如果你想在英特爾(Intel)架構硬體(配備CPU、GPU或NPU)上嘗試經過預先最佳化的生成式AI (GenAI)模型,這是能讓它們以最高速度運作的方法之一,而且不需要任何編寫程式的技巧。
一個明顯的趨勢是,各種AI模型正進駐PC,而且它們變得更聰明、快速、強大;幸運的是,身為開發者,使用像是llama.cpp或Ollama等工具,以模型服務軟體來管理模型也變得越來越容易。然而,仍會有一個問題:如何在不同的硬體加速器──例如英特爾的GPU或NPU──上讓模型發揮最佳效能?
本文將介紹能解決此問題的關鍵解決方案之一:OpenVINO™ Model Server (OVMS)。
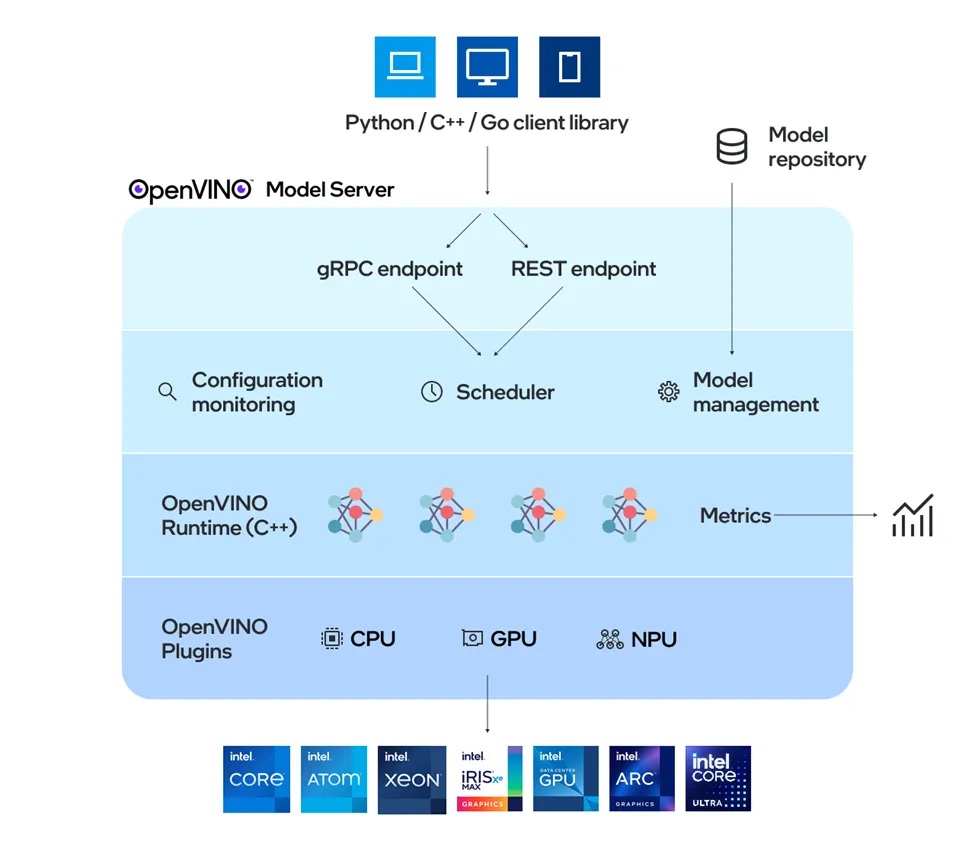
OpenVINO™ Model Server架構圖
OpenVINO Model Server是什麼?
OpenVINO Model Server (模型伺服器)是一種用於模型服務的高效能系統,以C++語言實現,具備可擴充性,並針對在英特爾架構上的部署進行了最佳化。它使用OpenAI和Cohere API支援生成式AI模型,並使用KServe和TensorFlow Serving API支援傳統AI模型。在後端,它採用OpenVINO Runtime執行快速推論;推論服務是透過gRPC或REST API提供,並因此簡化了新演算法和AI實驗的部署。
這對開發者意味著什麼?代表會有一個專用伺服器來託管模型,並以端點的形式與伺服器互動。其關鍵優勢在於,它可以處理下載、載入和執行這些模型的複雜流程,讓開發者得以專注在使用者體驗與解決商業層面的問題。
最棒的是,從邊緣到雲端,可以使用相同的統一API輕鬆地擴充節點以支援不同模型。這帶來了靈活性,尤其是在runtime運用代理式(Agentic)工作流程切換多個模型時。透過標準API,AI應用可以在任意服務元件和硬體之間切換,以選擇最佳化且最具成本效益的方案。
以下讓我們透過三個不同應用案例來看看它是怎麼運作的。
用OpenVINO Model Server部署LLM
第一個案例是在英特爾NPU上部署Qwen3-8B-int4-cw-ov模型;該模型可從Hugging Face取得,這裡有一系列針對英特爾NPU最佳化的LLM模型。以下將展示如何在Windows系統裸機上進行部署。
要在裸機上部署,先安裝OpenVINO Model Server套件,細節請參考此連結的安裝指南。
接著建立模型目錄,以啟用會直接從Hugging Face下載模型的模型伺服器
mkdir models
ovms --rest_port 8000 ^
--model_repository_path ./models/ ^
--task text_generation ^
--source_model OpenVINO/Qwen3-8B-int4-cw-ov ^
--target_device NPU ^
--reasoning-parser qwen3
等模型伺服器完成模型部署以供服務的流程之後,就可以從另一個終端機視窗查看模型狀態:
curl http://localhost:8000/v1/config
你會看到以下回應:
{
"OpenVINO/Qwen3-8B-int4-cw-ov": {
"model_version_status": [
{
"version": "1",
"state": "AVAILABLE",
"status": {
"error_code": "OK",
"error_message": "OK"
}
}
]
}
}
現在就可以透過提示詞和賦予角色設定來運作模型,讓我們來問它有關OpenVINO的資訊,並讓它成為一個有用的助手。
curl http://localhost:8000/v3/chat/completions -H "Content-Type: application/json" -d "{"model": "OpenVINO/Qwen3-8B-int4-cw-ov", "max_tokens":200,"stream":false, "messages": [{"role": "system", "content": "You are a helpful assistant."},{"role": "user","content": "What is OpenVINO?"}]}"
預期的回應是:
{"choices":[{"finish_reason":"stop","index":0,"message":
{"content":"\nOkay, the user is asking about OpenVINO.
Let me start by recalling what I know about it.
OpenVINO is a framework from Intel, right?
I think it's used for optimizing and deploying deep learning models. But I need to be precise here.
\n\nFirst, I should mention that OpenVINO is developed by Intel, so that's important.
It's a toolkit, which means it's a set of tools and libraries.
The main purpose is to optimize and deploy AI workloads, especially for inference.
I remember that it's used for tasks like computer vision and other AI applications.
\n\nThe key components might include the pre-train models, the model optimizer, and the inference engine.
Let me think. The model optimizer converts models from frameworks like TensorFlow or PyTorch into a specific format, maybe IR (Intermediate Representation).
Then the Inference Engine is used to run these optimized models on hardware that supports it, like CPUs, GPUs, or VPU.
\n\nI","role":"assistant","tool_calls":[]}}],"created":1759165525,"model":"OpenVINO/Qwen3-8B-int4-cw-ov","object":"chat.completion","usage":{"prompt_tokens":25,"completion_tokens":200,"total_tokens":225}}
你也可以使用OpenAI Python套件呼叫模型伺服器;如何在NPU上部署LLM模型服務的完整的指南,請參考此連結。
用OpenVINO Model Server生成圖片
第二個案例是在GPU上部署stable-diffusion-v1–5-int8-ov模型來生成圖片;該模型也可從Hugging Face取得,已轉換和量化為OpenVINO模型格式。OpenVINO Model Server會直接從Hugging Face提取該模型;詳細的模型下載功能說明可參考此文件:提取HuggingFace模型。
在裸機上執行:(安裝OpenVINO Model Server套件的詳細指南請參考此連結)
mkdir models
ovms --rest_port 8000 ^
--model_repository_path ./models/ ^
--task image_generation ^
--source_model OpenVINO/stable-diffusion-v1-5-int8-ov ^
--target_device GPU
在執行圖片生成之前,請先在另一個指令提示視窗中進行準備度檢查,查看模型是否正在載入並準備就緒:
curl http://localhost:8000/v1/config
應該會看到的回應如下:
{
"OpenVINO/stable-diffusion-v1-5-int8-ov" :
{
"model_version_status": [
{
"version": "1",
"state": "AVAILABLE",
"status": {
"error_code": "OK",
"error_message": "OK"
}
}
]
}
}
現在就可以準備向模型伺服器發出請求。
單一可服務模型提供以下端點:
- 文生圖:images/generations
- 圖生圖:images/edits
可使用cURL指令或OpenAI Python套件發出請求,以下展示如何使用OpenAI Python套件。
安裝客戶端程式庫:
pip3 install openai pillow
Python程式碼如下:
from openai import OpenAI
import base64
from io import BytesIO
from PIL import Image
client = OpenAI(
base_url="http://localhost:8000/v3",
api_key="unused"
)
response = client.images.generate(
model="OpenVINO/stable-diffusion-v1-5-int8-ov",
prompt="Three astronauts on the moon, cold color palette, muted colors, detailed, 8k",
extra_body={
"rng_seed": 409,
"size": "512x512",
"num_inference_steps": 50
}
)
base64_image = response.data[0].b64_json
image_data = base64.b64decode(base64_image)
image = Image.open(BytesIO(image_data))
image.save('generate_output.png')
這將產生一個儲存檔名為generate_output.png的圖片,完整示範參考此連結。

生成的圖片
用OpenVINO Model Server部署代理式AI
OpenVINO Model Server可用於為AI代理提供語言模型服務,並支援在內容生成情境下使用各種工具。它可以與MCP伺服器和AI代理框架整合。使用OpenAI Agent SDK的應用程式就是透MCP伺服器運作。
它也配備了一套工具,用以提供生成內容所需的上下文資訊;這些工具也可用於實現以輸入文字格式為基礎的自動化目的。
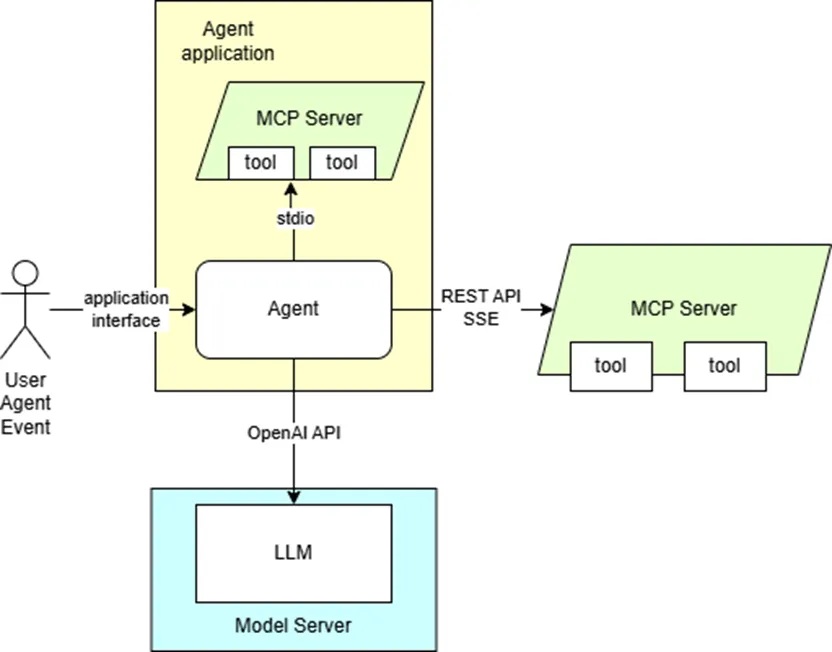
此範例設定的代理式AI流程圖
如果你已經解壓縮了支援Python的模型伺服器套件,請確保在每個將啟動OpenVINO Model Server的新終端機視窗中,依照此部署指南執行setupvars腳本。
從Hugging Face Hub提取模型並儲存到本機:
ovms.exe --pull --model_repository_path models --source_model OpenVINO/Qwen3-8B-int4-ov --task text_generation --tool_parser hermes3
在Windows平台部署於GPU:
ovms.exe --rest_port 8000 --source_model OpenVINO/Qwen3-8B-int4-ov --model_repository_path models --tool_parser hermes3 --target_device GPU --cache_size 2 --task text_generation --max_num_batched_tokens 99999
安裝AI代理所需的運作環境:
curl https://raw.githubusercontent.com/openvinotoolkit/model_server/releases/2025/3/demos/continuous_batching/agentic_ai/openai_agent.py -o openai_agent.py
pip install -r https://raw.githubusercontent.com/openvinotoolkit/model_server/releases/2025/3/demos/continuous_batching/agentic_ai/requirements.txt
Windows平台請下載安裝此運作環境,這是檔案系統MCP伺服器需要的。
執行代理程式:
python openai_agent.py --query "What is the current weather in Tokyo?" --model OpenVINO/Qwen3-8B-int4-ov --base-url http://localhost:8000/v3 --mcp-server weather
應該會看到以下輸出:
Running: What is the current weather in Tokyo?
The weather in Tokyo is overcast with a temperature of 25.4C
完整的案例示範請參考此連結。
結語
在這篇文章中我們探索了OpenVINO Model Server如何透過提供簡單的模型設定和部署,無論你是要打造文字、圖片生成,或是代理式系統等AI應用,都可以輕鬆實現。你可以自由選擇在Docker容器或裸機上部署,享受從邊緣到雲端的部署彈性。
OpenVINO Model Server提供各種能實現AI應用案例的工具,並且能充分利用英特爾硬體的強大功能;想了解更多功能請參考此連結。
(參考原文:Running your GenAI App locally on Intel GPU and NPU with OpenVINO™ Model Server)

- AI Agent時代來臨:看邊緣AI如何成為驅動智慧機器人的關鍵 - 2025/11/28
- OpenVINO×ExecuTorch:解鎖英特爾架構AI PC模型推論效能新境界 - 2025/11/21
- 讓生成式AI應用在Intel架構系統本地端高效率運作的訣竅 - 2025/10/16
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


