作者:楊亦誠
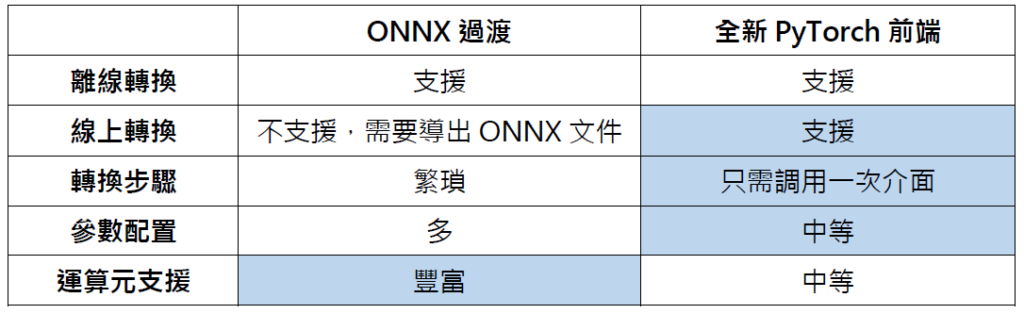
作為最熱門的開源深度學習框架之一,PyTorch的易用性和靈活性使其深受學術和研究界的喜愛。之前OpenVINO對於PyTorch模型的支援也僅僅停留在ONNX 過渡階段,需要透過將PyTorch動態模型匯出為ONNX靜態格式後,才可以直接被 OpenVINO Runtime 離線載入。雖然PyTorch也提供了官方的torch.onnx.export介面協助開發者匯出ONNX模型,但畢竟有這麼一個「仲介」在那裡,其中很多額外的配置工作也為 OpenVINO開發者帶來了不便,諸如動態/靜態輸入設定,以及opset版本設定等。
OpenVINO直接支援PyTorch模型物件
隨著OpenVINO 2023.0版本的發佈,OpenVINO工具庫中預置了全新的PyTorch前端,為開發者們提供了一條全新的PyTorch模型支援路徑,帶來更友好的用戶體驗—— OpenVINO的mo工具可以直接將PyTorch模型物件轉化為OpenVINO的模型物件,開發者可以不需要將ONNX模型作為中間過渡。
import torchvision
import torch
from openvino.tools.mo import convert_model
model = torchvision.models.resnet50(pretrained=True)
ov_model = convert_model(model)
對比以ONNX作為中間過度的方式,新 PyTorch 前端有以下特點:
目前支援的PyTorch模型物件有:
- torch.nn.Module
- torch.jit.ScriptModule
- torch.jit.ScriptFunction
在OpenVINO內部,PyTorch前端基於TorchScript進行模型匯出,而 TorchScript 支援兩種模型匯出模式,一種稱為Tracing,一種稱為Scripting。其中Tracing指的是PyTorch在模型運行時,追蹤運行經過的模組運算元,即時構建運算流程圖,並最終總結為一種中間表示。Trace是個雙刃劍,好處是用戶無需瞭解Python程式碼箇中細節,無論是Function、Module還是Generators、Coroutines,Tracing都會忠實地記錄下經過的Tensor以及Tensor Function,非常適用於不涉及資料相關控制流的簡單模組和功能,例如標準卷積神經網路;壞處就在於Tracing不能感知控制流和運算圖的動態,如 if 語句或迴圈。
例如它會把迴圈展開,一方面可能可以增加編譯優化的空間,另一方面如果該迴圈在不同infer的時候是動態變長的,那麼Tracing不能感知到這一點,只會將Tracing時候的迴圈記錄下來。為了轉換包含依賴於資料的控制流模組和函數,提供了一種Scripting機制,Scripting從Python原始程式碼層級進行解析,而非在執行時構建。Scripting會去理解所有的code,真正像一個編譯器一樣去進行語法分析等操作。Scripting相當於一個嵌入在Python/Pytorch的DSL,其語法只是PyTorch語法的子集,這意味著存在一些op和語法Scripting不支援,這樣在編譯的時候就會遇到問題。
在剛剛的例子中,PyTorch 前端使用Scripting進行模型匯出,如果想使用Tracing的方式,可以在介面中新增一個example_input 參數,此時PyTorch前端會優先調用Tracing的方式,當Tracing的方式失敗後,再調用Scripting方式。
import torchvision
import torch
from openvino.tools.mo import convert_model
model = torchvision.models.resnet50(pretrained=True)
ov_model = convert_model(model, example_input=torch.zeros(1, 3, 100, 100))
目前 examle_input 支援的資料格式有:
- openvino.runtime.Tensor
- torch.Tensor
- np.ndarray
- list or tuple with tensors (openvino.runtime.Tensor / torch.Tensor / np.ndarray)
- dictionary where key is the input name, value is the tensor (openvino.runtime.Tensor / torch.Tensor / np.ndarray)
值得注意的是,以上兩個例子匯出的均為動態輸入模型物件,如果想指定模型的輸入 shape,可以再次添加額外的參數input_shape/input,將輸入shape作為參數傳入,選其一即可。案例可參考以下的實戰部分。
最後,如果開發者希望匯出靜態 IR 檔以便後續使用,也可以調用以下介面,將OpenVINO的模型物件進行序列化:
serialize(ov_model, str(ir_model_xml))
BERT 模型案例實戰
接下來我們通過一個實例來看下如何完成從 BERT 模型轉化到量化的全過程。
1. 獲取 PyTorch 模型物件
torch_model =
BertForSequenceClassification.from_pretrained(PRETRAINED_MODEL_DIR)
2. 設置模型參數並轉化為OpenVINO模型物件
由於BERT是一個多輸入模型,這裡額外添加了一個input=input_info參數,可以用來指定多輸入模型中每一個input的shape以及資料類型。
3. 準備校驗資料集,並啟動量化input_shape = PartialShape([1, -1])
input_info = [("input_ids", input_shape, np.int64),("attention_mask",
input_shape, np.int64),("token_type_ids", input_shape, np.int64)]
default_input = torch.ones(1, MAX_SEQ_LENGTH, dtype=torch.int64)
inputs = {
"input_ids": default_input,
"attention_mask": default_input,
"token_type_ids": default_input,
}
model = convert_model(torch_model, example_input=inputs, input=input_info)
上一步中獲得的 model 為 openvino.runtime.Model 類型,可以直接被 NNCF 工具載入
calibration_dataset = nncf.Dataset(data_source, transform_fn)
# Quantize the model. By specifying model_type, we specify additional
transformer patterns in the model.
quantized_model = nncf.quantize(model, calibration_dataset,
model_type=ModelType.TRANSFORMER)
4. 編譯量化後的模型物件,並進行推理
compiled_quantized_model = core.compile_model(model=quantized_model, device_name="CPU")
output_layer = compiled_quantized_model.outputs[0]
result = compiled_quantized_model(inputs)[output_layer]
result = np.argmax(result)
print(f"Text 1: {sample['sentence1']}")
print(f"Text 2: {sample['sentence2']}")
print(f"The same meaning: {'yes' if result == 1 else 'no'}")
最終結果如下:
Text 1: Wal-Mart said it would check all of its million-plus domestic workers to ensure they were legally employed .
Text 2: It has also said it would review all of its domestic employees more than 1 million to ensure they have legal status .
The same meaning: yes
完整實例和性能精度比較,可以參考:
總結
作為近期發佈的最新版本,OpenVINO 2023.0中的mo工具可以在不需要透過ONNX中間過渡的情況下,直接將 PyTorch 模型物件轉化為 OpenVINO物件,免去開發者離線轉化和額外配置的過程,帶來更友好的使用者體驗。有鑒於該功能是預發佈狀態,可能存在部分運算元不支援的情況,此時,開發者依舊可以使用之前的路徑,依託ONNX 前端進行PyTorch模型的轉換。

- 輕薄型筆電OK!利用OpenVINO部署Phi-3.5「全家餐」 - 2024/09/20
- LangChain框架已正式支援OpenVINO! - 2024/06/12
- 如何在Windows平台呼叫NPU部署深度學習模型 - 2024/03/04
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


