裝置的運算力及記憶體容量都很有限,想要順利的運行AI功能,需要對AI模型進行優化(Optimization),以達成以下目的:
- 縮短雲端和邊緣裝置 (例如行動裝置、IoT) 的延遲時間與推論成本。
- 將模型部署至邊緣裝置,並限制處理能力、 記憶體、耗電量、網路用量和模型儲存空間。
- 執行和最佳化現有硬體或新型特殊用途加速器(如Edge TPU)。
不過,針對尺寸大小或延遲進行最佳化的模型往往會損失少量的準確性,Edge AI工程師需在應用程式開發過程中考慮如何在不影響用戶體驗的前提下實現模型的優化,而TensorFlow針對此需求提供TensorFlow Model Optimization Toolkit(模型最佳化工具包),協助開發者優化其TensorFlow模型,進而能達到部署到邊緣硬體的最佳化需求。工具包的一些功能如下:
TensorFlow Lite 目前支援透過量化(Quantization)、修剪(Pruning)和聚類(Clustering)三種方式進行最佳化,這些是TensorFlow 模型最佳化工具包的一部分 ,該工具包提供了與 TensorFlow Lite 相容的模型最佳化技術的資源。
這三種優化模型的技術中,修剪的工作原理是刪除模型中對其預測影響很小的參數。修剪後的模型在磁碟上的大小相同,並且具有相同的運行時延遲,但可以更有效地壓縮。這使得修剪成為減少模型下載大小的有用技術。
聚類的工作原理是將模型中每一層的權重分組為預定義數量的叢集(Cluster),然後共享屬於每個單獨叢集的權重的質心值(centroid values)。此舉減少了模型中唯一權重值的數量,從而降低了其複雜性。因此,此技術可以更有效地壓縮叢集模型,從而提供類似於修剪技術的部署優勢。
不過,目前主要的推論模型優化技術是量化技術。量化技術的工作原理是降低用於表示模型參數的數字的精度,預設情況下這些數字是 32 位元浮點數(floating point)。這會導致模型尺寸更小,計算速度更快。TensorFlow Lite 中提供以下類型的量化:
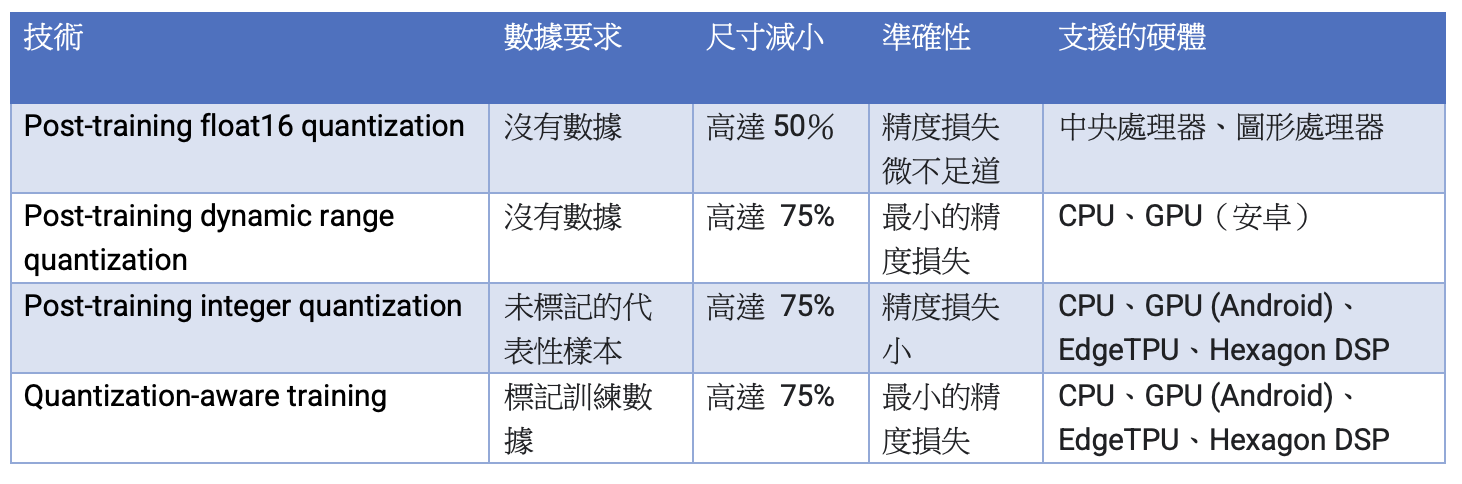
以下決策樹可協助您僅根據預期的模型大小和準確性來選擇可能想要用於模型的量化方案:
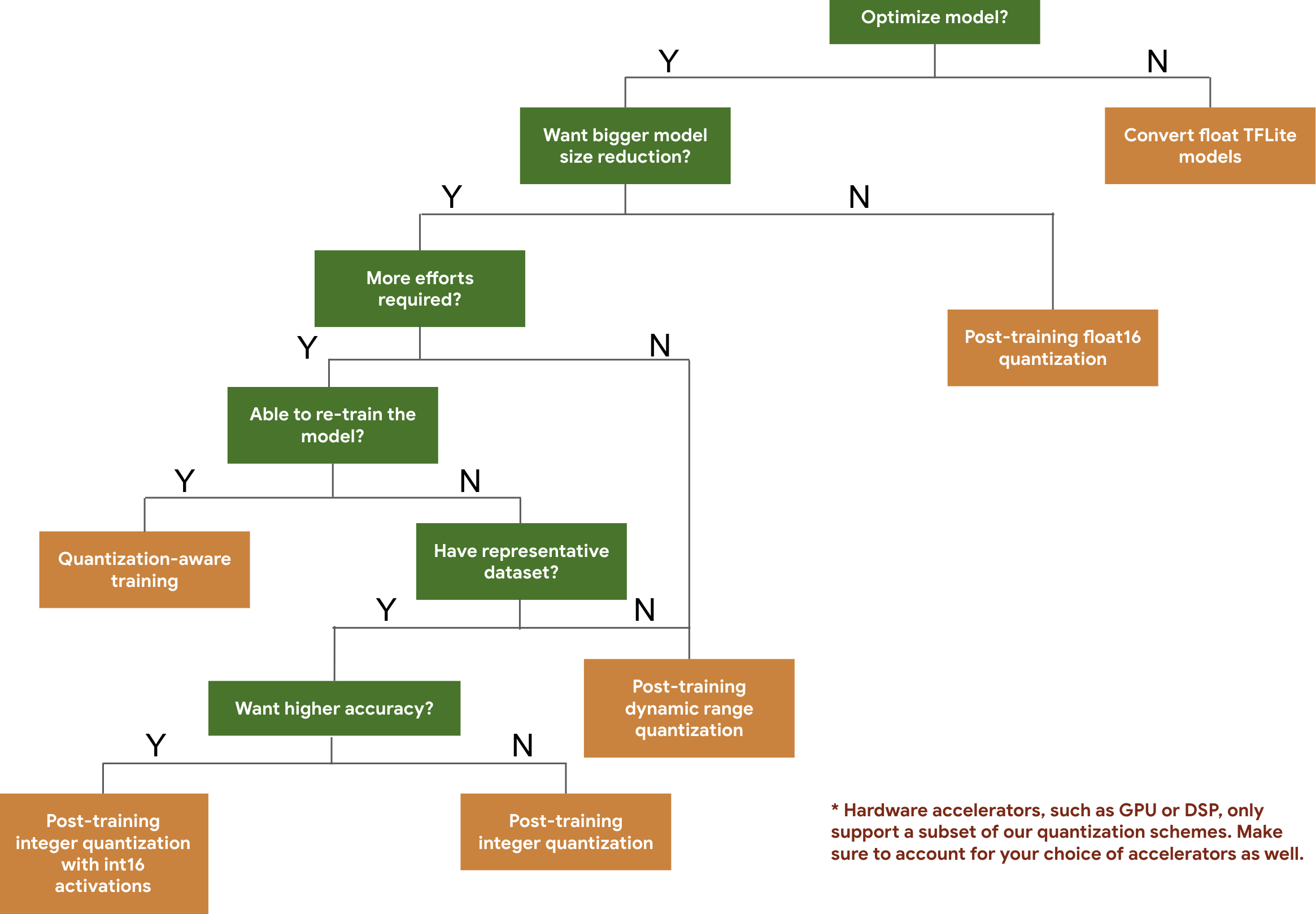
TensorFlow文件建議想優化模型的開發者,可考慮從 訓練後量化工具(post-training quantization tool )開始著手,因為它廣泛適用且不需要訓練資料。對於未滿足準確性和延遲目標或硬體加速器支援很重要的情況,量化感知訓練(quantization-aware training)是更好的選擇。如果想進一步減小模型大小,可以在量化模型之前嘗試修剪 和/或聚類技術。
(責任編輯:歐敏銓)
延伸閱讀:
TensorFlow Model optimization(技術文件)
Weight Pruning(技術文件)
Weight clustering(技術文件)

- AI 機器人如何落實安全性控制 - 2026/04/02
- 簡化AI機器人訓練 Universal Robots與Scale AI推出模仿學習系統 - 2026/04/01
- 【Podcast】看見地球的真相:SkyTruth 用 AI 監控人類行為 - 2026/04/01
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


