作者:沈綸銘(Odin Shen),Arm首席解決方案架構師
技術挑戰:延遲、資料分散與隱私限制
在許多企業環境中,工程師與技術人員需要快速取得資訊,經常必須查找內部文件,例如硬體規格、專案手冊與技術說明文件。然而,這些資料往往分散在不同系統或位置,使得傳統搜尋方式效率不彰。
這些文件多半屬於機密或專有資料,因此無法交由外部雲端服務或公開的大型語言模型(LLM)進行處理。關鍵挑戰在於:如何在裝置端直接建置一套由 AI 驅動的檢索系統,能在確保安全與隱私的前提下,提供快速且具有情境脈絡、準確的答案?
架構解方:在DGX Spark上實作異質式檢索增強生成
在現代AI工作流程中,GPU常被視為預設的主要運算主力。不過,AI推論流程通常包含多個相互獨立的階段,而每個階段的運算需求並不相同。GPU擅長處理大規模矩陣運算;相較之下,像是查詢解析、資料檢索與向量編碼等階段,則更需要低延遲且具高度彈性的處理能力。
這正是DGX Spark 桌機平台(採用 Grace–Blackwell GB10 Superchip架構)展現其關鍵優勢之處。
- 異質運算(Heterogeneous Compute):結合 NVIDIA Blackwell 系列 GPU 與高效能的 Arm CPU 複合架構(包含Cortex-X 與Cortex-A 核心)。其中,Arm CPU負責處理RAG流水線中對延遲高度敏感的文字嵌入階段。
- 統一記憶體(Unified Memory):系統採用統一記憶體架構,使CPU與GPU能共享同一個記憶體空間。
憑藉這樣的硬體基礎與軟體堆疊(包括 FAISS 與 llama.cpp),我們展示了CPU如何從被動的前處理角色,轉變為主動、以低延遲為核心最佳化的運算引擎,進而驅動即時回應的本地 AI 應用。
架構與設計:在桌機級硬體上本地運作RAG系統
檢索增強生成(Retrieval-Augmented Generation,RAG)是一種非常適合用來查詢私有、裝置端資料的AI架構。這其中包括內部合約、尚未公開的技術文件,以及其他未納入公開大型語言模型、或不適合透過外部雲端服務處理的敏感資料。RAG的核心優勢在於,能將這類封閉領域的知識轉換為可搜尋的向量資料庫,使語言模型得以在本地裝置端生成回應,讓使用者在取得AI輔助答案的同時,仍能確保資料隱私與所有權不受影響。
為了實際展示這套機制的運作方式,我們選用了一組實用且熟悉的資料集:涵蓋Raspberry Pi的完整硬體規格、程式設計指南與應用說明文件。這些文件往往篇幅冗長、格式不一,使用者經常需要花費大量時間翻閱PDF,才能找到如GPIO 腳位配置、電壓臨界值或預設狀態等細節。
透過在地化的 RAG 系統,使用者可以直接以自然語言提出問題。系統會從本地文件資料庫中檢索相關段落,並交由語言模型生成具備完整上下文、準確且有依據的回應。整體查詢流程可歸納為三個步驟:
- 使用者輸入自然語言查詢
- 系統在本地文件資料庫中搜尋相關內容
- 語言模型根據檢索到的上下文生成自然語言回應
在平台選擇上,我們採用了MSI EdgeXpert 推出的DGX Spark桌機系統,其基於Grace-Blackwell GB10 Superchip架構打造,並具備適合邊緣AI開發的散熱與低噪音優勢。
該系統結合NVIDIA Blackwell系列GPU與高效能的Arm CPU複合架構(包含Cortex-X與Cortex-A核心),並支援統一記憶體架構,使CPU與GPU能共享同一個記憶體空間。這樣的設計可有效降低資料傳輸延遲,減少運算單元間的協調成本。
在這樣的硬體基礎之上,我們以下列軟體堆疊實作RAG系統:
- FAISS:用於高效率的向量搜尋
- llama.cpp:負責執行量化後的語言模型推論
- Python:用於資料處理,以及協調整體流水線邏輯
透過在llama.cpp上執行量化語言模型、並使用預先建立好的FAISS 向量索引,整個系統不需要進行任何模型重新訓練即可運作。一旦文件完成載入並嵌入,就能部署一套完全在裝置端運行、以RAG為基礎的查詢助理。這樣的架構在效能、開發彈性與資料隱私方面都具備明確的實務價值,也證明了桌機級AI平台具備支援真實應用的可行性。
在RAG架構到位之後,我們接著聚焦於系統設計中的一項關鍵決策:嵌入階段應該在哪裡、以及如何執行,才能達到最佳效能與即時回應表現。
為何在RAG流水線中CPU是更聰明的選擇
在RAG架構中,第一個階段會將使用者輸入的查詢轉換為向量,這個過程稱為文字嵌入(text embedding)。這一步對整體系統的準確性至關重要,但其運算特性與GPU所擅長的大規模矩陣運算其實截然不同。
在實務情境中,使用者查詢通常只是簡短的片語或單一句子,使得嵌入運算成為一項低吞吐量、對延遲高度敏感的任務。若將這類小批量工作交由GPU處理,反而會帶來不必要的額外負擔,例如排程延遲、PCIe資料傳輸延遲,以及運算資源使用效率不佳等問題。
也正因如此,我們選擇將嵌入階段放在CPU上執行,這也進一步凸顯DGX Spark平台中採用Arm架構SoC的高度適配性。
DGX Spark採用異質化的CPU架構,整合了高效能的Arm Cortex-X與Cortex-A 核心。其中,Cortex-X系列支援高時脈、低延遲運作,在兼顧能源效率的同時,提供優異的多執行緒效能,使其特別適合處理如嵌入這類小批量、記憶體密集型的推論任務。
當搭配Int8量化的嵌入模型時,這些 CPU 能在低功耗條件下維持穩定的效能表現,確保回應迅速、互動體驗流暢。對於桌機級或邊緣端的查詢系統而言,Arm Cortex-X 架構針對即時搜尋與推論等延遲敏感型工作負載進行最佳化,在高單執行緒效能與優異的能源效率之間取得良好平衡。
為了說明這項設計選擇為何如此重要,以下將透過一個真實世界的例子,展示嵌入品質如何直接影響系統輸出的可靠性。
有憑有據的答案:透過RAG消除AI幻覺
如前述,RAG的第一個階段是文字嵌入,而一開始嵌入的精準度,將直接影響整個RAG系統輸出的品質。更重要的是,RAG正是為了解決AI幻覺(hallucination)問題而設計。當語言模型缺乏特定情境,或無法存取最新、正確的文件資料時,往往會生成聽起來合理、實際卻缺乏事實依據的回應;在技術與企業應用領域中,這將帶來相當嚴重的風險。
因此我們針對一個常見的開發者提問,並以內部技術文件為基礎,進行了一項可控制實驗。
情境一:未搭載RAG系統的LLM
查詢問題:「Raspberry Pi 4上,哪些GPIO腳位預設配置了下拉電阻?」
如果在未使用RAG或向量檢索的情況下,直接將原始查詢送入Meta-Llama-3.1-8B模型,其結果清楚顯示缺乏依據的LLM輸出有多麼不穩定:
實驗一:模型將GPIO 1、3、5、7、9、11…列為具有下拉電阻的腳位。
實驗二(相同查詢):模型回傳了一份完全不同的清單(例如GPIO 3、5、7、8…),甚至重新分類部分腳位(例如先前被標示為上拉的GPIO 4,這次卻被歸類為下拉)。
觀察結果:儘管兩次實驗產生了彼此矛盾、且就事實上並不正確的答案,模型在兩種情況下都表現得同樣自信。

這類行為其實並不罕見。當語言模型缺乏明確的上下文,或無法存取最新的文件資料時,往往會產生聽起來合理、實則缺乏依據的回應。這個問題被稱為AI幻覺,在技術應用領域中可能帶來相當嚴重的風險。
情境二:在採用RAG架構下執行相同查詢
查詢問題:「Raspberry Pi 4 上,哪些GPIO腳位預設配置了下拉電阻?」
當以完全相同的查詢透過我們的本地RAG系統執行時,結果則截然不同:
事實正確:回應內容與官方文件一致,並經過驗證確認無誤。
明確來源:系統明確引用資料來源,指出對應的章節與表格編號(例如:「表 5:功耗說明…」),確保答案具備可查證依據。
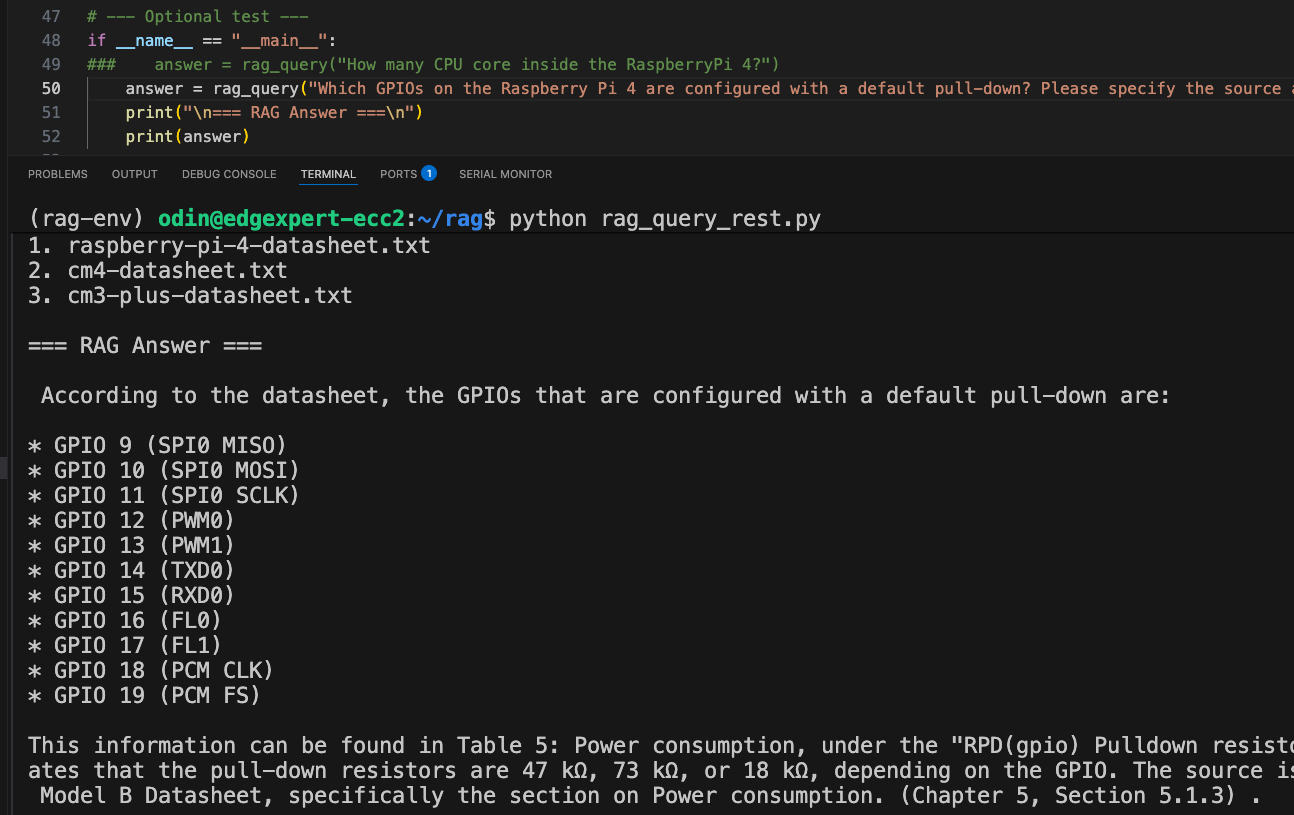
這凸顯了RAG架構的核心優勢之一:系統不再仰賴語言模型僅根據訓練分布去「猜測」答案,而是將每一次回應都建立在實際檢索到、以文件為基礎的證據之上。這種做法有助於避免幻覺問題,並確保模型提供的是真實、可驗證的資訊。
從效能角度來看,由Arm CPU負責執行的嵌入階段,處理時間通常落在70至90毫秒之間,完全符合互動式系統對低延遲的需求。
架構優勢:統一記憶體
在傳統系統中,由CPU產生的資料必須透過PCIe等互連介面,傳輸至GPU的專屬記憶體空間,這個過程不僅會增加延遲,也會耗用寶貴的頻寬。相較之下,統一記憶體架構讓CPU與GPU能共享同一個記憶體空間,使GPU可以直接存取由CPU產生的輸出向量,而無需進行明確的資料複製或傳輸。這樣可打造出更快速、更高效率的運算管線,在每一毫秒都至關重要的即時AI推論場景中,效益尤為顯著。
下表呈現的是RAG各階段記憶體佔用情況,即是在DGX Spark平台上驗證此效率優勢的量化證據:
| 階段 | 階段說明 | 觀測到DRAM 佔用概數 | 關鍵技術解讀 |
| 閒置狀態(啟動前) | 系統尚未啟動 RAG 任務 | ~3.5 GiB | 作業系統及後台服務的基礎記憶體佔用 |
| 模型載入 | 啟動 llama-server,載入 LLaMA 3.1 8B Q8_0 模型 | ~12 GiB | 模型權重直接對映到統一記憶體,CPU 與 GPU 可共用存取 |
| 嵌入階段 | 使用 E5-base-v2 模型,在 CPU 上對文本分塊進行嵌入 | ~13 GiB | CPU 生成的張量資料直接寫入。共用 DRAM,無需額外複製。 |
| 查詢執行 | FAISS 檢索,以及透過 llama.cpp 的基於 GPU 的生成 | ~14 GiB | GPU 直接存取共用張量,消除 PCIe 複製開銷 |
| 任務完成後 | 查詢結束,部分快取釋放。 | ~12 GiB | 模型仍常駐記憶體,
為下一次查詢做好準備 |
RAG 各執行階段的 DRAM 使用情況
這份跨越各個階段的記憶體使用分析,提供了寶貴的觀察結果,顯示系統在統一記憶體環境下,如何有效地進行資源管理。
請注意:所有效能與記憶體使用量的觀察結果,皆來自我們在DGX Spark上的測試環境與工作負載設定。實際表現可能會因系統配置與模型規模不同而有所差異。不過,這份剖析結果可作為規劃本地AI工作負載、並預估可預期記憶體擴展行為的實用參考。
這些觀察結果帶出了幾項關鍵洞察:
- 各流水線階段的記憶體使用穩定:DRAM使用量在系統閒置時約為5 GiB,於 RAG 高峰運作期間提升至約14 GiB,整體僅增加約 10GiB,顯示出高度有效的記憶體控管與資源使用效率。
- 模型與向量資料可持續駐留於記憶體中:在模型載入、記憶體用量上升至約 12 GiB 之後,即使連續執行多次查詢,記憶體使用量仍維持穩定,證實模型與嵌入並未自 DRAM 中被釋放,可在無需重新載入的情況下重複使用。
- CPU 與 GPU 轉換期間的記憶體變動極小:在嵌入階段,記憶體使用量約為 13 GiB,進入 GPU 生成階段後僅小幅增加至 14 GiB。這顯示嵌入資料與提示(prompt)張量可由 GPU 直接使用,過程中未發生顯著的重新配置或 PCIe 資料傳輸。
這些數據進一步強化了統一記憶體在AI系統設計中的價值。統一記憶體不僅簡化了流水線整合,也讓桌機級與邊緣平台能實現可預期、低延遲的推論行為。
這些研究結果驗證了 統一記憶體在 AI 系統架構設計中的關鍵性。除了簡化開發流程之外,它也能在整個執行過程中提供穩定且高效率的記憶體行為,成為在桌機級與邊緣級平台實現 AI 推論的重要基礎。
開發者可在Arm Learning Path中找到這篇部落格文章所提供的完整範例與逐步操作說明。無論是打造概念驗證(PoC),或規劃正式的產品部署,這些模組化教學都能提供一條快速且可靠的實作途徑,協助開發者實際運用RAG工作流程,並在Arm架構平台上充分發揮CPU高效率嵌入運算與統一記憶體的優勢。
結論:CPU是AI系統設計中不可或缺的關鍵協作者
在DGX Spark上建置並運作本地RAG系統,重塑我們對CPU在現代AI架構中角色的理解。
在許多真實世界的AI應用中,特別是以檢索、搜尋與自然語言互動為核心的場景,大量的運算工作其實發生在語言模型推論之外。像是查詢處理、文字嵌入、文件檢索與提示組合等任務,正是CPU 最能發揮優勢的領域。
DGX Spark上的實作驗證了兩項關鍵的架構要素:
- 以最佳化延遲為優先的運算設計:高效能的Arm CPU複合架構(Cortex-X / Cortex-A核心),被證實是處理低吞吐量、延遲敏感型嵌入階段的最佳選擇。這種做法避免了將小批量工作排程到GPU所帶來的額外負擔,確保系統能維持快速回應。
- 無縫的運算協作:統一記憶體架構讓CPU產生的資料可被GPU直接存取,無需手動進行資料傳輸或同步。這種協作方式消除了效能瓶頸,使各運算單元都能專注於其最合適的工作內容。
- 最終結果是:CPU不再只是被動的前處理器,而是成為一個主動、以低延遲為核心最佳化的運算引擎,對桌機級平台上的推論即時性相當重要。
隨著AI持續朝向裝置端與邊緣部署發展,CPU的角色——尤其是高效率的Arm架構——將變得更加核心。本專案也顯示,DGX Spark不只是硬體展示平台,而是一個能支援真實世界原型開發的完整解決方案。
現在正是開發者重新思考CPU定位的關鍵時刻,將其視為打造低延遲、兼顧隱私的未來AI系統中不可或缺的核心推動者。
(參考原文:Rethinking the role of CPUs in AI: A practical RAG implementation on DGX Spark;本文中文版由作者Odin Shen校閱)
- 【Arm的AI世界】運用ExecuTorch與Arm SME2加速裝置端機器學習推論 - 2026/03/18
- 【Arm的AI世界】重新思考CPU在AI中的角色:在DGX Spark上實作實用的RAG - 2026/02/12
- 【Arm的AI世界】運用本地端LLM推論重塑智慧家庭的隱私與延遲表現 - 2026/01/19
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


