當機器人不再只是精準執行指令的自動化工具,而開始「理解」環境、語言與目的,我們距離真正的 Physical AI 還有多遠?
在機器人學習(Robotic Learning)與 Physical AI 快速交會的此刻,兩個名字頻繁出現在研究論文與產業簡報中:ACT(Action Chunking with Transformers),以及 NVIDIA GR00T N1。它們都使用 Transformer 架構處理動作序列,也都試圖解決機器人控制長期以來的核心難題——動作穩定性、任務泛化與真實世界的不確定性。然而,若深入拆解,這兩條技術路線其實代表了截然不同的哲學選擇。
ACT 像是一名專注於單一技能、反覆練到極致的工匠;而 GR00T N1 則更接近一個試圖建立「通用智慧」的系統工程,目標是讓機器人能跨任務、跨硬體、跨情境運作。兩者並非誰取代誰,而是共同描繪出 Physical AI 的現階段版圖。
從一步一動到「動作分塊」:機器人控制的關鍵轉折
傳統的機器人控制模型,大多採取「一步一預測」的方式:模型在每一個時間點,根據當前感測輸入,預測下一個馬達指令。這種方法在理論上簡潔,但在實務中極易累積誤差,只要某一步偏離軌跡,後續動作就可能全面崩壞。
ACT 與 GR00T N1 都採用了「Action Chunking」的概念,將控制單位從單一步驟,提升為一段連續動作序列。這樣的設計,讓機器人的行為不再像是即時反射,而更接近人類在腦中預先規劃好一小段動作後再執行,整體流暢度與穩定性因此大幅提升。
但在這個共同基礎之上,兩者很快走向不同的分岔點。
ACT:把模仿學習做到極致的「肌肉記憶模型」
ACT 的核心精神非常明確:用最少的模型複雜度,換取最高的操控精度與穩定性。它主要應用於模仿學習(Imitation Learning)場景,透過人類示範資料,學習在特定任務中的最佳動作分佈。
為了避免模型在面對真實世界雜訊時過於脆弱,ACT 採用了 Conditional Variational Autoencoder(CVAE) 架構,刻意保留人類示範中的隨機性與多樣性。這讓模型即使在視覺遮擋、感測誤差或物體位置略有偏移的情況下,仍能輸出合理且穩定的動作序列。

在實務上,ACT 非常適合用於如穿針引線、摺衣服、插接頭等「高精度、低語意」的操控任務。它不需要理解「為什麼要這麼做」,只需要把「怎麼做」做到近乎完美。這種特性,也讓 ACT 能在相對低成本的硬體上運作,成為許多研究實驗室與新創團隊的首選方案。
》延伸閱讀:邁向通用:ACT如何讓機器人「預見未來」動作?
然而,這種「肌肉記憶型智慧」也有其天花板。ACT 對任務的理解高度綁定於訓練資料,一旦情境稍有變化,或任務語意本身不同,它幾乎無法自行推論下一步該怎麼做。
GR00T N1:試圖建立「會思考的機器人控制系統」
如果說 ACT 是在既定任務中追求極致,那麼 NVIDIA GR00T N1 的野心,則是打造一個通用型機器人基礎模型(Foundation Model)。它不只關心馬達該怎麼轉,更關心「現在要完成的是什麼任務」。
GR00T N1 的一大特色,在於引入了類似人類認知科學中的 System 1 / System 2 雙系統架構。
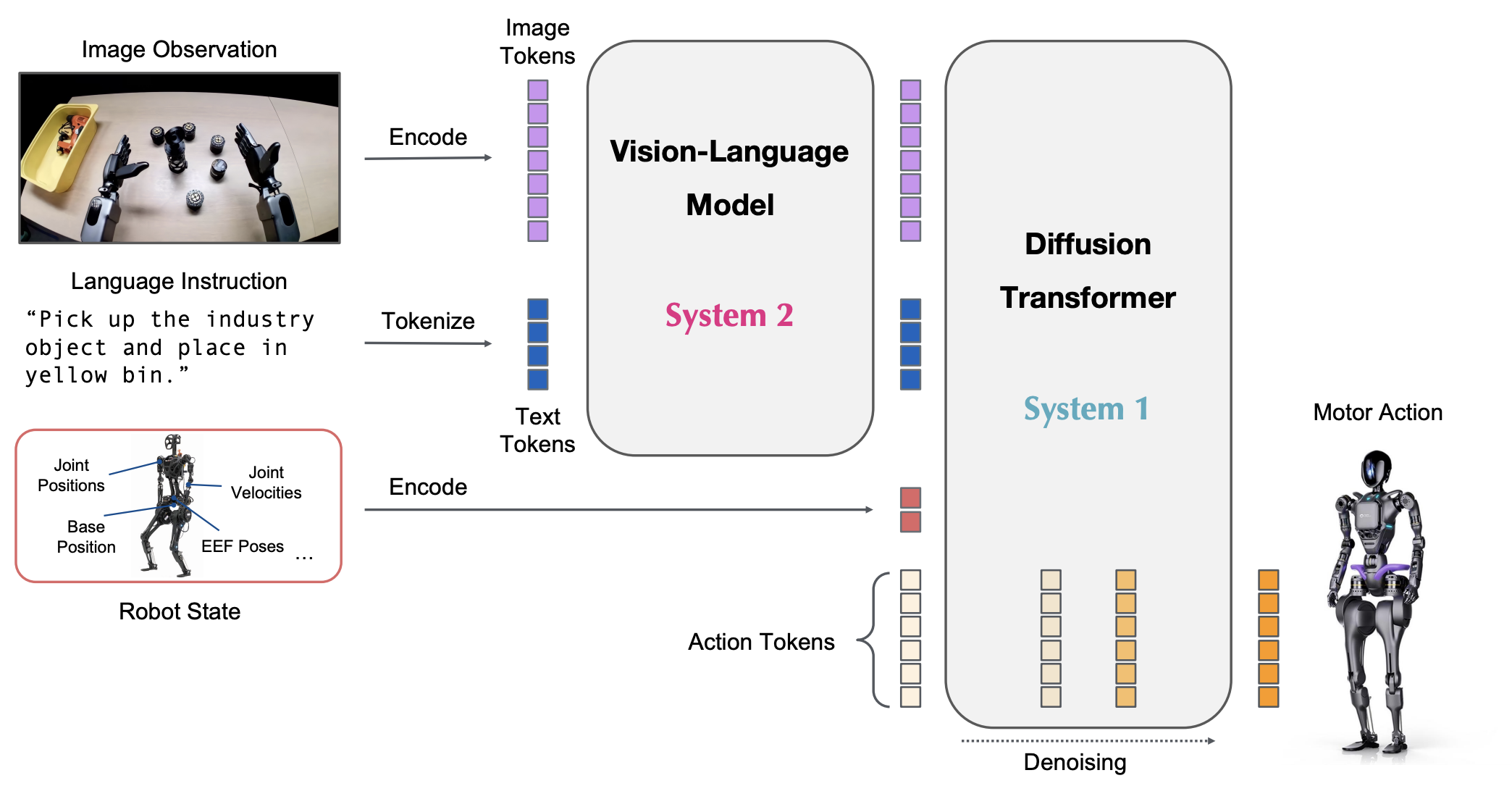
在高層的 System 2 中,GR00T N1 結合了大型視覺語言模型(VLM),負責理解人類語言指令、解析場景語意,並進行長程規劃。當人類說出「去拿桌上的藍色杯子」,這一層會先決定目標物、規劃行動順序,甚至在必要時進行重規劃。
而在低層的 System 1,則由 Diffusion Transformer(DiT) 負責即時的動作生成與避障控制。與 CVAE 相比,擴散模型在高維度、連續動作空間中的表現更為穩健,特別適合處理「同一任務存在多種可行解法」的情境。
這樣的分工,使 GR00T N1 不只是反應環境,而是能在「理解—規劃—執行」之間形成閉環,朝向真正的自主行動邁進。
》延伸閱讀:Physical AI近了!如何打造「通用又專才」的機器人?
數據規模,決定了泛化能力的邊界
ACT 與 GR00T N1 在泛化能力上的差異,本質上來自於訓練資料規模與來源的不同。
ACT 多半依賴特定任務的人類示範資料,泛化能力主要體現在對雜訊的容忍,而非任務本身的遷移。教會它開抽屜,並不代表它能理解開門的概念。
相對地,GR00T N1 的訓練資料橫跨數萬小時的人類影片、模擬環境與多機器人平台,這讓模型在語言與視覺層面產生了「湧現能力」。它不需要為每一個新任務重新蒐集示範,而是能透過語言指令,將既有技能重新組合、遷移到不同硬體與場景中。
這正是 Foundation Model 在機器人領域最被期待、也最具挑戰性的地方。
結語:兩條路線,一個未來
ACT 與 NVIDIA GR00T N1 並非競爭關係,而是代表了 Physical AI 在不同階段、不同應用場景下的最佳解法。
如果你是一名開發者,希望在有限資源下,快速讓機器人把一件事做到極致,那麼 ACT 仍是當前最成熟、最務實的選擇;而如果你的目標,是讓機器人真正走入人類生活,理解語言、因應變化、在未知環境中自主行動,那麼 GR00T N1 所指向的方向,幾乎是無可迴避的未來。
若你正考慮將這些模型應用於特定機器人硬體或研究專案中,從 ACT 的精準操控起步,逐步銜接 GR00T 式的高階認知,或許正是當下最務實、也最具前瞻性的策略。
表一 ACT vs. GR001 N1技術異同對照表
| 比較項目 | ACT (Action Chunking with Transformers) | NVIDIA GR00T N1 |
| 核心定位 | 輕量化、高效的模仿學習演算法 | 通用型機器人視覺-語言-動作 (VLA) 基礎模型 |
| 底層架構 | CVAE (變分自編碼器) + Transformer | 雙系統架構 (VLM 導航 + Diffusion Transformer) |
| 動作生成 | Action Chunking:預測一段時間內的動作塊 | Flow-matching Diffusion:基於擴散模型的流匹配 |
| 推理能力 | 無語言理解能力 (通常僅依賴視覺與關節狀態) | 強大的 VLM (Vision-Language Model) 推理能力 |
| 跨平台性 | 針對特定機器人訓練 (如 ALOHA) | 跨體現性 (Cross-embodiment):支持不同品牌人形機器人 |
| 數據來源 | 少量的高質量人類操作數據 (10–50 條) | 海量網路影片、合成數據 (Omniverse) 及真實數據 |
| 更新頻率 | 通常較低 (10–20Hz) | 高頻閉環控制 (100Hz+) |
(責任編輯:歐敏銓)

- Real-to-Sim-to-Real:探討SLAM、Digital Twin與Physical AI的共生關係 - 2026/06/26
- 跨越Sim-to-Real鴻溝:韓國Movensys提出WMX ROS2軟體定義解方 - 2026/06/25
- 東擎科技發表全新工業級強固邊緣AIoT系統平台 - 2026/06/25
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


