作者:Anisha Udayakumar,英特爾AI軟體佈道師
你是否曾經想過如何能讓AI像人類那樣理解場景?多模態(multimodal) AI是一大關鍵——它可以同時處理視覺、聽覺和文字資料,以驚人的深度和精確度解釋其環境;在這篇與下一篇系列文章中,我們將深入探討多模態AI的能力,並探索英特爾(Intel)的OpenVINO工具套件如何最佳化這些複雜系統,以因應現實世界的應用。
本系列的第一篇文章將重點介紹Pix2Struct及其利用Optimum Intel實現的最佳化;要了解更多關於LLaVA-NeXT 的內容,請期待下一篇文章。
什麼是單模態 AI?
在我們深入探討AI的能力之前,了解系統在處理資料時採取的不同方法是很重要的。傳統上,許多AI系統仰賴單模態處理,專注於單一類型的資料輸入。儘管這種方法有其優點,也呈現明顯的限制,特別是在模仿人類互動的複雜環境中。這篇文章我們將探討為何朝向多模態AI的演變代表了該領域的一大進步。
為何轉向多模態AI?
多模態AI改革了人工智慧理解這個世界以及與世界互動的方式,模仿人類的感官和認知功能;這些系統整合多種類型的資料——視覺、音訊和文字——以達到超越傳統AI系統的複雜性和理解能力。透過處理這些多樣化的資料流,多模態AI可以充分理解上下文情境,做出明智的決策並自然地互動。多模態AI的優勢在於其整合多種感官資料的能力,就像人類與世界互動一樣。這種全面的資料處理方法使這些系統能夠更充分地理解上下文情境,做出更明智的決策並更自然地互動。
多模態AI的優勢:
- 更豐富的資料處理:多模態AI結合來自各種資料類型的見解,能提供對複雜情況更完整的理解。
- 改善的準確性:透過跨多個來源驗證資料,這些系統能達到更高的準確性和可靠性。
- 更強的韌性:不同於單模態系統,即使一種輸入類型受損,多模態AI仍能維持功能。
Pix2Struct的專門化和實際應用
Pix2Struct是一種理解視覺情境語言(visually situated language)的多模態模型,能輕鬆因應從影像中提取資訊的任務,特別是在文件視覺問答(Document Visual Question Answering,DocVQA)任務中表現出色。該模型可以處理具有複雜佈局和結構的文件,例如表格和圖表,這對傳統的OCR系統來說是一項挑戰。Pix2Struct不僅能識別和提取文字,還能理解文字出現的上下文情境,從而回答有關文件內容的問題,而不僅僅是提供數位版本。這使得Pix2Struct成為將以檔案為基礎的工作流程、資訊檢索、檔案分析與摘要等任務自動化的理想選擇。
從理論到實踐:OpenVINO Notebooks
了解多模態AI的優勢能提供紮實的理論基礎,若能看到這些系統的實際運作,則能充分發揮其潛力。為了縮小概念理解與實際應用之間的差距,開發者可以探索OpenVINO Notebooks。這些資源提供逐步指導,展示如何透過OpenVINO進行最佳化和部署,以充分利用多模態AI以及其他熱門AI模型的能力。
針對DocVQA任務的Pix2Struct Notebook:
這個Notebook包括從模型下載、轉換為IR格式和執行的步驟,展示了使用Optimum Intel最佳化AI模型的簡單性和強大功能。
跟著OpenVINO Notebook的步驟進行實作
1. 安裝必備項目:
首先設置開發環境以使用OpenVINO工具套件。這包括安裝OpenVINO工具套件以及支援 Pix2Struct模型的必備程式庫和依賴項目。這部份的設置是確保所有模型最佳化和部署的工具都已到位,可為各種AI應用提供統一的平台。
2. 模型下載和載入:
此步驟涉及從Hugging Face Transformers程式庫中檢索Pix2Struct模型並準備進行最佳化。我們將使用Hugging Face的 pix2struct-docvqa-base模型。Optimum Intel可以載入這些最佳化的模型,並建立流水線以使用OpenVINO Runtime和Hugging Face API進行推論。
3. 將模型轉換為OpenVINO的IR格式:
接下來將Pix2Struct模型轉換為OpenVINO IR (Intermediate Representation)格式。Optimum Intel簡化了此流程,大幅提升了模型在各種硬體上的性能。Optimum Intel可以直接從Hugging Face載入最佳化的模型,這種方法透過無縫管理模型載入和最佳化,為開發者提供了便利。
首先,模型類別初始化從呼叫 from_pretrained 方法開始。下載轉換Transformers模型時,需新增參數export=True。為了減少記憶體消耗,我們可以使用 half() 方法將模型壓縮為 float16。
1. from optimum.intel.openvino import OVModelForPix2Struct
2. # Specify the model ID from Hugging Face
3. model_id = "google/pix2struct-docvqa-base"
4. # Load the model in OpenVINO IR format
5. ov_model = OVModelForPix2Struct.from_pretrained('pix2struct-model-id', export=True, compile=False)
此行程式碼會直接從Hugging Face載入Pix2Struct模型。
4. 裝置選擇和配置:
為了獲得最佳性能,選擇適當的硬體裝置進行推論至關重要。這包括配置 OpenVINO Runtime以利用特定裝置,如 CPU、GPU 或 NPU,根據可用性和應用需求進行選擇。
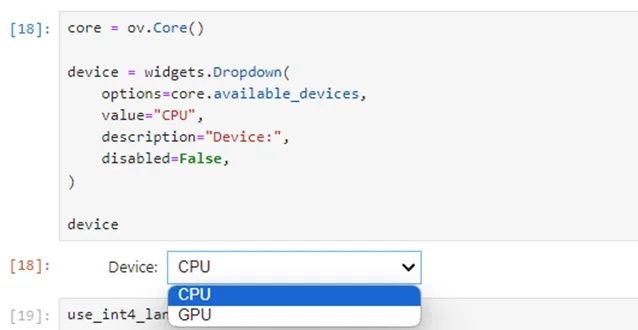
5. 推論流水線設置:
設置推論流水線對於配置推論設定和準備模型以有效進行預測至關重要,這包括為Pix2Struct 預處理資料。
針對Pix2Struct,以下步驟概述了設置過程:
- 資料準備:利用Pix2StructProcessor進行輸入資料的預處理。
- 模型推論:使用OVModelForPix2Struct.generate方法會啟動答案生成。
- 答案解碼:使用Pix2StructProcessor.decode將生成的答案詞元索引解碼為文字格式。
6. from transformers import Pix2StructProcessor
7. processor = Pix2StructProcessor.from_pretrained(model_id)
8. ov_model = OVModelForPix2Struct.from_pretrained(model_dir, device=device.value)
6. 執行和結果展示:
讓我們看看 Pix2Struct 模型的實際運作。為了實現互動性體驗,我們使用Gradio,一個允許為我們的模型創建自定義介面的Python程式庫。這個設置讓使用者可以直接與Pix2Struct模型互動:
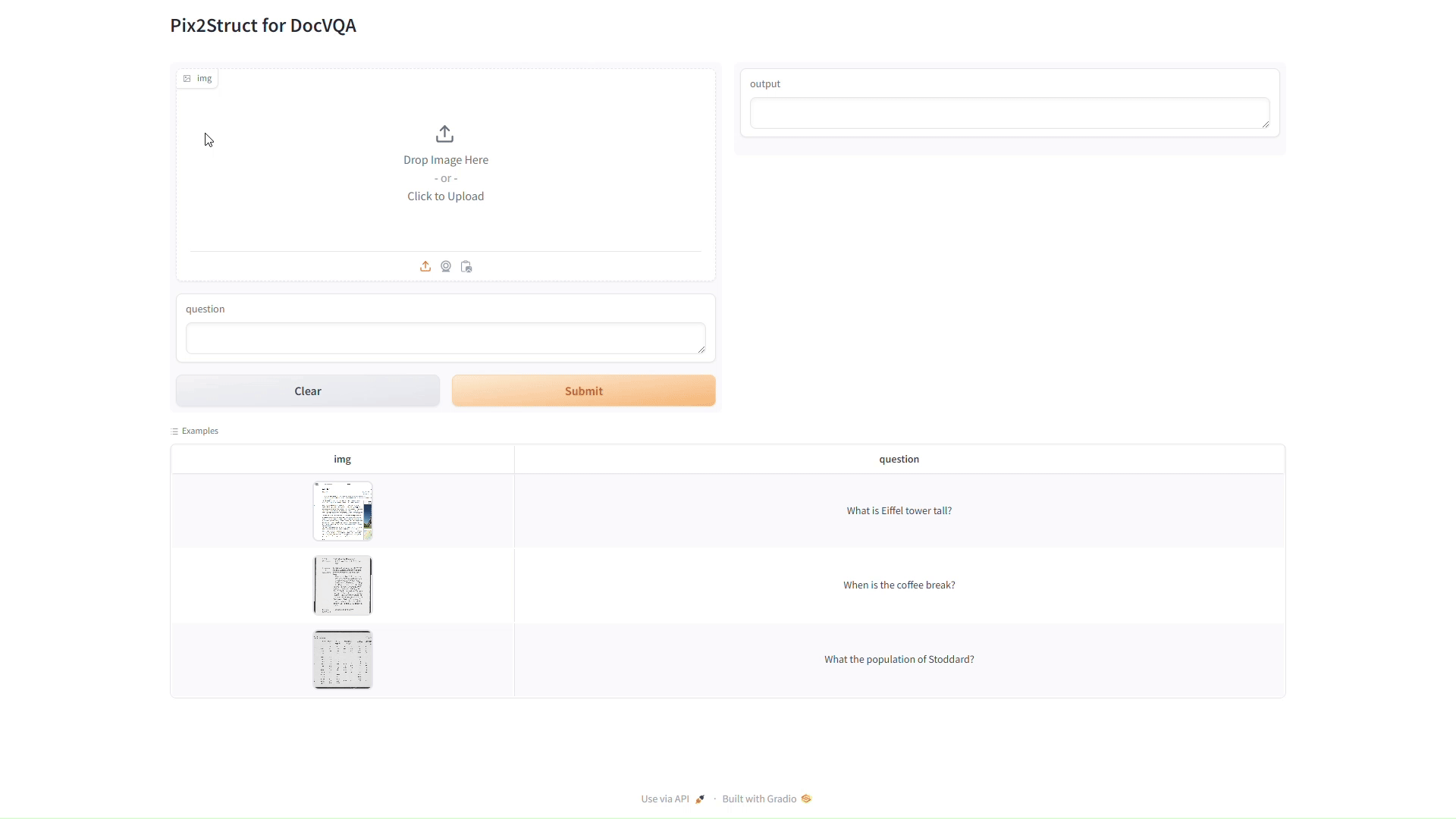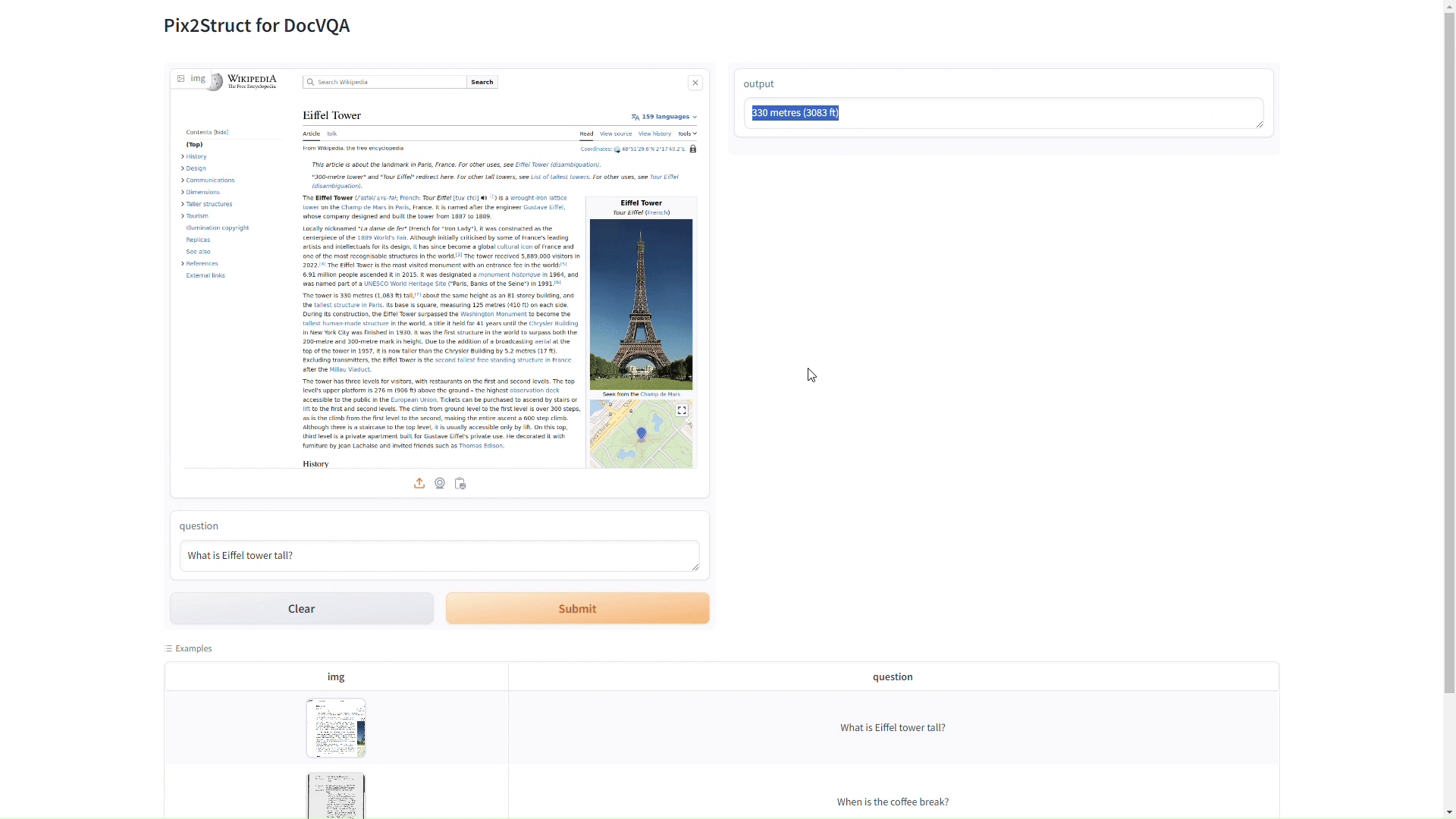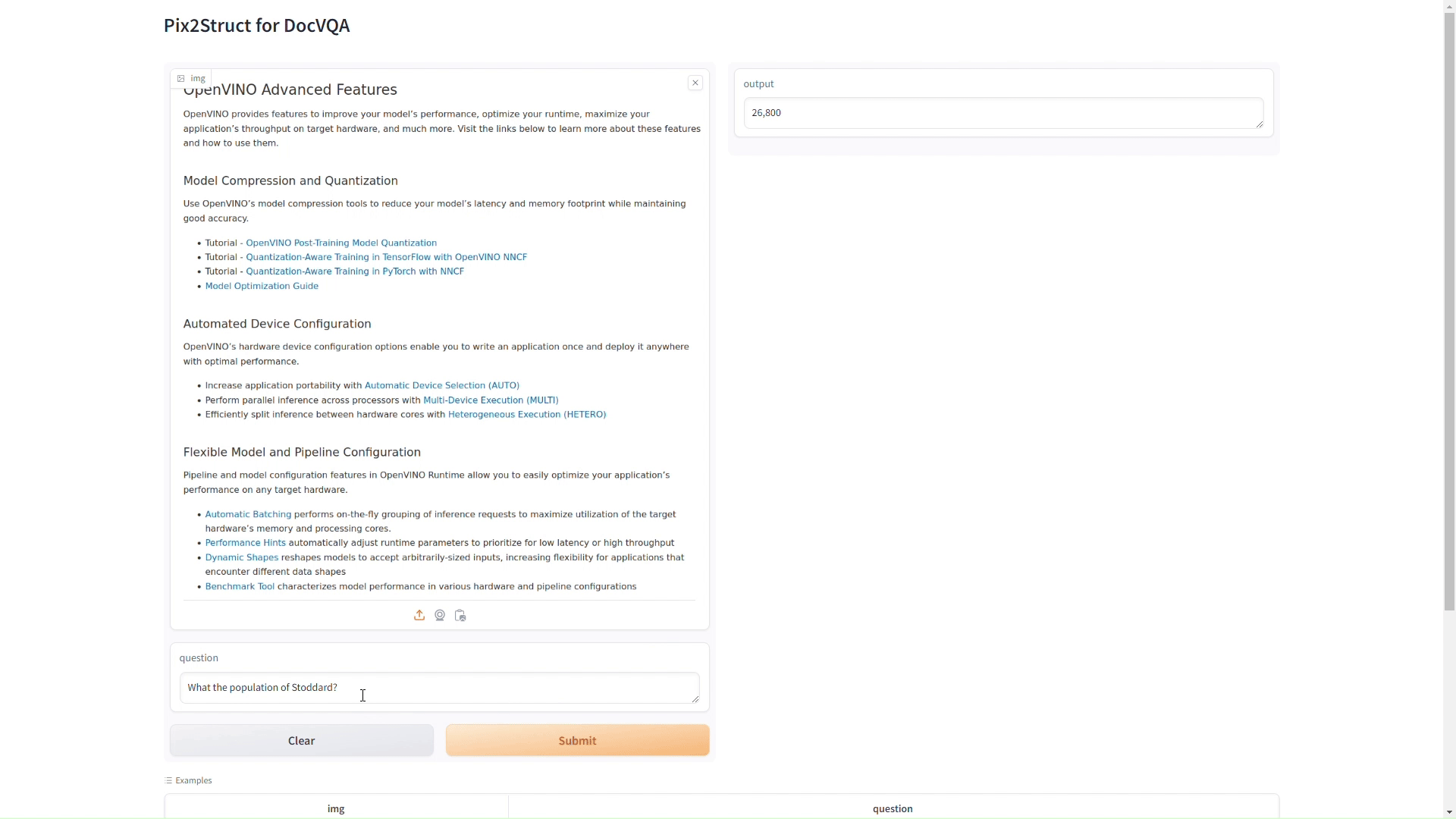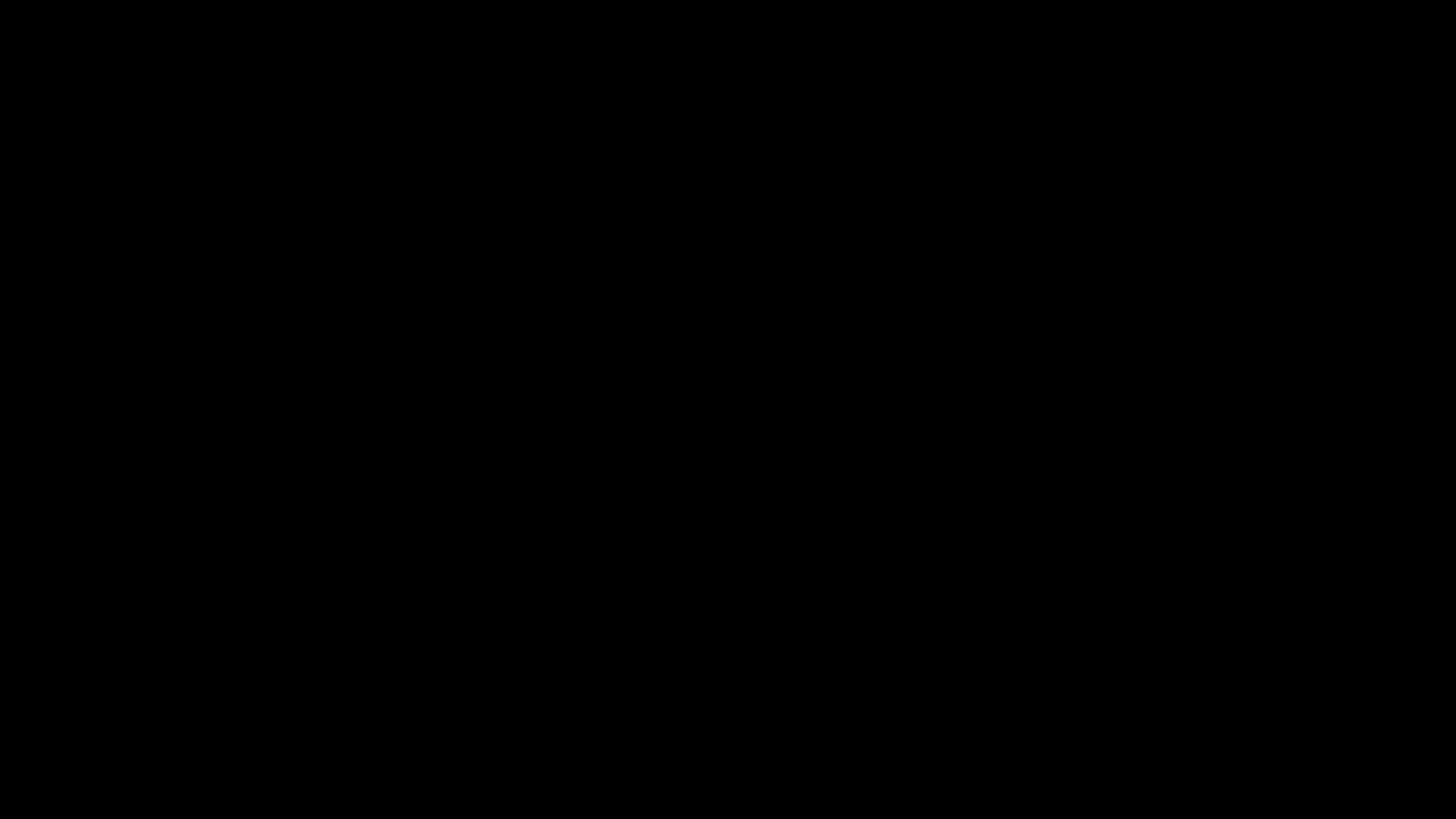
Gradio應用程式提供了一個直觀介面,讓使用者上傳影像檔案,查看模型即時執行DocVQA 任務。這裡展示了模型解釋複雜檔案版面佈局和提取可行動見解的能力。
小結
在這篇文章對多模態AI和Pix2Struct模型的探索中,我們看到整合多種感官資料流能如何提升AI效率和回應能力。Pix2Struct在理解和解釋複雜檔案版面佈局方面表現出色,能提供準確、感知上下文情境的答案。
利用Intel的OpenVINO工具套件和 Optimum Intel 簡化模型最佳化和部署,確保了在各種硬體平台上的高性能。Pix2Struct的實際應用,如自動化以檔案為基礎的工作流程和資訊檢索,展示了多模態AI的革命性潛力。
那麼,像是LLaVA-NeXT這樣更複雜、不屬於Optimum Intel生態系的模型呢?下一篇文章我們將深入探討LLaVA-NeXT的獨特功能,並探討針對這些先進模型的最佳化方法。
(參考原文:Unleashing the Power of Multimodal AI with Pix2Struct and Optimum Intel;編譯:Judith Cheng)

- AI Agent時代來臨:看邊緣AI如何成為驅動智慧機器人的關鍵 - 2025/11/28
- OpenVINO×ExecuTorch:解鎖英特爾架構AI PC模型推論效能新境界 - 2025/11/21
- 讓生成式AI應用在Intel架構系統本地端高效率運作的訣竅 - 2025/10/16
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


