作者:歐敏銓
想像一下,你對居家幫傭說:「幫我把桌上那玻璃杯中快過期的牛奶倒掉。」這句話人類幫傭馬上就理解了,但對機器人來說,目前還是一句複雜難解的謎語。
它必須先「看見」杯子(視覺),理解「過期」與「倒到哪裏」的語意邏輯(語言),最後精準地控制電機馬達,在不捏碎杯子的情況下完成傾倒(動作)。這就是目前 AI 領域最前瞻的挑戰——VLA 模型(Vision-Language-Action Models)。
然而,訓練這樣一個「懂人話」機器人大腦需要海量的失敗經驗。如果把機器人帶回家中再練習,你的桌面可能都是牛奶、杯子也碎了滿地。為了避免這些災難在現實中發生,科學家們創造了一個「數位練功房」——Sim2Real(從模擬到現實的遷移)。以下用「人話」來解釋一下,這是怎麼一回事:
第一章:在「夢境」中進化
VLA 模型如 RT-2 或 OpenVLA,其參數規模動輒數十億。要餵飽這些吞噬數據的巨獸,僅靠人類手把手教導(遙控操作)是不可能的。
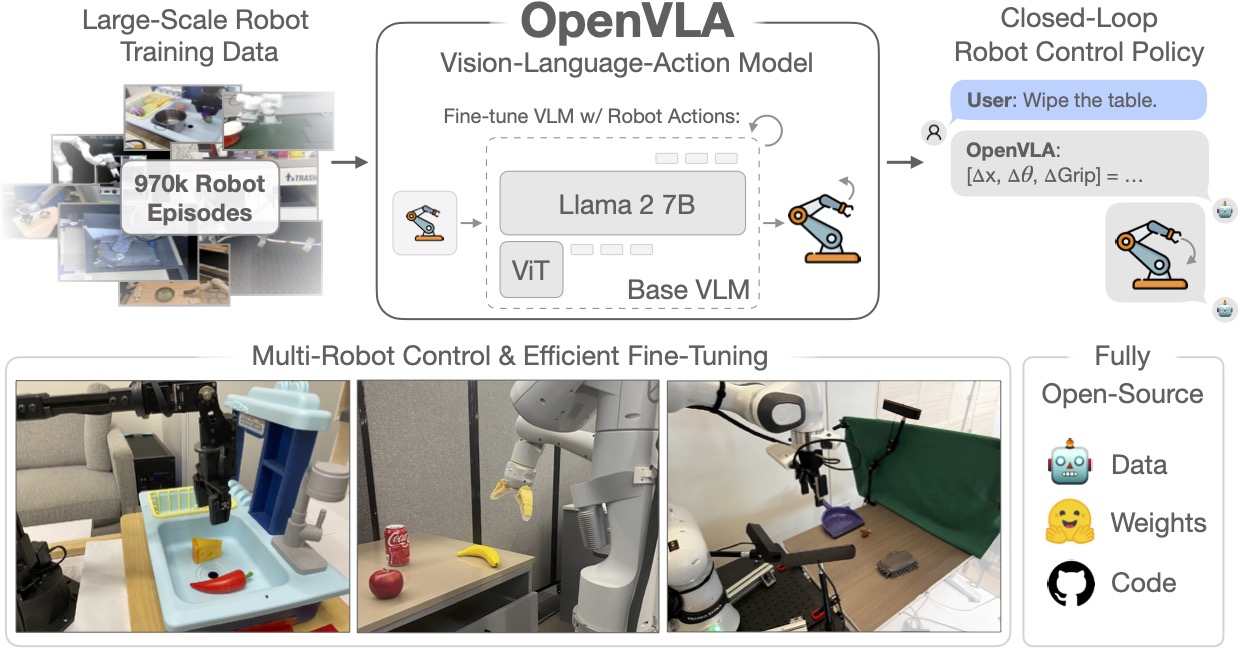
1. 虛擬世界的「分身之術」
在現實中,一名有經驗的技術員帶領機器人練習一次抓取需要 30 秒;但在 NVIDIA Isaac Lab 這樣的Sim2Real 模擬平台中,我們可以同時開啟 10,000 個「平行時空」。機器人的虛擬分身們在虛擬世界中可以 24 小時不間斷地抓取、跌倒、重來。在人類喝一杯咖啡的時間裡,虛擬機器人已經完成了現實中需要幾年才能累積的經驗。
2. 零成本的「破壞權利」
Sim2Real 賦予了 AI 犯錯的自由。在仿真器裡,機器人可以捏爆一萬個虛擬杯子,撞倒一千次虛擬牆壁,而科學家只需要按下一個 Reset 鍵,一切又完好如初。這種「試錯成本為零」的特性,是 VLA 邁向通用的無痛捷徑。
第二章:縮小「現實與虛擬」的鴻溝
在虛擬世界試錯,聽起來很理想,但事實上,在電腦裡練好的機器人,一到現實世界就顯得「手忙腳亂」!這就是所謂的 Sim2Real Gap。為了填補這個鴻溝,科學家們開發了三大核心技術:
1. 視覺泛化:場景的「變妝秀」
讓電腦裡的機器人感受現實世界的瞬息萬變,科學家利用 域隨機化(Domain Randomization),在模擬環境中瘋狂更換背景、光照和桌子材質。這讓 VLA 模型學會:無論桌子是木頭的還是不鏽鋼的,無論陽光是刺眼還是昏暗,它都能認出那是「杯子」。
2. 物理一致性:感受「現實力量」的細微差別
虛擬物體往往太過「完美」。Sim2Real 工具必須精確模擬摩擦力、重力與電機延遲。透過系統辨識,模型學會了在抓起一顆雞蛋與抓起一顆重球時,馬達輸出的扭矩該有何不同。
3. 長程規劃:大腦的「因果鏈條」
VLA 不僅要動手,還要動腦。在模擬環境中,模型可以練習複雜的因果任務,例如:「如果冰箱門沒完全打開,我就不能去拿牛奶」。這種邏輯判斷在虛擬世界中可以透過強化學習(RL)快速對齊,讓機器人不再是死板的機器,而是有邏輯的助手。
第三章:最後的 1% 鴻溝
儘管工具越來越強大,但 Sim2Real 仍有其極限。觸覺的細微反饋、複雜化學環境的模擬,以及真實傳感器的隨機噪聲,依然是科學家們攻堅的目標。
目前的趨勢是利用 3DGS (3D Gaussian Splatting) 等技術,直接將現實場景「掃描」進虛擬世界,實現所謂的「Real-to-Sim-to-Real」閉環。這意味著,未來的機器人只要在你的房間裡轉一圈,它就能在虛擬的你家練習一萬次,然後瞬間學會如何幫你摺好那堆亂糟糟的衣服!
結語
Sim2Real 是 VLA 模型通往現實世界的必經之路。它讓機器人在「夢境」中修煉,在現實中覺醒。當我們看著機器人優雅地避開障礙、穩穩地遞上一杯熱茶時,可別輕忽了,為了這一個動作,在虛擬世界中它已練習了無數個寒暑。
想進一步掌握Sim2Real模擬器的開發工具該如何選擇,請續讀下文:2026 機器人VLA模型 Sim2Real模擬器大點兵
》延伸閱讀:
OpenVLA 官方專案:了解目前最強大的開源視覺-語言-動作模型是如何運作
NVIDIA Isaac Lab 文檔:深入探索如何利用 GPU 加速機器人學習
DeepMind RT-2 研究報告:看 Google 如何將大語言模型(LLM)與機器人動作結合

- 【產業剖析】全球機器人生態系競合趨勢 - 2026/06/22
- 【產業剖析】人形機器人火熱背後的現實難題 - 2026/06/15
- 【COMPUTEX 2026】以「具身智慧界Android」為定位的韓國Circulus - 2026/06/05
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


