隨著像是ChatGPT的聊天機器人崛起,生成式預訓練Transformer模型(Generative Pre-trained Transformer,GPT)也成為開發者社群的當紅炸子雞。生成式AI (GenAI)──特別是大型語言模型(LLM)與聊天機器人──發展迅速且瞬息萬變,很難預測下一個突破會是什麼,以及開發者應該要關注什麼;但我們知道GenAI會持續存在,開發者們也期盼有更簡單明瞭的方式,能在本地開發、維護並部署AI應用。
而儘管GenAI的一切令人感到興奮,要以那些模型執行推論應用仍面臨龐大挑戰,特別是在邊緣裝置與AI PC上的運作。
目前在Intel平台上最先進的GenAI
今日要在Intel硬體平台上取得最佳GenAI性能,開發者可以利用透過Optimum Intel 與OpenVINO後端最佳化的Hugging Face流水線來執行GenAI模型。OpenVINO可實現CPU、GPU與NPU的最佳化,這能有效降低延遲、提升效率。此外,我們可以利用量化、權重壓縮等模型最佳化技巧,來最小化記憶體佔用(能減少2~3倍的記憶體使用量);這通常是在RAM容量只有32GB或更小的客戶端或邊緣裝置部署AI模型的主要瓶頸。

透過新的OpenVINO GenAI API,我們能在程式碼方面能做得更好;如圖中所示,推論程式碼可減少到3行。新的工作流程可提供開發者更低的學習曲線去展開GenAI應用程式開發之旅。
檢視OpenVINO GenAI程式庫的安裝可以看到,不但程式碼行數減少了,而且安裝的依賴項也很少,產生了一個運作Gen AI推論的簡潔環境,佔用的儲存空間僅216Mb!

利用OpenVINO GenAI API來部署解決方案不僅可以減少磁碟使用量,還可以簡化建置生成式AI應用程式的依賴項需求。這通常是開發人員開始維護Gen AI應用程式時的最大挑戰之一。
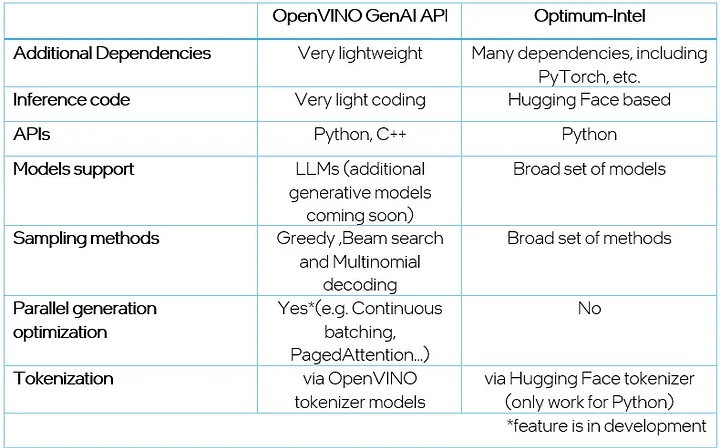
OpenVINO GenAI API與Optimum-Intel封包的比較。
與Optimum-Intel相比,GenAI API只整合了最常用的取樣方法,包括Greedy和Beam搜尋。同時,開發人員還可以透過多項式解碼(Multinomial decoding)自訂取樣參數 (例如top-k或溫度)。
考慮到多用戶場景,GenAI API只原生實現了Contins-batching、Paged-attention;在文字生成過程中,這些技術可以幫助提高性能並最佳化多批次推論時的記憶體消耗。
由於Hugging Face的分詞器(tokenizer)只能與Python配合使用,為了與OpenVINO C++ Runtime的輸入/輸出張量格式保持一致,GenAI API透過分別對2個OpenVINO模型進行推論的方式,對輸入大語言模型的文字進行分詞,以及對大語言模型輸出向量進行去分詞(detokenize)。在此方法之前,開發人員可以使用 Optimum-Intel CLI將Hugging Face的分詞器轉換為OpenVINO IR 模型。
到目前為止,我們已經強調了使用新OpenVINO GenAI API的一些主要優勢。在下一節中,我們將深入探討如何逐步進行展示。
OpenVINO GenAI API的輕量級Gen AI
安裝
設置新的OpenVINO GenAI API,以利用生成式AI和LLM執行推論的過程非常簡單明瞭;安裝過程可以透過PyPI或下載檔案來執行,開發者可以靈活選擇最適合需求的方法。例如可以使用以下程式碼進行PyPI安裝,包含在最新的OpenVINO 2024.2 版本中:
python -m pip install openvino-genai
有關安裝的更多資訊請參考此連結。
執行推論
一旦安裝了OpenVINO,就可以開始使用你的GenAI和LLM模型執行推論。透過利用此API,只需要幾行程式碼就可載入模型、傳遞上下文並接收回應。在內部, OpenVINO處理輸入文字的分詞,在所選裝置上執行、產生循環,並提供最終回應。讓我們根據openvino.genai儲存庫中提供的chat_sample,以Python和C++逐步探索這個過程
步驟1:必須使用Hugging Face Optimum-Intel──在此範例中,我們使用經過聊天應用調整(chat-tuned)的Tiny Llama──下載LLM模型並將其匯出為OpenVINO IR 格式。針對此步驟,建議建立一個單獨的虛擬環境以避免任何依賴項衝突。例如:
python -m venv openvino_venv
啟動它:
openvino_venv\Script\activate
並安裝模型匯出過程所需的依賴項。這些要求可在openvino.genai儲存庫中找到。
python -m pip install --upgrade-strategy eager -r requirements.txt
若要下載並匯出模型,請使用以下指令:
optimum-cli export openvino --trust-remote-code --model TinyLlama/TinyLlama-1.1B-Chat-v1.0 TinyLlama-1.1B-Chat-v1.0
為了提高LLM推論期間的性能,建議對模型權重使用較低的精確度,例如INT4。你可以在模型匯出過程中使用神經網路壓縮框架(Neural Network Compression Framework,NNCF)來壓縮權重,如下所示:
optimum-cli export openvino --trust-remote-code --model TinyLlama/TinyLlama-1.1B-Chat-v1.0 TinyLlama-1.1B-Chat-v1.0 --weight-format int4
因為模型只需匯出一次,在此步驟中安裝的虛擬環境和依賴項不會再用到,可以隨意從磁碟中刪除。
步驟 2:透過Python或C++ API執行LLM文字生成推論。
透過新的Python API設置流水線:
pipe = ov_genai.LLMPipeline(model_path, "CPU")
print(pipe.generate("The Sun is yellow because"))
透過新的C++ API設置流水線:
int main(int argc, char* argv[]) {
std::string model_path = argv[1];
ov::genai::LLMPipeline pipe(model_path, "CPU");//target device is CPU
std::cout << pipe.generate("The Sun is yellow because"); //input context
正如以上所示,建立LLM生成流水線現在僅需少數幾行程式碼;這樣的簡化是因為從Hugging Face Optimum-Intel導出的模型已經包含執行的所有必要資訊,包括分詞/去分詞器和生成配置,確保結果與Hugging Face的生成一致。我們提供C++和Python API來執行LLM,將應用所需的依賴項和添加項最小化。
所提供的程式碼在CPU上運作,也可簡單將裝置名稱替換為「GPU」,輕鬆在GPU上運作:
pipe = ov_genai.LLMPipeline(model_path, "GPU")
為了建立更多互動式UI進行生成,我們添加了針對串流模型輸出詞元(streaming model output tokens)的支援,以便模型生成後可以立即提供輸出單字。也可以透過從串流器(streamer)返回True指令,隨時停止詞元生成。
此外,有狀態模型在內部運作以進行文字生成推論,從而提高生成速度,並減少由於資料表示轉換而產生的開銷。因此,跨輸入維護KVCache可能是有益的。聊天應用特定的方法start_chat和finish_chat被用於標記對話期間(conversation session),如以下範例所示。
以Python語言:
import argparse
import openvino_genai
def streamer(subword):
print(subword, end='', flush=True)
# Return flag corresponds to whether generation should be stopped.
# False means continue generation.
return False
model_path = TinyLlama-1.1B-Chat-v1.0
device = 'CPU' # GPU can be used as well
pipe = openvino_genai.LLMPipeline(args.model_dir, device)
config = openvino_genai.GenerationConfig()
config.max_new_tokens = 100
pipe.start_chat()
while True:
prompt = input('question:\n')
if 'Stop!' == prompt:
break
pipe.generate(prompt, config, streamer)
print('\n----------')
pipe.finish_chat()
以C++語言:
#include "openvino/genai/llm_pipeline.hpp"
int main(int argc, char* argv[]) try {
if (2 != argc) {
throw std::runtime_error(std::string{"Usage: "} + argv[0]
+ " ");
}
std::string prompt;
std::string model_path = argv[1];
std::string device = "CPU"; // GPU can be used as well
ov::genai::LLMPipeline pipe(model_path, "CPU");
ov::genai::GenerationConfig config;
config.max_new_tokens = 100;
std::function<bool(std::string)> streamer = [](std::string word) {
std::cout << word << std::flush;
// Return flag corresponds to whether generation should be stopped.
// false means continue generation.
return false;
};
pipe.start_chat();
for (;;) {
std::cout << "question:\n";
std::getline(std::cin, prompt);
if (prompt == "Stop!")
break;
pipe.generate(prompt, config, streamer);
std::cout << "\n----------\n";
}
pipe.finish_chat();
} catch (const std::exception& error) {
std::cerr << error.what() << '\n';
return EXIT_FAILURE;
} catch (...) {
std::cerr << "Non-exception object thrown\n";
return EXIT_FAILURE;
}
最後,這是我們在AI PC執行以上範例取得的結果:
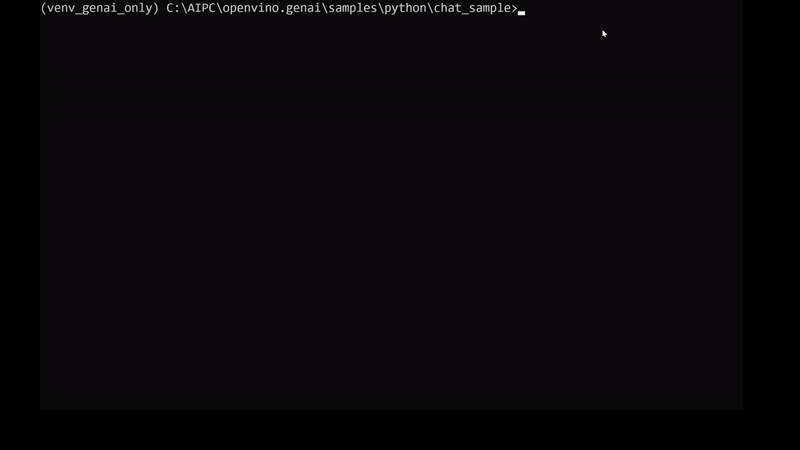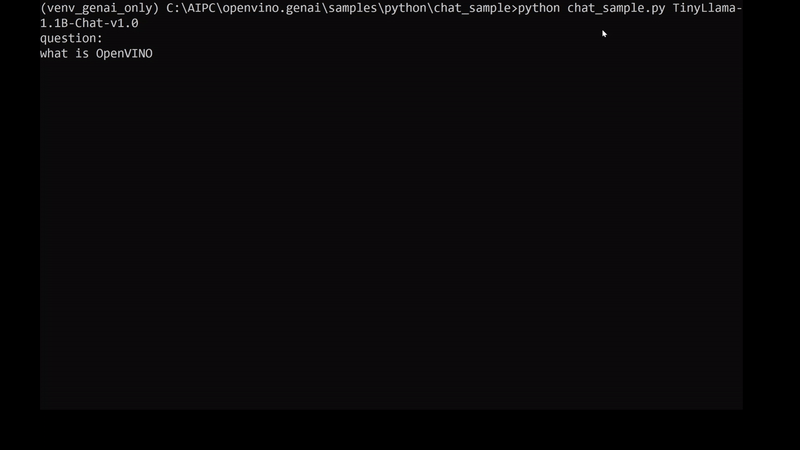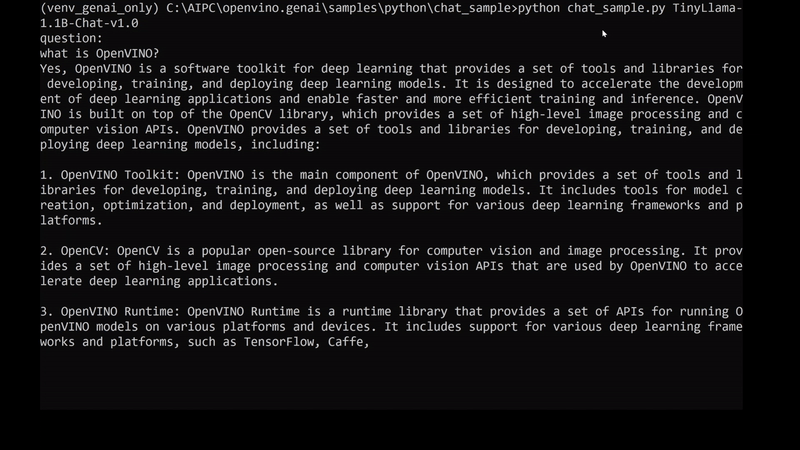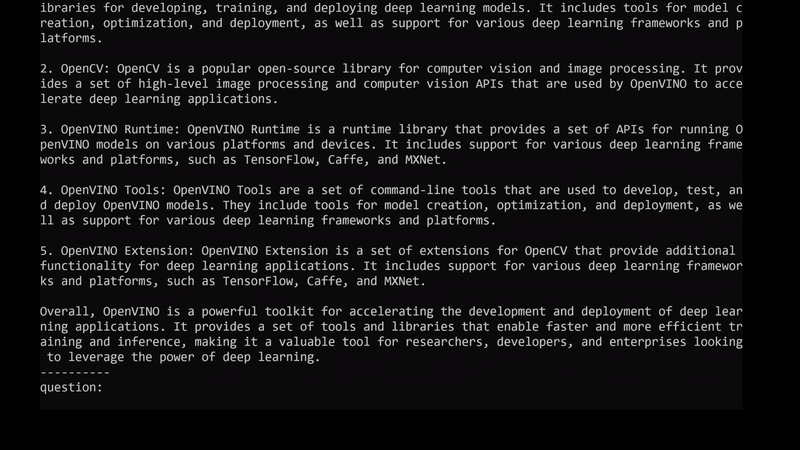
在AI PC本地執行以Llama為基礎的聊天機器人實際展示。
總而言之,GenAI API包含以下支援輕量級部署和編碼的API:
- generation_config ──用於實現產生過程客製化的配置,例如生成文字的最大長度、是否忽略句尾詞元以及解碼策略的細節(Greedy、Beam搜尋或多項式取樣)。
- llm_pipeline ──提供用於文字生成的類別和實體(utilities),包括用於處理輸入、生成文字以及使用可配置選項管理輸出的流水線。
- streamer_base ──用於建立串流器(streamer)的抽象基底類別。
- tokenizer ──用於文字編解碼的 分詞器類別。
- visibility ──控制 GenAI程式庫的可見性。
結語
OpenVINO 2024.2版本中的全新OpenVINO GenAI API提供了顯著的優勢和功能,使其成為開發人員創建GenAI和LLM應用程式的強大工具。憑藉簡易的設置流程和最少的依賴項,該API降低了程式碼複雜性,只需幾行程式碼就可以快速建立高效率的Gen AI推論流水線。此外,對串流模型輸出詞元的支援,有助於建立互動式UI,因此提升使用者體驗。
歡迎嘗試新的GenAI API並在你的開發專案中探索其功能,讓我們透過開放源碼程式庫一起挑戰生成式AI可實現的極限吧!
(參考原文:How to Build Faster GenAI Apps with Fewer Lines of Code using OpenVINO™ GenAI API)

- AI Agent時代來臨:看邊緣AI如何成為驅動智慧機器人的關鍵 - 2025/11/28
- OpenVINO×ExecuTorch:解鎖英特爾架構AI PC模型推論效能新境界 - 2025/11/21
- 讓生成式AI應用在Intel架構系統本地端高效率運作的訣竅 - 2025/10/16
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


