作者:Sandeep Mistry,Arm 物聯網事業部主任軟體工程師兼技術推廣工程師
TinyML是機器學習(ML)的一個分支,專注於將ML模型部署到低功耗、資源受限的物聯網(IoT)裝置上。在物聯網裝置上部署ML模型有許多好處,包括減少延遲和保護隱私性,因為所有資料都是在裝置端處理。TinyML 在 2019 年引起了人們的關注,當時,Google 的TensorFlow團隊發佈了適用於微控制器的TensorFlow Lite (TFLM)模型庫。
最初的應用案例和TFLM應用範例側重於在以Arm Cortex-M4為基礎的開發板(例如 Arduino Nano 33 BLE Sense和SparkFun Edge)上運作經量化的8位元關鍵字檢測和人員檢測模型;這些範例利用 Cortex-M4 CPU的Signed Multiply with Addition(SMLAD)指令對模型所需的乘加運算(MAC)執行裝置端的ML推論。
| 關鍵字檢測 | 人員檢測 | |
| MAC | 336,008 | 7,215,492 |
| RAM (TFLM Tensor arena 大小) | 10 KB | 136 KB |
| 快閃記憶體(用於儲存TFLite模型) | 19 KB | 294 KB |
| 推論延遲(不包括預處理和後處理) | 60 毫秒(ms) | 657 毫秒 |
上表總結了 Arduino Nano 33 BLE Sense上兩種模型的MAC數量、RAM和快閃記憶體要求以及推論延遲。
配備Arm Ethos-U55 NPU的現代微控制器能夠運作一開始就是為行動端應用開發的複雜模型。Ethos-U55 NPU支援44個 TensorFlow Lite運算子(operator)的位元精確輸出,並且可配置為每個週期執行32、64、128或256次MAC運算。本文將透過在配備Ethos-U55 NPU的現代微控制器上執行兩個TinyML應用,來展示NPU的效能優勢。我們將分別在採用和不採用Ethos-U55 NPU的微控制器上運作應用中所使用的 ML模型,以此對推論延遲進行基準測試。
現有物聯網開發板
TinyML應用被部署到Seeed Studio的Grove Vision AI Module V2開發板上,該開發板基於奇景光電(Himax) WiseEye2 HX6538微控制器並整合了16 MB的外部快閃記憶體。Himax WiseEye2 HX6538微控制器搭載了Cortex-M55 CPU和Ethos-U55 NPU,運作頻率均為400 MHz,且配備512 KB緊密耦合記憶體(Tightly Coupled Memory,TCM)和2MB SRAM。

Seeed Studio Grove Vision AI Module V2 開發板
該開發板上有一個15 pin腳相機序列介面(CSI)連接至 Himax WiseEye2 HX6538 MCU,可與基於OmniVision OV5647 的相機模組一起使用。開發板上運作的應用可以從相機模組即時採集解析度為 160×120、320×240 或640×480畫素的RGB影像。將2.8吋的TFT彩色液晶顯示螢幕和 3.7V的鋰聚合物(LiPo)電池連接到開發板上,便能打造出一款可攜式的電池供電裝置。
TinyML 應用
部署到開發板上的兩個以電腦視覺為基礎之應用將會持續:
- 從相機模組擷取影像。
- 完成使用ML模型時所需的預處理和後處理並執行ML推論。
- 在開發板所連接的TFT螢幕上顯示所擷取的影像和ML推論結果。
第一個應用將使用兩個ML模型來檢測人臉的關鍵特徵點,第二個應用則使用ML模型來檢測人體姿態中的關鍵特徵點。
這兩個應用都將運用 TFLM資源庫和Ethos-U自訂運算子,以便將 ML 運算卸載到 NPU 中。應用中所用的量化8 位元TensorFlow Lite模型必須使用Arm的Vela編譯器進行編譯。Vela 編譯器將NPU 支援的運算轉換為Ethos-U 自訂運算子,使其可分配到NPU高效率執行。任何不被NPU支援的運算都將維持原樣並退回到CPU上運作。
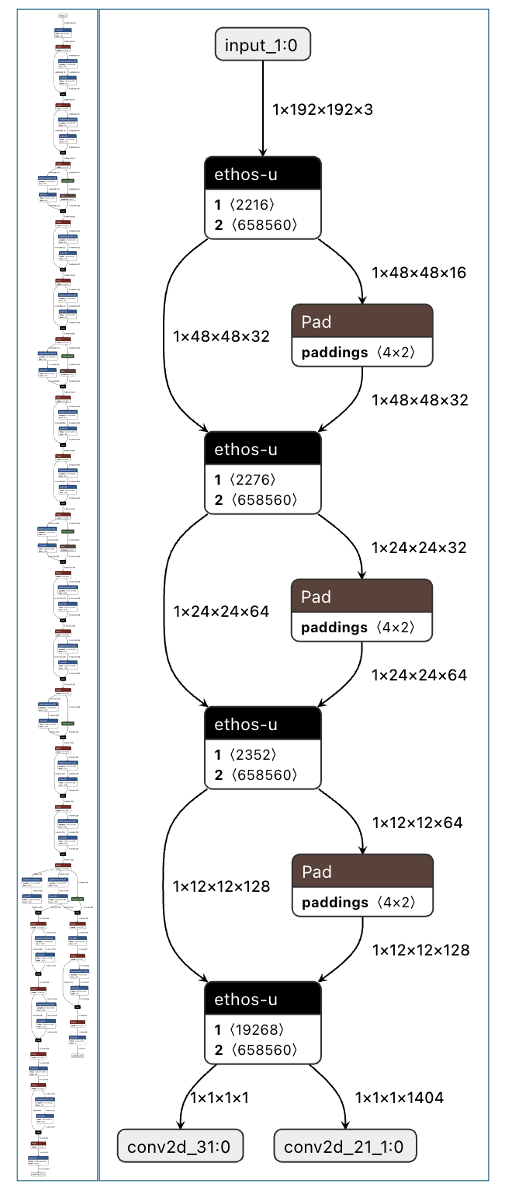
圖左為8位元量化TensorFlow Lite模型圖,圖右是經Vela編譯的8位元量化TensorFlow Lite模型圖
I在以上案例中,除了pad 運算之外的所有 TensorFlow 運算子都被 Vela 編譯器轉換為在Ethos-U55 NPU上運作的Ethos-U自訂運算子。未轉換的pad運算子將回到CPU上運作。
Face Mesh 應用
這個應用從相機模組擷取320×240影像,然後估算人臉上的468個關鍵特徵點。對於那些需要識別熟悉面孔、監測注意力、識別情緒或執行醫療診斷的應用場景來說,此應用可以用作特徵提取層。這裡採用了兩個 ML 模型,首先是使用 Google MediaPipe BlazeFace (short-range)模型來識別影像中臉部的位置,檢測到人臉後,繼而使用 Google MediaPipe Face Mesh模型來識別影像中最大的那個人臉的468個關鍵特徵點。以下視訊展示了模型在開發板上的運作情況:在使用 Ethos-U55 NPU 時,應用的運作速度略低於11幀/秒 (FPS)。
啟用Ethos-U55的情況下,Face Mesh 模型運作的展示
MediaPipe BlazeFace (short-range)模型
MediaPipe BlazeFace (short-range)模型需要將一張RGB 128×128影像作為輸入,且每次推論要執行3,100萬次MAC運算。利用Katsuya Hyodo的PINTO_model_zoo GitHub資源庫,可得到 TensorFlow Lite 格式的BlazeFace (short-range)模型8位元量化版本。
| Cortex-M55
(不使用Helium) |
Cortex-M55 + Ethos-U55 | |
| RAM (TFLM Tensor arena大小) | 461 KB | 391 KB |
| 快閃記憶體(用於儲存TFLite模型) | 203 KB | 169 KB |
| 推論延遲(不包括預處理和後處理) | 3,380 毫秒 | 31 毫秒 |
上表總結了對RAM和快閃記憶體的要求,並將單獨使用Cortex-M55 CPU與同時使用Cortex-M55 CPU和Ethos-U55 NPU所對應的推論延遲進行了比較,結果顯示Ethos-U55 NPU將推論速度提高了109倍!
MediaPipe Face Mesh模型
MediaPipe Face Mesh 模型需要將一張 RGB 192×192 的臉部裁剪圖片(填充率為25%)作為輸入,且每次推論要執行3,680萬次MAC運算。從GitHub下載該模型的16位元浮點版本,並使用 tflite2tensorflow工具將其轉換為8位元量化模型。
| Cortex-M55
(不使用 Helium) |
Cortex-M55 + Ethos-U55 | |
| RAM (TFLM Tensor arena 大小) | 482 KB | 434 KB |
| 快閃記憶體(用於儲存TFLite模型) | 748 KB | 688 KB |
| 推論延遲(不包括預處理和後處理) | 4,436 毫秒 | 43 毫秒 |
上表總結了對RAM和快閃記憶體的要求,並將單獨使用Cortex-M55 CPU與同時使用Cortex-M55 CPU和Ethos-U55 NPU所對應的推論延遲進行了比較,結果顯示Ethos-U55 NPU將推論速度提高了103倍。
Ethos-U55的優勢
將ML運算卸載到Ethos-U55,可使該應用每秒執行10次以上的推論。如果將其部署到Cortex-M55 CPU,在臉部可見的情況下,該應用只能每8秒執行一次推論。
姿態預估應用
該應用從相機模組擷取320×240影像,然後為影像中檢測到的每個人,預估人體姿態的17個關鍵特徵點。該應用可以用做那些需要檢測跌倒或運動的應用的特徵提取層,或作為人機介面的輸入。以下影片展示了模型在開發板上的運行情況;使用Ethos-U55 NPU時,應用的運作速度剛好超過10 FPS。
啟用Ethos-U55的情況下,姿態預估運行的展示。
This model was exported to an 8-bit quantized TensorFlow Lite model with a 256×256 RGB input using DeGirum’s fork of the Ultralytic’s YOLOv8 GitHub repository. DeGirum’s modifications enable the exported model to be better optimized for microcontrollers, this is achieved by removing the transpose operations and separating the model’s seven outputs for improved accuracy with quantization. This model requires 728 million MACs operations per inference.
該模型使用Ultralytic YOLOv8 GitHub資源庫的DeGirum分支,透過一張256×256的RGB影像輸入,匯出為一個8位元量化TensorFlow Lite模型。對DeGirum進行修改可以讓匯出的模型更能針對微控制器進行最佳化,這是透過刪除轉置運算子(transpose operations),並分離模型的7個輸出來達成的,其用意是在提高量化的準確性。該模型每次推論需要進行7.28億次MAC運算。
| Cortex-M55
(不使用 Helium) |
Cortex-M55 + Ethos-U55 | |
| RAM (TFLM Tensor arena大小) | 853 KB | 551 KB |
| 快閃記憶體(用於儲存 TFLite 模型) | 3.23 MB | 2.19 MB |
| 推論延遲(不包括預處理和後處理) | 61,486 毫秒 | 93 毫秒 |
上表總結了對RAM和快閃記憶體的要求,並將單獨使用Cortex-M55 CPU與同時使用Cortex-M55 CPU和Ethos-U55 NPU所對應的推論延遲進行了比較,結果顯示Ethos-U55 NPU將推論速度提高了611倍!將ML運算卸載到Ethos-U55,可使該應用每秒執行10次以上的推論。如果將其部署到Cortex-M55 CPU,該應用只能每62秒執行一次推論;推論延遲的縮短使得應用能更快地對人們的動作做出反應。
結語
本文展示了為行動端應用開發的ML模型,它們每次推論需要進行千萬到數億次MAC運算,可部署到配備Ethos-U55 NPU的現有微控制器上。與TFLM模型庫所含的應用場景相比,這些ML模型對 MAC運算、RAM和快閃記憶體的要求更高。使用NPU可以讓應用在1秒內執行多次推論,而如果沒有 NPU,則每隔幾秒或1分鐘內只能執行一次推論。因此,使用NPU對於應用來說非常有利,使其能夠運作一個或多個相較於初始tinyML應用所使用的模型更複雜的ML模型,而且能夠對周圍環境做出更快的反應。
特別感謝
本文展示的應用歸功於Himax團隊的辛勤付出,他們將Face Mesh和Yolov8n-pose模型移植到了Himax WiseEye2 HX6539微控制器上;是他們的專案成果啟發筆者去開發了一台配備TFT顯示螢幕和可充電電池的輕巧可攜式電池供電裝置。
(參考原文:High efficiency ML-based embedded computer vision;本文中文版校閱者為Arm 主任應用工程師林宜均)
- 【Arm的AI世界】運算平台開發者必看:無須硬體也能進行OpenBMC+UEFI模擬與驗證! - 2026/04/09
- 【Arm的AI世界】運用ExecuTorch與Arm SME2加速裝置端機器學習推論 - 2026/03/18
- 【Arm的AI世界】重新思考CPU在AI中的角色:在DGX Spark上實作實用的RAG - 2026/02/12
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


