作者:楊亦誠,英特爾AI軟體工程師
作為深度學習領域的「Github」,HuggingFace已經共用了超過10萬個預訓練模型,1萬個資料集,其中就包括了目前AIGC領域非常熱門的「文生圖」、「圖生文」任務範式,例如ControlNet、StableDiffusion、Blip等。
透過HuggingFace開源的Transformers、Diffusers程式庫,只需要要調用少量介面函數,入門開發者也可以非常便捷地微調和部署自己的大模型任務,你甚至不需要知道什麼是GPT、BERT就可以用它們的模型,開發者不需要從頭開始構建模型任務,大幅簡化了工作流程。從下面圖1的例子可以看到,在導入Transformer程式庫以後只需要5行程式碼就可以構建一個基於GPT2的問答系統,期間HuggingFace會為你自動下載Tokenizer詞向量庫與預訓練模型。

圖1:HuggingFace預訓練模型任務調用範例。
但也正因為Transformer、Diffusers這些程式庫具有非常高的易用性,很多底層的程式碼與模型任務邏輯也被隱藏了起來,如果開發者想針對某個硬體平台做特定的優化,則需要將這些程式庫的底層流水線進行拆解,再逐個進行模型方面的最佳化。圖2與圖3就展示了利用HuggingFace程式庫在調用ControlNet介面時的邏輯,和其底層實際流水線結構:
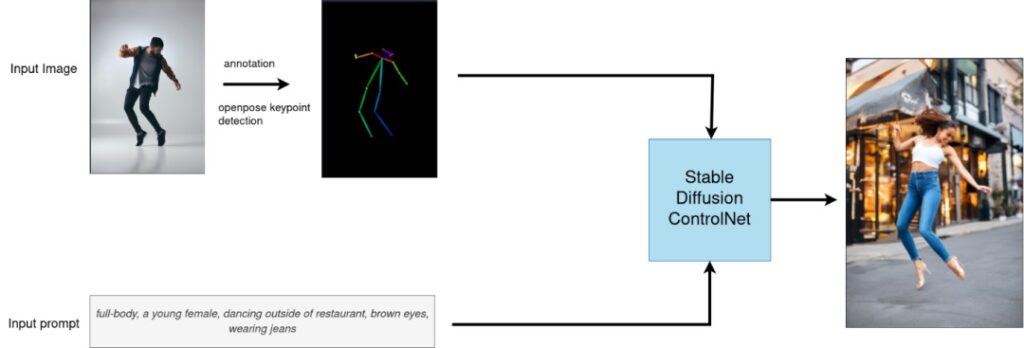
圖2:ControlNet介面調用邏輯。
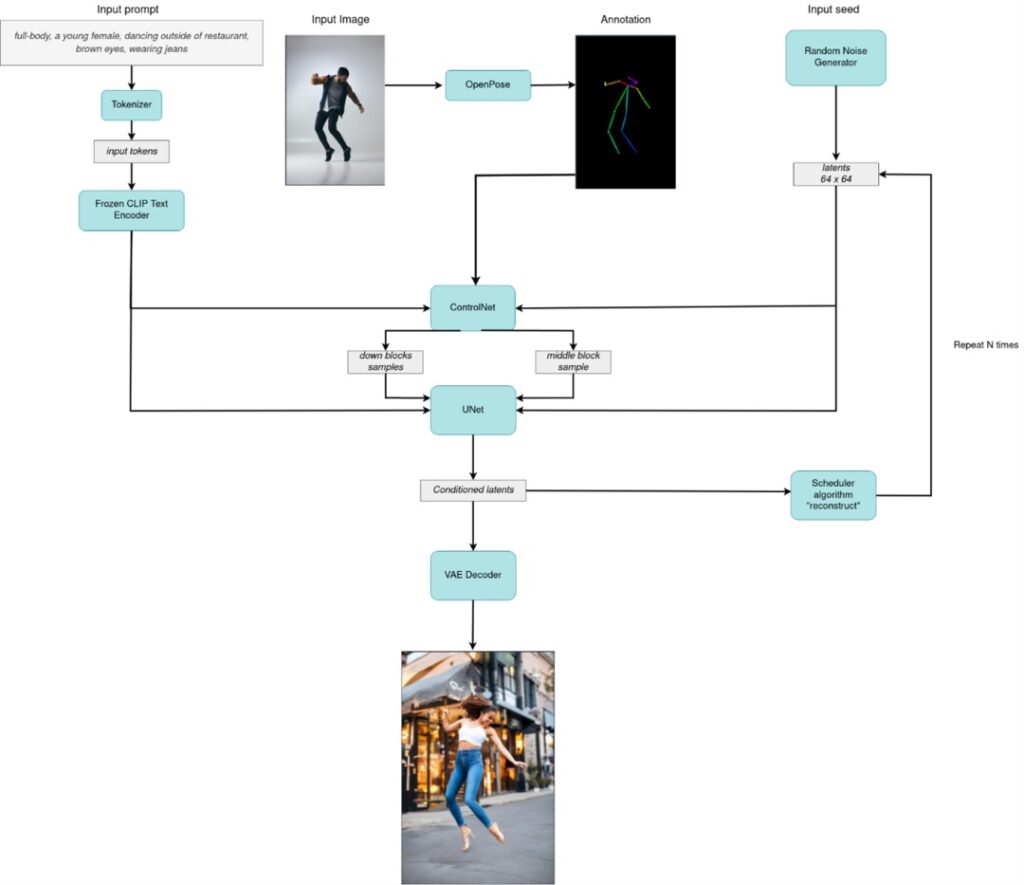
圖3:ControlNet實際運作邏輯。
OpenVINO 簡介
用於高性能深度學習的英特爾(Intel)發行版本OpenVINO 工具套件基於oneAPI而開發,以期在從邊緣到雲端的各種英特爾平台上,幫助使用者更快地將更準確的真實世界結果部署到生產系統中。透過簡化的開發工作流程, OpenVINO能讓開發者在現實世界中部署高性能應用程式和演算法。
在推論後端,得益於 OpenVINO 工具套件提供的「一次編寫,任意部署」特性,轉換後的模型能夠在不同的英特爾硬體平台上運作,無需重新構建,有效簡化了構建與遷移過程。此外,為了支援更多的異質加速單元,OpenVINO 的runtime API 底層採用了外掛程式的開發架構,基於oneAPI中的oneDNN等函數運算加速程式庫,針對通用指令集進行深度最佳化,為不同的硬體執行單元分別實現了一套完整的高性能運算元庫,充分提升模型在推論運作時的整體性能表現。
可以說,如果開發者希望在英特爾平台上實現最佳的推論性能,並具備多平台適配和相容性,OpenVINO 是不可或缺的部署工具首選。因此接下來的方案也是在探討如何利用OpenVINO 來加速HuggingFace預訓練模型。
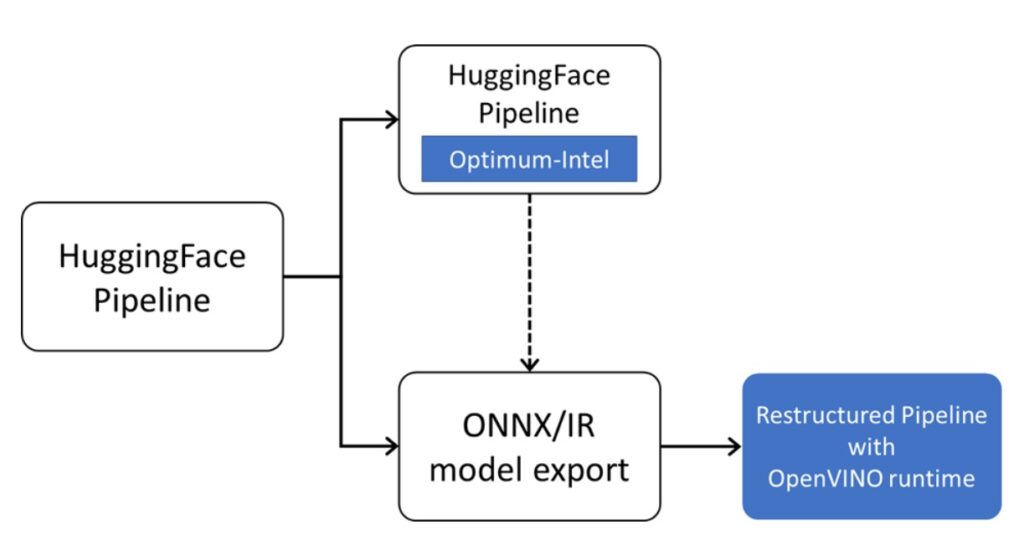
圖4:OpenVINO部署HuggingFace模型路徑。
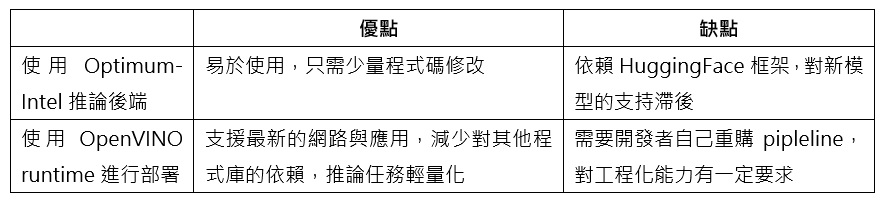
方案一:使用 Optimum-Intel 推論後端
Optimum-Intel 用於在英特爾平台上加速 HuggingFace 的端對端流水線。它的 API和Transformers或是Diffusers的原始API極其相似,因此所需程式碼更動很小。目前Optimum-Intel已經整合了OpenVINO 作為其推論任務後端,在大部分 HuggingFace預訓練模型的部署任務中,開發者只需要替換少量程式碼,就可以實現HuggingFace Pipeline中的模型透過 OpenVINO 部署在Intel CPU上,並加速推論任務,OpenVINO 會自動最佳化bfloat16模型,最佳化後的平均延遲下降到了 16.7 秒,相當不錯的2倍加速。從圖5可以看到,在調用OpenVINO 的推論後端後,我們可以最大化Stable Diffusion系列任務在Intel CPU上的推論性能。
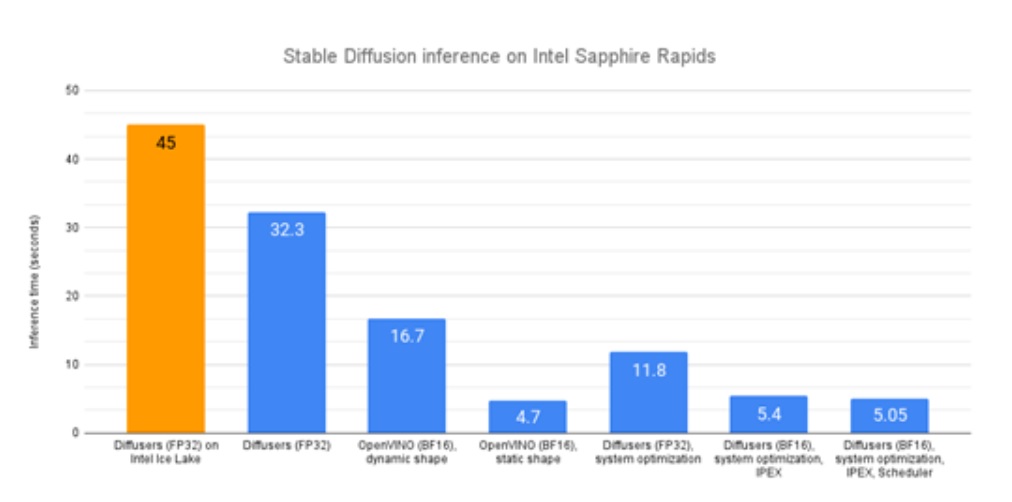
圖5:Huggingface不同後端在CPU上的性能比較。
專案網址:https://github.com/huggingface/optimum-intel

圖6:只需2行程式碼替換就可利用OpenVINO部署文本分類任務。
此外Optimum-Intel也可以支援在Intel GPU上部署模型:

圖7:在Intel GPU上載入Huggingface模型。
Optimum Intel和OpenVINO 安裝方式如下:
$ pip install optimum[openvino]
在部署Stable Diffusion模型任務時,我們也只需要將StableDiffusion Pipeline替換為OVStableDiffusionPipeline即可。
from optimum.intel.openvino import OVStableDiffusionPipeline
ov_pipe = OVStableDiffusionPipeline.from_pretrained(model_id, export=True)
除此之外,Optimum-Intel還導入了對OpenVINO模型壓縮工具NNCF元件的支援。NNCF目前可以支援 Post-training static quantization (訓練後量化)和 Quantization-aware training (訓練感知量化)兩種模型壓縮模式,前者需要導入少量不帶標籤的樣本資料,來校準模型輸入的資料分佈,客製量化參數,後者則可以在保證模型準確性的情況下,進行量化重訓練。將HuggingFace中豐富的資料集資源作為校準資料或是重訓練資料,我們可以輕鬆完成對預訓練模型的Int8線上量化與推論,具體範例如圖8:

圖8:後訓練量化範例。
方案二:使用 OpenVINO runtime 進行部署
當然 Optimum-Intel 庫在提供極大便捷性的同時,也有一定的不足,例如對於新模型的支援存在一定的滯後性,並且對HuggingFace庫存在依賴性,因此第二種方案就是將 HuggingFace 的預訓練模型直接匯出為 ONNX 格式,再直接通過 OpenVINO 的原生推論介面重構整個pipeline,以此來達到部署程式碼輕量化,以及對新模型pipeline enable的目的。
OpenVINO五歲了!想知道更多最新版本2023.0的新功能與亮點,歡迎免費報名參加OpenVINO™ DevCon 線上系列講座,聽Intel技術專家開講並展示應用範例!
這裡提供3種匯出模型的方案:
- 使用Optimum-Intel介面直接匯出OpenVINO的IR格式模型:

圖9:使用Optimum-Intel直接匯出IR檔。
- 使用 HuggingFace 原生工具匯出 ONNX 格式模型:
HuggingFace的部分程式庫中是包含ONNX模型匯出工具的,以Transformer程式庫為例,我們可以參考其官方文件實現ONNX模型的匯出。
使用方法請見:https://huggingface.co/docs/transformers/index
- 使用PyTorch底層介面匯出ONNX格式模型:
如果是Optimum-Intel還不支援的模型,同時HuggingFace庫也沒有提供模型匯出工具的話,我們就要透過基礎訓練框架對其進行解析。由於Transformer等程式庫的底層是基於PyTorch框架進行構建,如何從PyTorch框架匯出ONNX模型的通用方法,可以參考官方的說明文件:
這裡我們再以 ControlNet 的姿態任務作為範例,從本文背景章節中的任務流程圖中我們不難發現ControlNet任務是基於多個模型構建而成,其HuggingFace測試程式碼可以分為以下幾個部分:
專案倉庫:https://huggingface.co/lllyasviel/sd-controlnet-openpose
1) 載入並構建OpenPose模型任務
openpose = OpenposeDetector.from_pretrained('lllyasviel/ControlNet')
2) 執行OpenPose推論任務,獲得人體關鍵點結構
image = openpose(image)
3) 載入並構建ControlNet模型任務
controlnet = ControlNetModel.from_pretrained(
"lllyasviel/sd-controlnet-openpose", torch_dtype=torch.float16
)
4) 下載並構建Stable Diffusion系列模型任務,並將ControlNet物件整合到StableDiffusion原始的pipeline中
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, safety_checker=None, torch_dtype=torch.float16
)
5) 執行整個pipeline取得生成的結果影像
image = pipe("chef in the kitchen", image,
num_inference_steps=20).images[0]
可以看到在1、3、4任務步驟中構建了模型的下載,因此我們需要對這些介面進行「逆向工程」,找出其中的PyTorch模型物件,並利用PyTorch自帶的ONNX轉換介面torch.onnx.export(model, (dummy_input, ), ‘model.onnx’),將這些物件匯出為ONNX格式,在這個介面最重要的兩個參數分別為 torch.nn.Module模型物件model,和一組類比的輸入資料dummy_input,由 PyTorch是支援動態的input shape,輸入沒有固定的shape,因此我們需要根據實際情況,找到每個模型的input shape,然後再創建模擬輸入資料。在這個過程這裡我們分別需要找到這個幾個介面所對應程式庫的原始碼,再進行重構:
1) OpenPose 模組
首先是人體姿態關鍵點檢測任務的程式碼倉庫:
https://github.com/patrickvonplaten/controlnet_aux/tree/master/src/controlnet_aux/open_pose
透過解析推論時實際調用的模型物件,我們可以瞭解到,這個模型的PyTorch物件類為class bodypose_model(nn.Module),輸入為NCHW格式的影像tensor,而它controlnet_aux庫推論過程中抽象出的實例是 OpenposeDetector.body_estimation.model,因此我們可以透過以下方法將它匯出為ONNX格式:
torch.onnx.export(openpose.body_estimation.model, torch.zeros([1, 3, 184, 136]), OPENPOSE_ONNX_PATH)
2) StableDiffusionControlNetPipeline 模組
我們可以把第3和第4步中用到的模型放在一起來看:
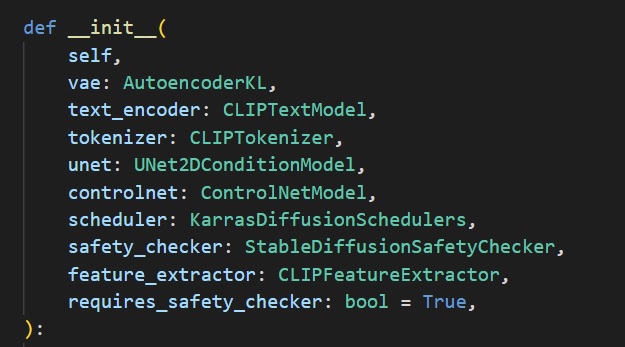
圖10:StableDiffusionControlNetPipeline物件初始化參數。
可以看到在構建StableDiffusionControlNetPipeline的時候,會初始化4個 torch.nn.Module模型物件,分別是vae、text_encoder、unet、controlnet,因此我們在重構任務的過程中也需要手動匯出這幾個模型物件。此時你必須知道每一個模型的input shape,以此來構建模擬輸入資料,這裡比較常規的做法是:直接調取pipeline中的成員函數進行單個模型的推論任務作為torch.onnx.export函數中的model實例。
pipe.text_encoder(
uncond_input.input_ids.to(device),
attention_mask=attention_mask,
)
遍歷StableDiffusionControlNetPipeline的 _ _call_ _ 函數,我們也不難發現,多個模型之間存在串聯關係。因此我們也可以模仿StableDiffusionControlNetPipeline的調用任務,構建自己的pipeline,並透過執行這個pipeline找到每個模型的input shape。簡單來說就是先重構任務,再匯出模型:
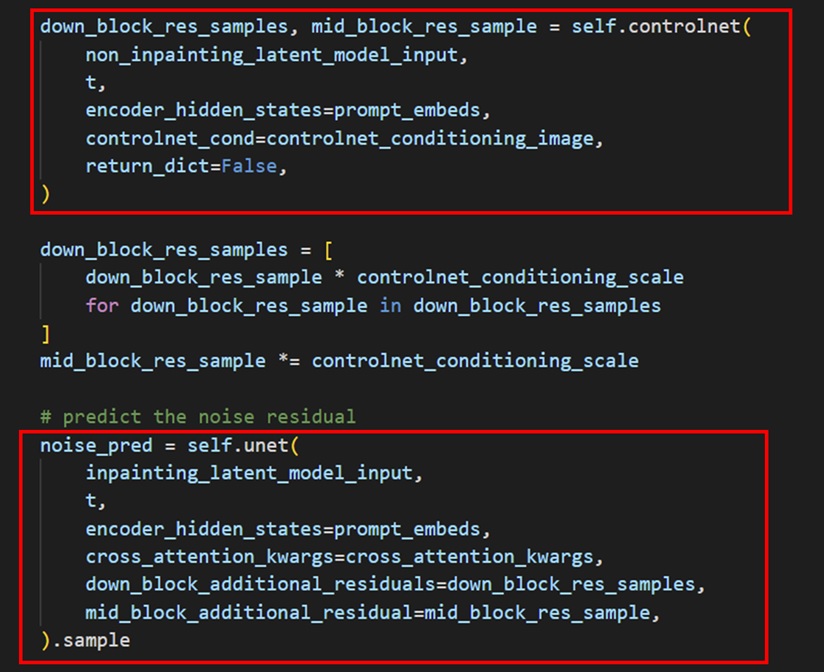
圖11:ControlNet和Unet串聯。
為了更方便地搜尋出每個模型的輸入資料維度資訊,我們也可以為每個模型單獨創建一個「鉤子」腳本,用於替換原始任務中的推論部分的程式碼,「鉤取」原始任務的輸入資料結構。以ControlNet模型為例。
3) 查詢原始模型的輸入參數,以對應到實際任務的輸入參數。
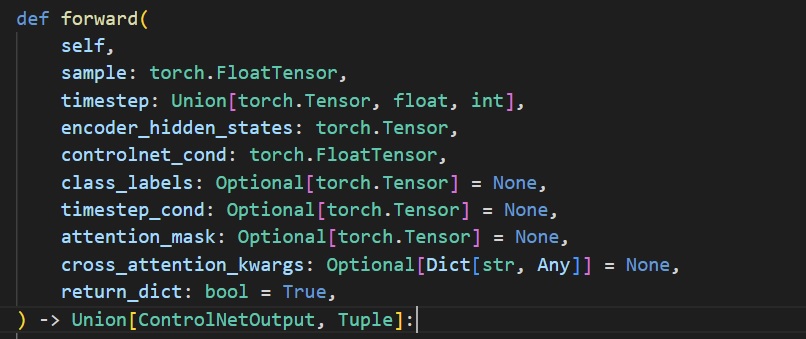
4) 創建鉤子腳本
class controlnet_input_shape¬¬(object):
def __init__(self, model) -> None:
super().__init__()
self.model = model
self.dtype = model.dtype
def __call__(self,latent_model_input,
t,
encoder_hidden_states,
controlnet_cond,
return_dict):
print("sample:" + str(latent_model_input.shape),
"timestep:" + str(t.shape),
"encoder_hidden_states:" + str(encoder_hidden_states.shape),
"controlnet_cond:" + str(controlnet_cond.shape))
def to(self, device):
self.model.to(device)
5) 將鉤子物件替換原來的controlnet模型物件,並執行原始的pipeline任務
hooker = controlnet_input_shape(pipe.controlnet)
pipe.controlnet = hooker
6) 執行結果
$ “sample:torch.Size([2, 4, 96, 64]) timestep:torch.Size([]) encoder_hidden_states:torch.Size([2, 77, 768]) controlnet_cond:torch.Size([2, 3, 768, 512])”
模型匯出以及重構部分的完整程式碼可以參考以下範例,這裡有一點需要額外注意的是,因為OpenVINO 的推論介面只支援numpy資料登錄,而Diffuers的範例任務是以Torch Tensor進行資料傳遞,所以這裡建議開發用numpy來重新實現模型的前後處理任務,或是在OpenVINO 模型輸入和輸入側提前完成格式轉換。
總結
作為當下最紅的預訓練模型倉庫之一,HuggingFace 可以幫助我們快速實現 AIGC 類模型的部署。透過導入Optimum-Intel以及OpenVINO工具套件,開發者可以更進一步提升這個預訓練模型在英特爾平台上的任務性能。以下是這兩種方案的優缺點比較:

- 輕薄型筆電OK!利用OpenVINO部署Phi-3.5「全家餐」 - 2024/09/20
- LangChain框架已正式支援OpenVINO! - 2024/06/12
- 如何在Windows平台呼叫NPU部署深度學習模型 - 2024/03/04
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


