作者:CAVEDU 教育團隊
本篇文章靈感發想自 MIT 的 Dukietown,如同先前在部落格分享過的自駕車文章, 機器人小車已經具備辨識行走及辨識路牌的能力, 接下來我們希望可以更進一步地提升辨識能力到物件偵測(Object Detection), 並加入一個新的類別(小鴨,在這裡作為路人)、設法偵測到牠的位置, 再搭配 Intel RealSense 深度攝影機量測距離, 藉此來讓小車知道前方是否能通行。
環境準備
本文所使用的嵌入式控制板是研揚的 UP Squared、深度學習推論裝置為 Intel Movidius NCS 2,如下圖所示:

(圖片來源:CAVEDU 提供)
以及本文的主角深度攝影機 Intel RealSense D435!

(圖片來源:CAVEDU 提供)
由於本次的實測涵括訓練深度學習模型的部份,建議手邊有一台具 GPU 的電腦,這邊是以一台有 GTX 1060 的筆電為例,其作業系統為 Linux;另外,也請下載本次的範例程式,並記得切換工作目錄到 agv-object-detection。
收集資料
路牌的資料可以從我們公開的資料下載,接著為了要能夠辨識出路人(也就是小鴨),需要手動先拍攝幾張不同角度的小鴨照片;本範例約略整理出左轉路牌、右轉路牌、停止號誌及黃色小鴨四個類別數張後, 整理出如下的檔案格式:
agv-object-detection/data/images
├── duck-001.jpg
├── duck-002.jpg
├── duck-003.jpg
…
標記資料
有了影像資料後,為了能夠訓練深度學習模型學會 Object Detection, 還必須手動 label 這些資料,在此所使用的軟體是著名的開源軟體 labelimg,接著我們就標記每張圖片的框框及其對應的類別,如下圖所示:
(圖片來源:CAVEDU 提供)
之後存成檔案格式如下:
agv-object-detection/data/annotations
├── duck-001.xml
├── duck-002.xml
├── duck-003.xml
…
準備 Tensorflow Object Detection
我們所使用的深度學習框架為 Google 的 Tensorflow,然後為了能夠使用 Tensorflow 的 Object Detection API, 我們必須先下載函式庫到前面的 agv-object-detection 這個資料夾底下,而由於函式庫相當大,下載可能會需要一些時間;下載完成後,請輸入以下的指令完成安裝 Python 相依套件:
sudo pip3 install -r requirements.txt
再輸入以下的指令完成初始設定:
make init
準備 Protobuf:
make compile_protobuf
訓練模型
首先請先下載預訓練的模型:
make download_model
轉換前面資料的格式:
Step 1. 從 xml 檔轉成 csv 檔
make xml_to_csv
Step 2. 存成 Tensorflow 指定的 tfrecord 格式
make generate_tfrecord
完成後就會看到在 data 的資料夾下會有一個叫做 data.record 的檔案囉!
agv-object-detection/data
└─── data.record
接著就可以開始訓練了!
make train
(圖片來源:CAVEDU 提供)
訓練過程中出現的 loss 代表誤差度多少,越低代表學得越好;以這個範例而言,如果時間充足的話,盡量讓 loss 壓到 1.0 以下,但其實 1~2 之間就蠻夠用了。如果想要解析訓練的過程,可以輸入以下的指令來啟動 Tensorboard:
make log_train
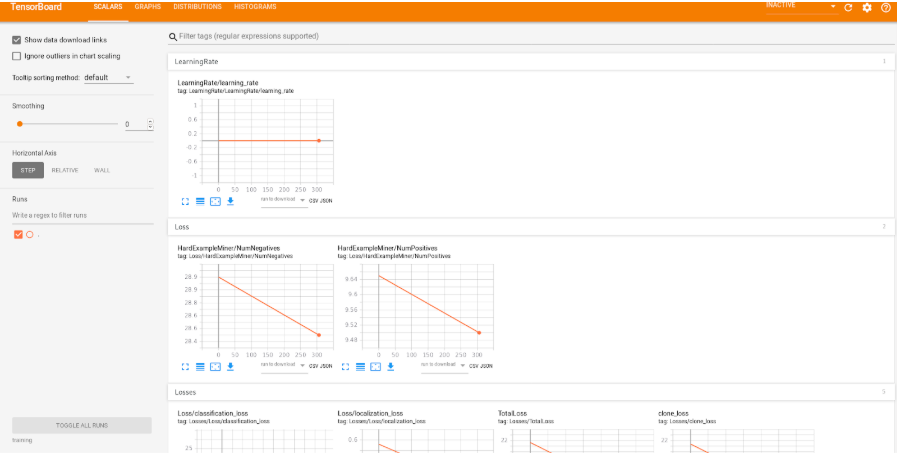
(圖片來源:CAVEDU 提供)
訓練完後,為了要能夠轉成 OpenVINO 的形式,我們必須輸出我們訓練完後的模型:
make export
(圖片來源:CAVEDU 提供)
最後將 inference-graphs 這個資料夾搬到 UP Squared 上面,注意到 UP Squared 上面也必須下載本文章的專案:
Step 1. 在 UP2 上下載 agv-object-detection
Step 2. 將 inference-graphs 放到 agv-object-detection 中,並切換工作目錄到 agv-object-detection 中
cd agv-object-detection
檔案形式如下:
agv-object-detection/inference-graphs
├── checkpoint
├── frozen_inference_graph.pb
├── model.ckpt.data-00000-of-00001
├── model.ckpt.index
├── model.ckpt.meta
├── pipeline.config
└── saved_model
├── saved_model.pb
└── variables
接下來會用到 OpenVINO 的 Model Optimizer,關於怎麼在 UP2 上面安裝 OpenVINO 可以參考先前的文章。請輸入以下的指令來將 Tensorflow 的模型轉成 OpenVINO 的格式:
make model_optimize
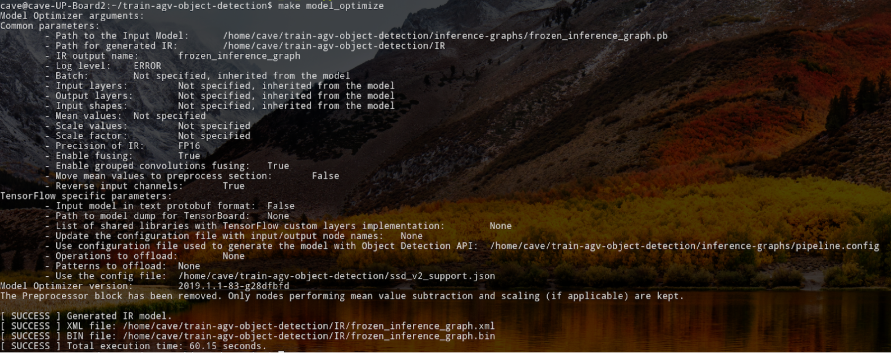
(圖片來源:CAVEDU 提供)
轉譯成功後程式會將結果存在 IR 這個資料夾底下:
agv-object-detection/IR
├── frozen_inference_graph.bin
├── frozen_inference_graph.mapping
└── frozen_inference_graph.xml
安裝 RealSense 函式庫
為了要在 UP 2 上面執行 RealSense,我們必須先安裝一些基本套件:
Step.1 加入新的 apt key
sudo apt-key adv --keyserver keys.gnupg.net --recv-key C8B3A55A6F3EFCDE || sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv-key C8B3A55A6F3EFCDE

(圖片來源:CAVEDU 提供)
Step 2. 新增 Repo
sudo add-apt-repository "deb http://realsense-hw-public.s3.amazonaws.com/Debian/apt-repo bionic main" -u
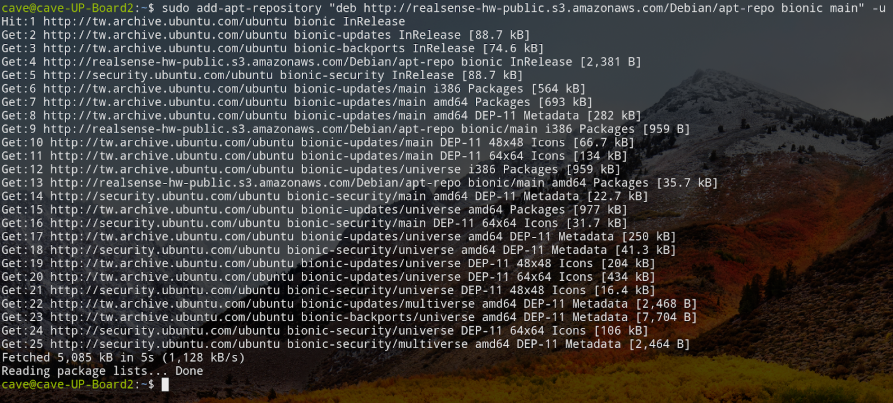
(圖片來源:CAVEDU 提供)
Step. 3 安裝 librealsense
sudo apt-get install librealsense2-dkms librealsense2-utils

(圖片來源:CAVEDU 提供)
Step 4. 確認 Kernel 是否更新
modinfo uvcvideo | grep realsense
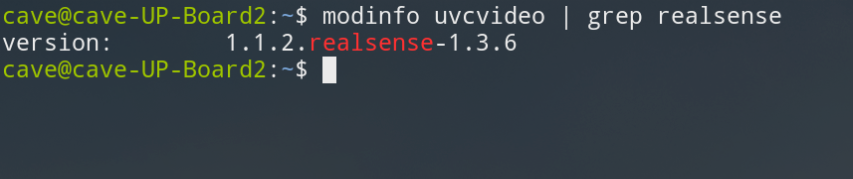
(圖片來源:CAVEDU 提供)
Step 5. 接上 Intel RealSense,執行以下程式看看是否正常運作
realsense-viewer
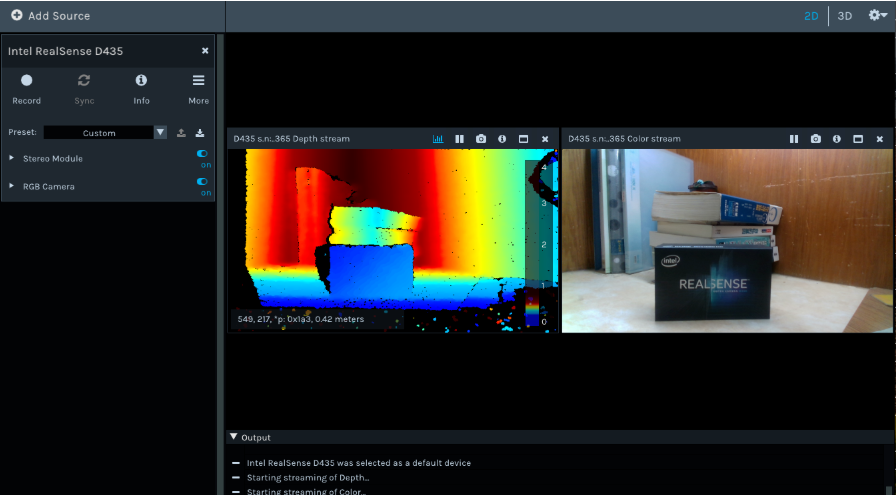
(圖片來源:CAVEDU 提供)
Demo
如果已經有 IR 資料夾底下的 .xml 與 .bin 檔,就可以輸入以下的指令來跑一下 Demo。
make demo

(圖片來源:CAVEDU 提供)
參考資料
(責任編輯:賴佩萱)

- 【CAVEDU講堂】micro:bit V2使用TCS34725顏色感測器模組方法 - 2025/06/27
- 【CAVEDU講堂】NVIDIA Jetson AI Lab 大解密!範例與系統需求介紹 - 2024/10/08
- 【CAVEDU講堂】Google DeepMind使用大語言模型LLM提示詞來產生你的機器人操作程式碼 - 2024/07/30
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


