作者:Paul Black,Arm工程部產品管理總監
Arm KleidiAI是一款具有突破性意義的軟體庫,專為提升 Arm CPU 上的人工智慧 (AI) 效能而設計。在一篇先前發表的技術部落格文章中,有針對KleidiAI的簡要概述與相關指南連結,詳述在Linux環境中運作KleidiAI矩陣乘法 (matmul) 微核心的逐步操作,這份指南內容詳實且極易上手。本篇文章內容將探索如何在裸機環境(bare-metal environment)中運作KleidiAI核心,並透過測試多款C/C++ 編譯器,以確定如何能更高效率地生成程式碼。
本文將介紹如何在裸機環境中運作KleidiAI微核心,並針對不同編譯器在不同最佳化等級下的表現進行基礎的基準測試。文中會用到Arm® Development Studio的相關組件,包括固定虛擬平台(FVP),以及Arm Compiler for Embedded (AC6)的授權。同時,還提供如何查看編譯器已採用(或未採用)的最佳化的相關資訊。
設置裸機專案
本文將評估的三個編譯器分別是:
- Arm® Compiler for Embedded,更為人熟知名稱的是 AC6;
- Arm GNU 工具鏈,即 GCC
- 新一代Arm嵌入式編譯器Arm® Toolchain for Embedded (ATfE)。本文撰寫時,該工具鏈仍處於 Beta 測試階段
如何讓在裸機專案中運行 KleidiAI 核心,可參考Kleidi 指南中的說明。本文以Arm Development Studio中的C++示範專案為基礎進行開發:startup_Armv8-Ax1_AC6_CPP是AC6版本,startup_Armv8-Ax1_GCC_CPP是GCC版本,而ATfE 的移植版本則包含在ATfE測試版的下載套件中。這三個編譯器對應的專案功能相同,但需要對Makefile和連結腳本進行必要的修改。請參考這篇部落格文章文章,其中探討了如何將專案從GCC遷移至Arm Toolchain for Embedded所需的更改。
各工具鏈的修正和變更
在貼上Kleidi指南中提供的程式碼後,需對這三個項目進行以下簡單修改以確保正常運作:
- 包含float.h標題檔以定義 FLT_MAX
- 添加KleidiAI標題檔的include路徑
- 將架構更改為armv8.2-a+dotprod+i8mm
- 要執行此程式碼,需要一個具備I8MM擴展的Arm核心。此擴展在2-A至Armv8.5-A架構中為可選功能,而在後續支援進階SIMD指令的核心中則為必選,因此Arm Neoverse-V1是不錯的選擇。Arm Development Studio 提供 Neoverse-V1 固定虛擬平台 (FVP),此處所選用的是-C cluster0.NUM_CORES=1 -C bp.secure_memory=false -C cache_state_modelled=0
- 啟動程式碼中存在一段用於設置 SMPEN 的讀-改-寫序列,但這在 Neoverse-V1 FVP 上會引發問題。由於是重複使用Arm Cortex-A的啟動程式碼來配接Neoverse核心,因此需要進行一些修改,而在本場景中,移除該序列即可解決問題。理想情況下,應根據Neoverse核心的要求重新審閱啟動程式碼,但就本次研究而言,確保程式碼正常運作便已足夠。
- 添加了一些程式碼,用於向矩陣中填充亂數據(random data)。這一步可能並非必需,因為記憶體中原本就已填充了重複的非零模式。
此外,還需要對各個專案單獨做一些修改。示範專案主要是實現處理器的啟動,並未考慮在啟動後運作較為複雜的負載任務:
- 在ATfE專案中,RAM大小被設為0x80000,這個容量過小,會導致堆與棧發生衝突。不過此問題很容易解決,因為即便是 FVP 的預設配置,其提供的 RAM 也遠大於該數值。因此,我們可以在連結腳本中設置更大的 RAM 大小。
- 在 GCC 專案中,.init_array 段被分配到 0x80100000 地址,該地址過低,會與 .eh_frame 段產生衝突。移除此地址設置即可解決問題。
至此就能成功在裸機環境中使用三款不同的工具鏈運作KleidiAI 核心;接下來就可以進行效能測試!
基準測試方法和結果
本次研究中使用了FVP的週期計數器做為效能衡量指標。雖然它並非完美,但對於本次研究而言已經足夠。由於三款編譯器執行的是相同的工作負載,因此即便存在測量誤差,其誤差程度和分佈位置也會保持一致。所以,做為一種效能參考指標,FVP的週期計數完全能滿足本次研究的需求。接著,分別在-O0、-O1、-O2 和 -O3 這四個最佳化級別下,對三款編譯器的週期計數進行測量,以啟動處理器核心、設置矩陣以及執行KleidiAI核心:
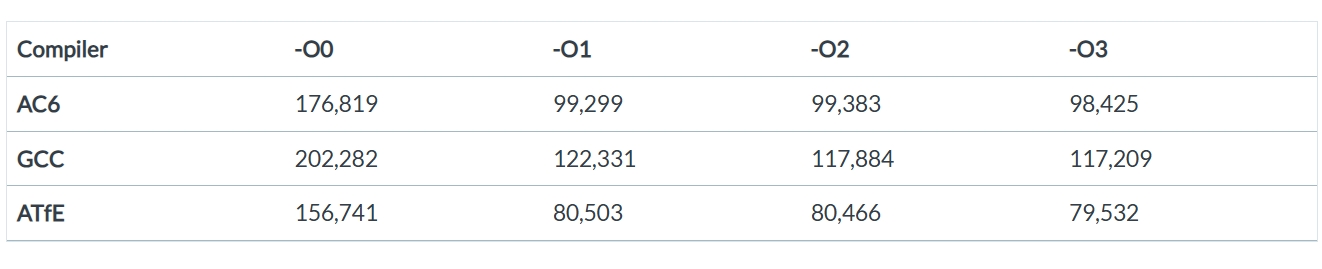
這裡有兩個值得關注的現象。首先,大部分最佳化效果在-O1級別就已顯現。在-O2和-O3級別下雖有小幅提升(其中GCC的提升相對更明顯),但提升幅度遠不及-O1級別。這並不令人意外,因為KleidiAI核心本身已透過大量手工編寫的彙編指令進行最佳化,而在Kleidi核心外添加的程式碼既簡短又簡單。本文後續會深入分析所使用的最佳化手段。
其次,ATfE的表現似乎明顯快於AC6和GCC。新一代Arm嵌入式編譯器能在與AC6的對比中展現出如此優勢,固然令人欣喜,但這一效能差距也促使我進行更深入的探究。
AC6和ATfE的彙編器、編譯器及C++函式庫元件均是基於LLVM建構,兩款工具鏈的主要差異體現在連結器和C函式庫上(AC6採用專有版本,ATfE則使用開源版本)。因此,兩者之間約20%的效能差距讓我頗為好奇。我需要確保所有效能資料和基準測試結果都能適用於實際項目,所以必須進一步釐清ATfE的速度提升究竟源於何處。
深入分析
在這一部分對效能測試進行簡化,但同時也提升了複雜度。透過只探究-O1最佳化等級,以此簡化了測試,因為大部分最佳化效果都呈現在這一級別。同時,透過將程式碼分為三個部分來提高分析的細微性:
- 啟動:所有啟動程式碼,直至進入 main ()
- 準備:為矩陣分配記憶體,向矩陣填充亂數據
- 執行:運行Kleidi核心
週期計數如下:

從KleidiAI核心的執行耗時來看,三款編譯器的表現十分接近,ATfE略領先於AC6 (約1%),而GCC則稍顯落後。在-O2和-O3等級下重新執行該測試,如前文所述,隨著最佳化等級的提高,GCC在-O3級別時小幅超越,這正是高等級最佳化帶來的提升效果之一。
在準備階段,ATfE與AC6的表現依然接近,GCC則仍然落後。同樣在-O2和-O3等級下重新測試後發現,在這些最佳化等級下,GCC縮小了部分差距。這似乎表明,不同編譯器會在不同最佳化等級中納入特定的最佳化過程。
然而,ATfE之所以能實現整體耗時的大幅縮短,關鍵提速點其實在啟動階段。我猜測,這可能是因為ATfE所使用的Picolibc在C函式庫設置環節,比AC6採用的ArmCLib或GCC採用的newlib更輕量化。由於ATfE的主要提速點在於此,而測試項目本身的程式碼量較少,這就導致初始的效能對比結果存在偏差:如果增大工作負載,啟動程式碼在整體執行時間中的佔比就不會如此之高。
分析編譯器最佳化
若要了解ATfE採用(或未採用)哪些最佳化過程,可借助編譯器選項 -Rpass (或-Rpass-missed)。這兩個選項後可接 =.*(表示所有最佳化過程)或 =<optimization>(特定最佳化過程)。例如,使用 -Rpass=inline 可查看哪些函式呼叫已被內聯,而使用 -Rpass-missed=inline 則能了解哪些調用未被內聯。-Rpass-missed 選項對於開發者而言頗具價值,它能揭示C/C++程式碼可如何調整,進而讓編譯器更易於最佳化。
快速查看ATfE 在 -O0、-O1、-O2 和 -O3 下級別下的最佳化過程,其結果如下:
- 即便在-O0 級別,編譯器仍會對部分Arm C語言擴展 (ACLE) 內聯函數進行內聯處理,例如 vaddq_s16(向量加法)。這一點是合理的,因為這類調用僅對應單條指令,因此在效能(受惠於消除函式呼叫開銷)與程式碼體積增加(因程式碼複製導致)之間不存在權衡問題。
- 在-O1等級,編譯器進行了大量的函數內聯,尤其是對小型函數(如亂數產生器實作)。此外,若迴圈中某些指令或計算式無需在每次反覆運算時重新運算,編譯器會將它們提升 (hoist) 到迴圈外部。
- 在-O2等級,編譯器開始進行迴圈向量化,但部分向量化操作會延遲到-O3等級。編譯器採用啟發式演算法來權衡每項最佳化的收益與成本。如同內聯最佳化,在同一最佳化等級下,不同迴圈可能會採用不同的向量化策略,這一點值得關注。
- 在-O3等級,編譯器還會對部分迴圈進行展開。
提升(hoisting)機制值得深入探究。以KleidiAI原始檔案中一段大幅簡化的程式碼為例:
for (size_t dst_row_idx = 0; dst_row_idx < dst_num_rows; ++dst_row_idx) {
for (size_t dst_byte_idx = 0; dst_byte_idx < dst_num_bytes_per_row; ++dst_byte_idx) {
const size_t block_idx = dst_byte_idx / block_length_in_bytes;
const size_t nr_idx = block_idx % nr;
const size_t n0_idx = dst_row_idx * nr + nr_idx;
編譯器注意到,在計算 n0_idx 時,其中的乘法部分無需放在內層迴圈中,因為在內層迴圈中,dst_row_idx 和 nr 均為常數:
src/kai_rhs_pack_nxk_qsi4cxp_qs4cxs1s0.c:96:47: remark: hoisting mul [-Rpass=licm]
96 | const size_t n0_idx = dst_row_idx * nr + nr_idx;
| ^
編譯器會將該乘法操作從內層迴圈提升 (hoist) 到外層迴圈,大致如下:
for (size_t dst_row_idx = 0; dst_row_idx < dst_num_rows; ++dst_row_idx) {
const size_t hoist_temp = dst_row_idx * nr;
for (size_t dst_byte_idx = 0; dst_byte_idx < dst_num_bytes_per_row; ++dst_byte_idx) {
const size_t block_idx = dst_byte_idx / block_length_in_bytes;
const size_t nr_idx = block_idx % nr;
const size_t n0_idx = hoist_temp + nr_idx;
開發者也可手動進行此類最佳化,但這可能會使程式碼變得不夠簡潔、清晰,難以理解和維護。編譯器會考慮這些因素,進而讓開發者能夠專注於程式碼功能、清晰度和可維護性。
ATfE的-Rpass選項輸出包含大量資訊,既涉及已應用的最佳化過程,也涉及未應用的過程。這些資訊對於開發者而言非常有幫助,能讓開發者了解編譯器如何最佳化程式碼,並指導開發者對程式碼進行調整,更能配合編譯器最佳化。這是一個龐大的主題,我將在後續部落格中深入探討。
結論
Studio提供了一套適用於裸機環境下KleidiAI核心實驗的工具,包括便於快速上手的示範專案、用於測試的FVP,以及AC6的授權(之後還將包含ATfEP的授權)。與所有軟體發展工作一樣,在評估編譯器效能等指標時,需要考慮採集所有相關資料。在本案例中,很容易輕易得出「用ATfE建構的項目,比用AC6建構的項目快約20%」的結論。
ATfE 會基於每項潛在最佳化的成本與收益做出啟發式最佳化決策,並提供實用選項來查看已採用和未採用的最佳化。透過這些選項獲取的資訊,可用於調整程式碼,使編譯器能夠實現更多最佳化。
(參考原文:Running KleidiAI MatMul kernels in a bare-metal Arm environment;本文中文版校閱者為 Arm首席應用工程師林宜均)
- 【Arm的AI世界】運算平台開發者必看:無須硬體也能進行OpenBMC+UEFI模擬與驗證! - 2026/04/09
- 【Arm的AI世界】運用ExecuTorch與Arm SME2加速裝置端機器學習推論 - 2026/03/18
- 【Arm的AI世界】重新思考CPU在AI中的角色:在DGX Spark上實作實用的RAG - 2026/02/12
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


