本文整理本刊VLM及VLA的技術導讀文章,剖析這兩個AI模型技術的迭代串連及對未來的影響力。
2025 年的 AI 世界,正站在一個關鍵分水嶺上。從 ChatGPT 掀起的語言革命,到 Gemini、GPT-4V、LLaVA 等多模態模型的崛起,AI 不再只是虛擬空間的對話者,而逐步走向具備理解力與行動力的「實體智能」。這場變革的主角,正是近兩年最受矚目的新技術方向——VLA(Vision-Language-Action)模型。
VLA 的誕生,標誌著 AI 正從「理解世界」邁向「行動於世界」的新篇章。這場從理解到行動的跨越,不僅是演算法的突破,更是一場智能形態的革命。
AI 理解力的奠基者:VLM 登場
回望這場技術演進的起點,要從 VLM(Vision-Language Model)談起。這類多模態模型讓 AI 第一次能夠真正地「看懂世界」——把影像與文字的資訊整合起來,進行語義推理與認知。
想像一張圖片:一個小孩在草地上追著紅色的球跑。傳統的影像辨識模型只能告訴你「這是一張有小孩和球的照片」;但 VLM 則能理解動作與意圖,推測出「孩子正在玩球」。這種跨模態語意理解能力,使得 AI 在感知世界時不再零散,而能建立連貫的情境意識。
Google 的 Gemini、Meta 的 LLaVA、OpenAI 的 GPT-4V 等系統,正是在此基礎上成長起來的「多模態智能」。它們能理解圖片、影片與語音指令間的邏輯關係,成為後續 VLA 演化的奠基核心。若說 LLM(大型語言模型)賦予 AI 思考與溝通的能力,那麼 VLM 便是讓 AI 「張開雙眼」理解現實的第一步。
》延伸閱讀:
VLM再進化:VLA讓AI從感知到行動
然而,僅僅理解並不足以構成智能。真正的智慧,來自「行動」。當 AI 能夠在真實世界中根據語言指令完成任務、對環境變化做出反應,那才是它從知識邁向實踐的關鍵跨越。這正是 VLA(視覺–語言–動作)模型想達成的目標。
VLA 將視覺感知(Vision)、語言理解(Language)與動作決策(Action)三者整合為一體,使 AI 不僅能「聽懂」人類指令,還能「看清」環境並據此採取行動。
舉例來說,當你對一台機器人說:「請把桌上的紅色杯子遞給我。」VLA 模型便會歷經三個階段的推理:(1) 它先理解語句中的關鍵目標「紅色杯子」,(2) 接著在視覺輸入中辨識出正確物件,(3) 最後規劃手臂路徑與角度,完成精準的抓取與遞送。
這不只是資料處理的過程,而是一場語言、感知與運動控制之間的即時交響。
VLA 的三階段演進
短短三年,VLA 技術便歷經三次顯著演化,從理論構想走向現實應用。
第一階段是初期實驗期。VLA 嘗試以「後期融合」(Late Fusion)方式將視覺與語言模型串接,但各模態特徵之間對齊困難,導致模型在真實世界中常出現誤判或錯動的情況——例如誤抓錯物件或反應延遲。
第二階段進入「物理與記憶」的覺醒。研究者將3D重建、物理推理及場景記憶模組納入,使 AI 能「記得」環境變化與障礙物位置,進而完成連續行動,如自駕車的避障決策或智慧工廠中的多工操作。這是 AI 首次展現「長時理解」與「跨步行動」的能力。
第三階段,則是泛化與規模化的成熟期。代表性成果如 OpenVLA、NVIDIA GR00T N1,主打「一次訓練、多場景遷移」的能力。這意味著,一套模型若學會在廚房搬運物品,也能無痛轉換到醫療、製造或倉儲場景中使用。這正是 VLA 向「通用行動智能」邁進的里程碑。
》延伸閱讀:讓AI掌握行動力的關鍵:VLA模型
架構革命:AI 的大腦與小腦
技術進化的關鍵不只是演算法調整,更在於架構革新。
以 NVIDIA GR00T N1 為例,這套系統採「雙層智能」設計:高階規劃層相當於大腦,負責理解指令與決策目標;低階反應層則像小腦,專注於運動控制與即時反饋。這樣的分層架構讓機器人既能靈活應變,也能長期規劃。
》延伸閱讀:為人形機器人設計的開放式基礎模型: GR00T N1
相比之下,OpenVLA 採取「早期融合」與共享空間設計,讓視覺與語言訊號在同一向量空間中協同運算。這種同步推理機制能加快反應速度,並提升多模態對齊的精準度。
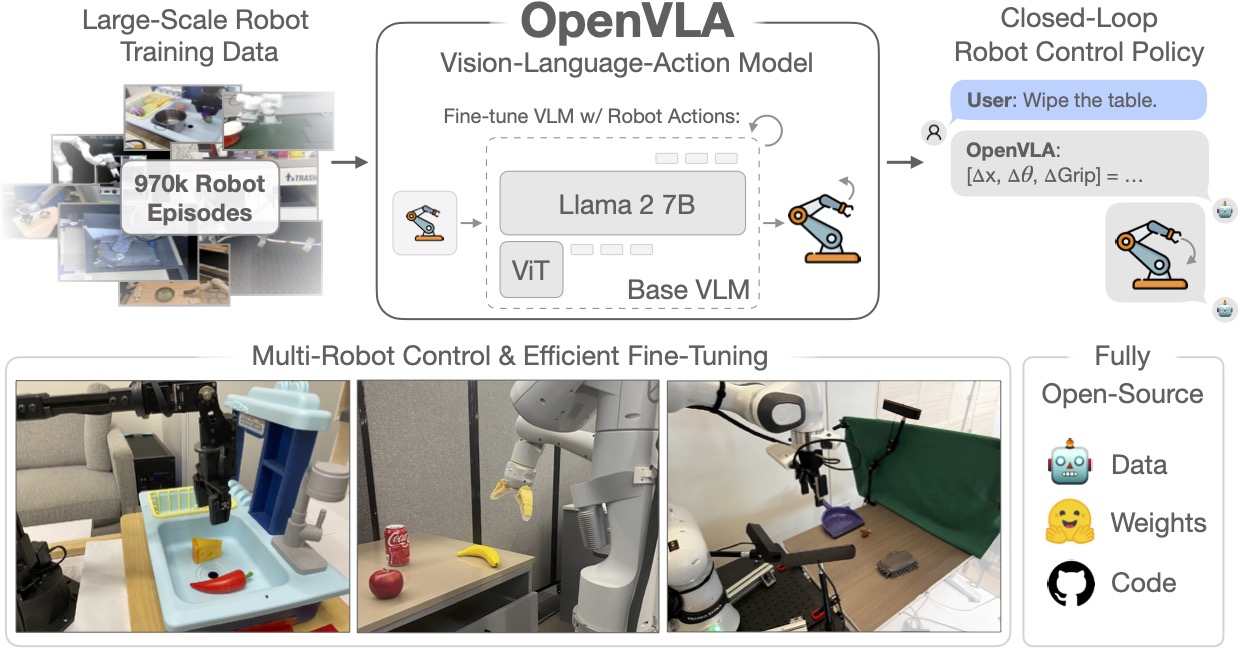
簡言之,VLA 不只是「AI加機械」,而是「語言即控制、感知即行動」的智能整體。
資料困境與模擬革命
儘管進步迅猛,VLA 仍有多項待克服的挑戰。
VLA 的成功離不開海量的多模態資料。要訓練一個能看懂、聽懂又會動的模型,需要成千上萬筆影像、語音與機器人動作軌跡。然而,這樣的真實資料蒐集成本高昂,也存在風險與倫理限制。
因此,「Sim2Real(模擬到真實)」技術成為突破口。研究者讓機器人在虛擬環境中進行數百萬次互動訓練——搬箱子、開門、避障、操作工具——再將所得知識遷移到真實世界。
這不僅加速學習,還讓 AI 能在無風險的模擬世界中獲得真實經驗。Meta、DeepMind、以及 Google Robotics 都已將此方法納入訓練流程,使得 VLA 的行為決策更具魯棒性與泛化力。
另一個主要難題是模態對齊與融合精度。在複雜場景下,如光影變化、遮擋物或多物件干擾,模型容易誤解語意與空間關係。其次,行動策略訓練極為耗費時間與算力,一次完整的策略學習可能需數百萬次回饋循環。
此外,VLA 模型在不同任務間常出現「干擾效應」:學會抓取可能會忘記分類,學會導航又可能影響對話反應,這種「虛假遺忘」現象令訓練更加艱難。
面對這些挑戰,研究者正導入 LoRA 精簡微調技術、混合專家(MoE)架構、以及 分階段多模態訓練策略(如 ChatVLA),讓不同模組各司其職而不互相干擾。這些新思路正在重塑 AI 訓練方式,使其更輕量、更具擴展性。
AI 的行動力時代
如今,VLA 已不再只是研究室裡的理論。它正在滲入機器人、車輛、製造與智慧生活的每一個角落。
在智慧製造領域,VLA 成為「具身智能機器人」的核心中樞,協助機器自主辨識產品、判斷流程、甚至調整組裝順序。
在家庭服務場景中,像 Figure AI 的 Helix 模型,就能理解人類語音指令、分解複雜任務並與其他機器人協同作業——它不再只是一台單機,而是能與夥伴協作的智慧生態。
》延伸閱讀:Helix Model:讓人形機器人真的懂你!
汽車產業也正快速採用 VLA。無論是自動駕駛還是駕駛輔助系統,VLA 模型能即時融合語音與環境資訊,在「請切換車道」或「避開前方障礙」等情境下做出自然且精準的反應。
這樣的技術正在讓汽車「聽得懂駕駛的話,也看得懂前方的路」。
隨著 AI 加速器晶片、嵌入式 AI 平台與開放資料集的普及,VLA 的應用場景將從大型伺服器走入邊緣設備與日常生活。未來三到五年,我們可能看到:
- 工廠機械人能自行協調搬運與檢測流程。
- 車載 AI 能主動解讀駕駛意圖與道路語境。
- 家庭助理機器人能理解口語命令,協助照護、清潔或備餐。
正如一位業界研究者所言:「AI學會行動,才算真正走入我們的生活。」VLA 正是這段進化的起點。
讓AI真正「動」起來
回望這場從 LLM 到 VLA 的技術演化,我們可以清楚看到 AI 正從「語言智慧」跨越至「具身智慧(Embodied Intelligence)」。
這是一條從理解到行動、從虛擬到現實的軌跡。當 AI 不再只是螢幕上的助理,而成為能在世界中感知、推理、行動的智能體時,人類文明的生產方式、生活型態與創造邏輯,將被重新定義。
》延伸閱讀(Source: MakerPRO):
【實作案例】以OpenVINO實現VLM、MLLM導入產業應用
NVIDIA提出的人形機器人開發關鍵技術:Eagle-2 VLM模型、DexMimicGen、Jetson Thor

- 機器人開發環境邁入「標準化、開源化、端對端」新時代 - 2026/07/21
- 人形機器人站上手術檯動刀的最後一哩路 - 2026/07/13
- 【產業剖析】全球機器人生態系競合趨勢 - 2026/06/22
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


