作者:歐敏銓
在看似受限的嵌入式系統領域,如今可以做出聲音辨識、手勢控制、異常偵測,甚至環境預測。下一步,MCU、MPU將能把AI「嵌入」到任何感測節點、工業機械或穿戴式設備中,讓智慧更貼近現場、無所不在。

對嵌入式工程師而言,AI 是一個想用又不敢用的新領域。它能讓感測器的資料更有用,讓得到資料的嵌入式系統能預測、理解、甚至自我調整;在此同時,開發者又需精打細算系統的「算力」——模型太大、耗能太高、延遲太長都行不通。尤其在那些只有KB級記憶體、靠電池供電的小裝置上,要讓 AI 上身,幾乎是不可能的任務。
「邊緣AI」正是在這樣的矛盾中誕生的。它不仰賴雲端,而是在終端就直接進行推理與判斷。這意味著更快的反應、更低的延遲,以及更強的資料隱私。對工廠偵測系統、自動化農業監控、穿戴式健康裝置等應用來說,這不只是效率問題,而是安全與信任的基礎。
然而,要讓AI在這些微型設備上運作,不只是把雲端模型「搬下來」那麼簡單,開發者需要克服「AI微型化」的重重挑戰。
量身定做輕量化AI架構
想像你正在開發一款智慧手錶,只能提供 512KB 記憶體與極低功耗限制。即使是最基本的卷積神經網路(CNN),在雲端運行時都能輕鬆耗盡幾百 MB 的資源。那該怎麼辦?
嵌入式工程師會先精準定義「微型」的範圍:像 STM32、ESP32、Nordic nRF 這些微控制器(MCU),都屬於這個範疇。它們沒有 GPU,也沒有神經網路加速器(NPU);要讓它們跑 AI,就像讓腳踏車拖一輛卡車上山——除非你懂得調整載重。
這時,模型設計就成為決勝關鍵。過去幾年,AI 社群針對 MCU 專門開發出幾種輕量化架構,例如 MobileNet、MCUNet 與 FOMO(Faster Objects, More Objects)。
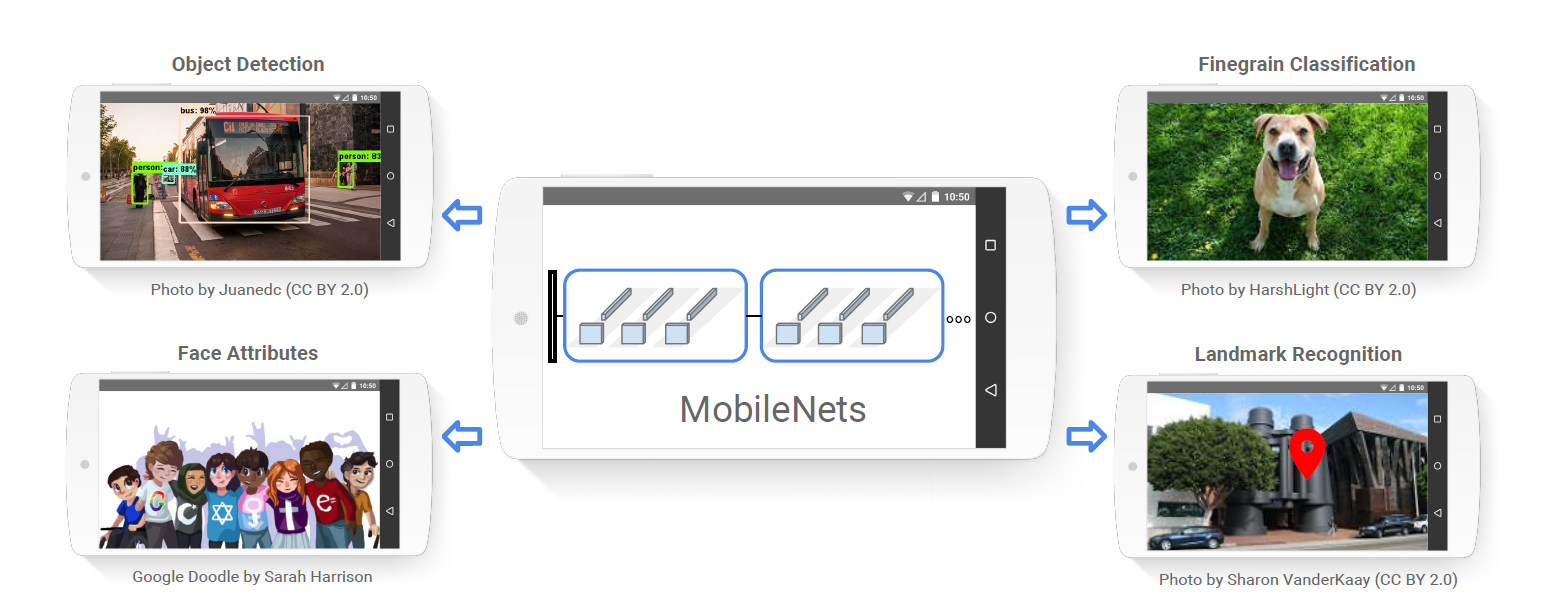
MobileNet由Google的研究團隊於2017年開發,旨在為行動和嵌入式設備設計高效的捲積神經網路(CNN)(source)

MCUNet能大帳縮減AI模型所需的記憶體及儲存空間(source)
FOMO 是 Edge Impulse 團隊的代表作之一,它放棄了傳統的「邊界框」偵測,而改用「質心追蹤」,讓模型能以更小的尺寸辨識更多目標物。結果是什麼?一個僅 150KB 的模型,就能即時偵測多個物體,功耗還低得驚人。
從量化到剪枝的瘦身策略
在邊緣AI的世界裡,「每一個位元都算數」。因此,模型最佳化的首要手段,就是量化(Quantization)——將原本以 32 位元浮點數儲存的權重與激活值,轉換成 8 位元整數,甚至更低。
結果往往令人驚訝:模型大小縮小四倍、推理速度加快一倍、功耗下降近 60%。
換句話說,你用更少的電,換來更快的智慧。
這樣的轉換當然有代價。模型精準度可能略降,某些硬體也不支援所有格式。但在多數應用中,這樣的權衡非常划算。TensorFlow Lite Micro、Edge Impulse 等開發框架,都已將量化功能內建其中,只需幾個指令,就能完成。
接著是剪枝(Pruning)。這是一種「減脂」技術,透過移除貢獻度低的神經元或權重,進一步降低模型負擔。
有開發者形容它像「幫神經網路斷捨離」:保留關鍵特徵,捨棄多餘參數。結合壓縮與權重共享等技巧,甚至能讓模型在不降效能的情況下再縮小一半。有的工具還能提供自動剪枝與量化的流程,讓開發者在幾分鐘內測試多種版本,選出最平衡的效能組合。
目標硬體最佳化的重要性
「別以為模型在一顆晶片上跑得快,就能在另一顆上跑得動。」這是嵌入式開發的鐵律。
每款晶片的記憶體結構、時脈頻率與架構差異都可能影響AI效能。這時候,目標硬體最佳化(Hardware-aware Optimization) 便顯得至關重要。
以 Nordic nRF52 為例,若能針對其 BLE SoC 特性調整資料流與快取存取路徑,推理速度可提升 30%;而在 STM32H7 上,善用內建 DSP 指令集更能有效加速向量運算。
如果裝置具備 NPU(神經處理單元) 或 DSP 加速器,那就更具優勢。善用Edge Impulse 這類工具直接產生支援這些加速器的模型部署檔,開發者就不必親自調整底層指令集。
這樣的自動化讓開發者可以更專注於應用層的創意發想——例如讓智慧農田的感測節點能「聽」出害蟲聲音,或讓工廠設備在異常震動時「自己」停機。
效能指標的真實意義
在開始最佳化之前,懂得測量才是關鍵。邊緣AI不像雲端那樣能隨時更新,因此「基準測試」是開發過程中不可或缺的一步,而延遲(Latency)、記憶體使用量(RAM/ROM)、功耗(Power Consumption)這三個維度是評估模型是否可行的基石。
「提早量測,提早修正。」一位使用者在開發者社群中分享,他的環境感測模型透過早期量化分析,最終讓系統運行時間從 12 小時提升至 4 天,僅因提前修正了一個記憶體配置問題。
多數Edge AI開發工具提供效能指標的相關功能,例如Edge Impulse 的 Eon Compiler 就像開發者的儀表板——能即時顯示模型在特定 MCU 上的推理時間與能耗,幫助工程師在設計階段就預測瓶頸。下表列舉Eon Compiler 與STM32Cube.AI(ST)、eIQ Toolkit(NXP)、Edge AI Studio(TI)等工具的效能指標功能比較。
| 工具 | 推理時間顯示 | 記憶體/Flash使用 | 功耗/能耗儀表支援 | 儀表板式整合程度 |
|---|---|---|---|---|
| EON Compiler | ✅ 明確支援 | ✅ 明確支援 | 部分(需外部測量) | 高(為開發者提供儀表板介面) |
| STM32Cube.AI | ✅ 支援 | ✅ 支援 | ✅ 支援但需額外硬體量測 | 中—需較多手動設定 |
| eIQ Toolkit | ✅ 部分支援 | ✅ 支援 | 功耗顯示不明確 | 較低—需自行設定量測流程 |
| Edge AI Studio | ✅ 支援(推理時間估估) | 部分支援 | 功耗顯示不明確 | 中—有介面提示,但儀表板功能或許較簡化 |
(資料整理:ChatGPT)
部署才是真正的考驗
模型優化只是戰鬥的一半,真正的挑戰在於部署。在雲端環境中,更新與修正都輕而易舉,但在邊緣設備上,一個 bug 可能意味著上千台感測節點得重新刷寫。
因此,成功的邊緣AI部署必須具備三項特質:
- 容錯性(Fault-tolerance)——模型能在噪音或缺損資料下保持穩定。
- 自適應性(Adaptability)——能隨環境變化持續運作。
- 可更新性(OTA-ready)——在必要時能透過無線更新進行版本升級。
如何快速、方便地在雲端完成模型訓練、壓縮、轉換,並匯出至自己開發中的開發板上,實現「從模型到韌體」的整個流程,也是選擇開發工具的評估要件。當然,現在MCU廠商大多已有自己的AI工具供客戶使用,但泛用型(如Edge Impulse)或開源(如LiteRT for Microcontrollers 、deepC、TVM)則有跨平台開發的彈性,各有千秋。
小結
在看似受限的嵌入式系統領域,工程師們正在挑戰「微型智慧」革命。一顆不到 10 美元的晶片,如今可以做出聲音辨識、手勢控制、異常偵測,甚至環境預測。下一步,MCU、MPU將能把AI「嵌入」到任何感測節點、工業機械或穿戴式設備中,讓智慧更貼近現場、無所不在。
》延伸閱讀:
- 7 Tips for Optimizing AI Models for Tiny Devices
- Edge Impulse 技術文件與開發者部落格
- TensorFlow Lite Micro(TFLM)開發指南/資源
- MCUNet: Tiny Deep Learning on IoT Devices(MIT CSAIL 等機構研究報告)

- 當仿生靈巧手遇見Physical AI:四間頂尖開發單位介紹 - 2026/02/13
- 戰略決策AI進化:Palantir AIP如何導入LLM重塑現代戰場指令 - 2026/02/11
- 解析Skydio如何建立無人機AI空戰視覺 - 2026/02/06
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!