作者:歐敏銓
「當機器人能理解環境的物理規律,並用語言、影像與動作相互佐證,那麼,它將不再只是執行指令的工具,而是能夠推理與預測的智慧體。」
這是阿里巴巴達摩院與浙江大學最新提出的 WorldVLA 背後的核心願景。它不只是一個新的模型,更像是一次對人工智慧如何真正「看懂世界、行動於世界」的探索嘗試。在這場技術突破中,研究團隊將視覺-語言-動作(VLA)模型與世界模型(World Model)整合到一個統一架構裡,打造出一個能自回歸(Autoregressive)生成影像與動作的全新框架。這一舉措,正逐步改變我們對機器人智能的想像。
從 VLA 到 WorldVLA:跨越的缺口
在 AI 與機器人研究的進展裡,VLA 模型一直被視為具備巨大潛力的方向。它讓機器能同時處理文字與圖像,再輸出動作。舉例來說,如果一個人下達指令:「把桌上的杯子拿到架子上」,VLA 模型可以依據圖像觀察,規劃出合適的手臂路徑與動作。
然而,這樣的模型有一個限制:動作通常只被當作「輸出」,它們是語言與圖像的最終結果,但卻不會被再拿來作為「輸入」進行更深的理解。這讓機器人缺乏對行為本身的反思與調整能力。
與此同時,世界模型提供了另一種思路。它能在看到當前畫面與動作控制訊號後,預測未來會出現的畫面。這意味著它具備一種「推演未來」的能力,能夠模擬不同動作下環境的可能變化。問題是,世界模型並不能自己產生動作,缺乏決策主動性。
這就像是一邊能動卻不能想,一邊能想卻不能動。研究者們意識到,只有將兩者結合,才能補齊彼此的缺陷。於是,WorldVLA 應運而生。
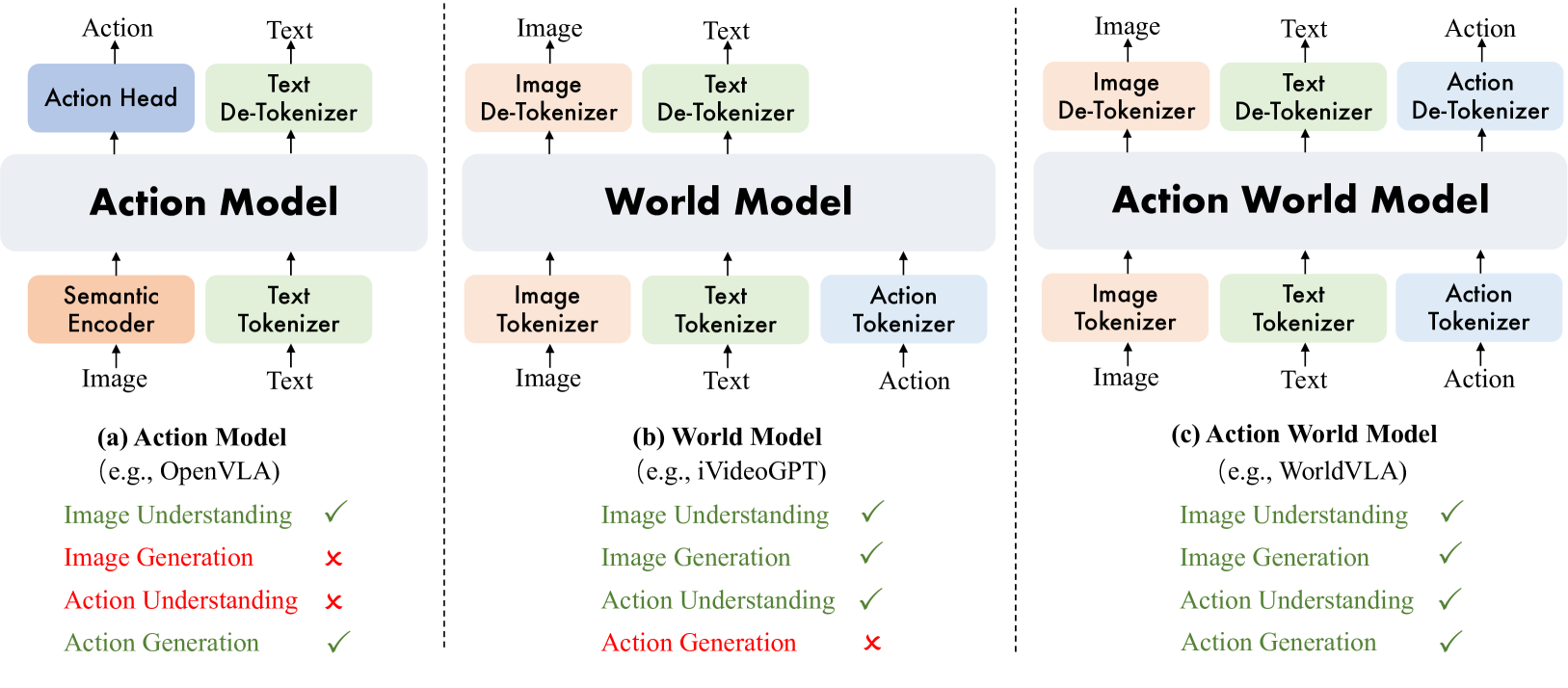
(a)動作模型基於圖像理解生成動作;(b)世界模型基於圖像和動作理解生成圖像;(c)動作世界模型統一了圖像和動作的理解和生成。(source)
WorldVLA 的核心:統一框架與雙向增強
WorldVLA 是一個自回歸動作世界模型,它將動作和圖像的理解與生成統一起來。 WorldVLA 的最大特點是將視覺-語言-動作 (VLA) 模型(動作模型)和世界模型整合在一個框架中。
動作模型結果(Text + Image -> Action):動作模型根據文字指令和圖像觀察產生動作。

輸入:打開櫃子中間的抽屜。(source)
世界模型結果(Action + Image -> Image):世界模型根據當前幀和動作控制產生下一幀。

輸入:「打開頂部抽屜並將碗放入裡面」的動作序列。(source)
WorldVLA使用三個編碼器——圖像編碼器、文字編碼器與動作編碼器,將不同模態的訊息都轉換成一個共享的詞彙表。這樣一來,不論是影像、語言還是動作,對模型而言,都是可被理解並互相生成的「符號」。

WorldVLA技術架構(source)
這種設計帶來了一個重要結果:動作與影像的雙向增強。
- 世界模型學會根據動作去推演未來影像,這讓動作不再只是被動的結果,而是能影響機器如何認知環境。
- 動作模型則能因為世界模型的視覺推演,而更好地理解環境的物理規律,進而產生更合理的行為。
換句話說,動作幫助影像生成更真實,影像則幫助動作規劃更精準。
自回歸挑戰與「注意力遮罩」突破
不過,這樣的自回歸生成模式並非沒有挑戰。研究團隊發現,當模型需要連續生成多個動作時,效能會逐步下降。原因在於:如果前面的動作預測有誤,這個錯誤會一路傳遞,影響後續的判斷。
為了化解這個問題,WorldVLA 引入了一種動作注意力遮罩(attention masking)策略。簡單來說,在生成當前動作時,它會有選擇性地忽略部分先前的動作,以避免錯誤被不斷累積。這種方法像是讓模型「選擇性失憶」,避免它因為早期的錯誤而陷入惡性循環。
實驗證明,這一策略在動作區塊生成任務上帶來了顯著提升,讓機器人在連續操作中的表現更穩定。例如在抓取任務中,WorldVLA 的成功率比傳統自回歸方法提升了 4% 至 23%,這是極為關鍵的差距。
性能實驗:超越單一模型的成果
在研究中,WorldVLA 被放到 LIBERO 基準測試上進行驗證。結果顯示,它在抓取成功率上比同樣骨幹的純動作模型高出 4%,並且在影像生成能力上,也將 Fréchet Video Distance(FVD)降低了 10%。

(source)
換句話說,不論在「如何行動」還是「如何預測未來」的任務裡,WorldVLA 都展現出比獨立模型更佳的表現。這證明了統一的設計並非只是理論上的優雅,而是確實能在實驗數據裡帶來效益。
真實應用場景:從桌面到道路
如果說實驗數據顯示了模型的潛力,那麼應用場景則揭示了它的未來價值。
在機器人任務裡,WorldVLA 能根據語言與視覺指令,完成從「搬動物品」到「組裝零件」等目標導向行動。特別是在雜亂桌面或狹窄空間中,它能夠靈活產生適應性的動作,進行精細操作。
在人機協作的場景下,WorldVLA 不僅能理解人類的語言指令,還能透過動作與影像的互補來捕捉人類的意圖,並做出相應的協作反應。例如,當人類伸手遞交一個工具時,機器人能提前預測到這個動作的意圖,並準備好接過或輔助。
在自動駕駛等領域,WorldVLA 的「未來影像預測」功能尤其重要。它能模擬道路場景中可能發生的情境,讓車輛提早調整行為。這比傳統依靠感測器即時反應的方式更進一步,因為它具備了「推演未來」的能力。
除此之外,研究人員也強調 WorldVLA 的教育與研究價值。作為一個開源框架,它能成為學生與研究者學習「如何將感知、語言與動作整合」的最佳實驗平台。
開放與共享:科研社群的推力
值得一提的是,WorldVLA 並非一個封閉專案。研究團隊已將其開源,並同步放上 GitHub 與 HuggingFace,同時也發表在 arXiv 上。這種選擇透露出一個明確訊號:這不只是阿里達摩院與浙江大學的專利,而是一個希望全球社群共同推進的研究方向。
在機器人與 AI 的快速演進裡,開源與共享已經成為一種默契。正如深度學習早期的 ImageNet、BERT 或 GPT,這些影響深遠的里程碑,都因為社群合作而加速了應用落地。WorldVLA 的出現,也有望在同樣的模式下,成為下一個推動力。
研究背後的哲思:AI 的「世界觀」
WorldVLA 的出現,不僅在實驗數據上展示了動作與世界模型整合的優勢,更在應用層面描繪出廣闊的前景。無論是機器人操作、人機協作,還是自動駕駛與教育研究,它都提供了一個更加全面的解法。
這背後隱藏的訊息是:人工智慧正逐漸學會用自己的方式去「理解」與「行動於」這個世界,而這正是下一代智慧體的核心要素。
在未來,我們或許會看到更多以 WorldVLA 為基礎的延伸應用:更智慧的家庭助理、更靈活的工業機器人、更安全的自駕車輛。每一步進展,都像是在拼湊一塊巨大的拼圖,而 WorldVLA 無疑是其中極為關鍵的一塊。
》延伸閱讀:
WorldVLA – HuggingFace
WorldVLA – arXiv
WorldVLA – 阿里達摩院聯合浙大推出的自回歸動作世界模型

- 【產業觀察】Intel在VLA機器人市場的佈局與契機 - 2026/03/27
- AI如何讓機器人更有「人」味:跨越雙手協同鴻溝! - 2026/03/17
- 2026 Edge AI MCU技術趨勢與廠商方案現況比較 - 2026/03/12
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


