作者:Anisha Udayakumar,英特爾AI軟體佈道師
繼上一篇文章對多模態AI能力的討論之後,本系列文章的第二篇將深入探討LLaVA-NeXT的複雜工作原理和對這類模型進行最佳化的先進量化技術 (利用NNCF)。
(本系列上一篇文章請參考:釋放多模態AI的力量:利用Pix2Struct和Optimum Intel)
了解LLaVA-NeXT
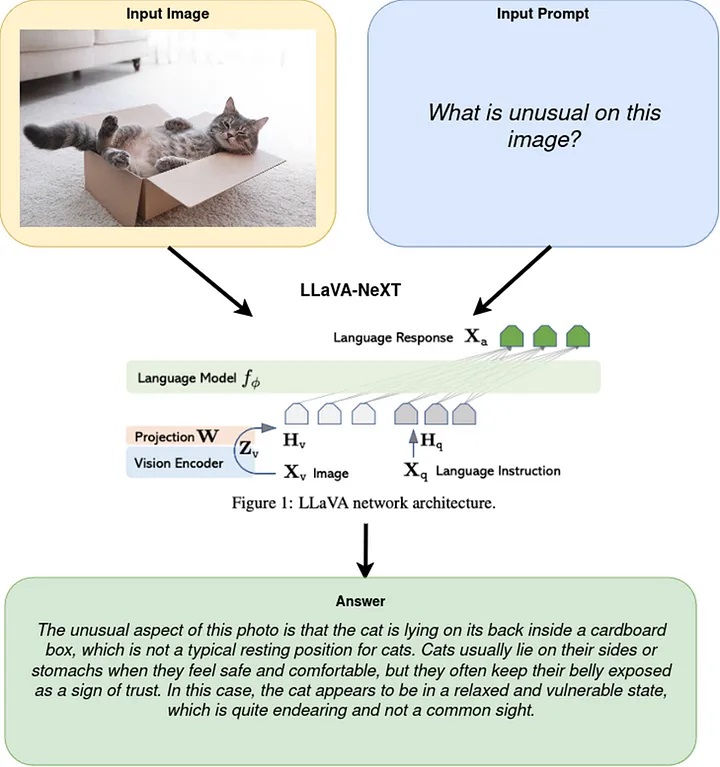
LLaVA-NeXT (Large Language and Vision Assistant-Next Generation)是一種複雜的多模態模型,被設計為進行影像上的高階語言推論。不同於專注Document Visual Question Answering (DocVQA)任務的Pix2Struct,LLaVA-NeXT結合了大型語言模型(LLM)和像是CLIP的視覺編碼器,打造了一個通用的視覺助手;這個模型能夠遵循語言和影像指令完成各種現實世界的任務,非常適合創造複雜的多模態聊天機器人。
LLaVA-NeXT導入了經改善的OCR能力和擴展的世界知識,這標誌著在影像上的高階語言推論取得了重大突破,其複雜結構需要使用OpenVINO和NNCF進行詳細的量化步驟來進行最佳化。在這篇文章中,我們將探索LLaVA-NeXT多模態聊天機器人Notebook,學習如何轉換和最佳化LLaVA-NeXT模型來打造多模態聊天機器人。此外,我們將探討如何在LLM部分應用有狀態轉換(stateful transformation)和使用NNCF進行權重壓縮和量化等模型最佳化技術。
跟著OpenVINO Notebook的步驟進行實作
1. 安裝必備項目:
開始設置開發環境以使用OpenVINO工具套件。包括安裝OpenVINO工具套件,以及支援LLaVA-NeXT模型所需的程式庫和依賴項。
2. 模型下載和加載:
設計用於複雜語言和視覺任務的LLaVA-NeXT需要詳細和客製化的方法,包括幾個需要在最佳化過程中個別關注的元件:
- Image Encoder:管理視覺輸入,通常是以像CLIP這樣的複雜視覺模型為基礎。
- Input Embeddings:負責有效地將輸入文字轉為嵌入。
- Language Model:以基於視覺和文字資料的綜合理解來生成回應。
針對複雜的語言和視覺任務,LLaVA-NeXT 整合了需要精確模型處理的複雜功能。以下是載入該模型的方法:
1. from transformers import LlavaNextProcessor, LlavaNextForConditionalGeneration
2. processor = LlavaNextProcessor.from_pretrained("llava-hf/llava-v1.6-mistral-7b-hf")
3. model = LlavaNextForConditionalGeneration.from_pretrained("llava-hf/llava-v1.6-mistral-7b-hf")
此程式碼片段正確載入LLaVA-NeXT模型,確保其所有元件(從語言處理到影像理解)均已載入,並準備好進行進一步的轉換和最佳化過程。
3. 將模型轉換為OpenVINO IR格式:
由於其複雜結構,LLaVA-NeXT模型需要採用一種微妙的方法,涉及對其三個主要元件——Image Encoder、Input Embeddings和Language Model──的個別最佳化。OpenVINO透過使用OpenVINO模型轉換API將PyTorch模型轉換為OpenVINO IR格式,來支援這種PyTorch模型的轉換。ov.convert_model函數接受原始PyTorch模型實例和用於模型追蹤(tracing)的範例輸入,並傳回可儲存用於部署的ov.Model。
- Image Encoder:Image Encoder通常是LLaVA-NeXT中的預訓練視覺模型,如CLIP,被轉換為OpenVINO的IR格式。此步驟確保模型可以在OpenVINO支援的平台上有效處理視覺輸入:
4. ov_image_encoder = ov.convert_model(image_encoder_model, example_input=torch.zeros((1, 5, 3, 336, 336)))
5. ov.save_model(ov_image_encoder, IMAGE_ENCODER_PATH)
- Text Embedding:將文字輸入轉換為適合處理的格式,並單獨最佳化以處理文字資料:
6. ov_input_embeddings_model = ov.convert_model(input_embedding_model, example_input=torch.ones((2, 2), dtype=torch.int64))
7. ov.save_model(ov_input_embeddings_model, INPUT_EMBEDDING_PATH)
- Language Model:Language Model至關重要,因為它合成了Image Encoder和Input Embeddings的處理輸入,以產生連貫且上下文相關的文字回應。
為了最佳化性能,OpenVINO利用了兩項進階功能:
- 快取機制(Caching Mechanism):使用Transformers程式庫中的use_cache=True參數和past_key_values來快取和重複使用隱藏狀態,減少運算負載。
- 有狀態模型轉換(Stateful Model Transformation):將模型轉換為有狀態模型,在內部管理快取張量以減少推論期間的輸入/輸出開銷。
8. def make_stateful(
9. ov_model: ov.Model,
10. not_kv_inputs: List[str],
11. key_value_input_names: List[str],
12. key_value_output_names: List[str],
13. batch_dim: int,
14. num_attention_heads: int,
15. num_beams_and_batch: int = None,
16. ):
17. from openvino._offline_transformations import apply_make_stateful_transformation
4. 利用OpenVINO進行量化:
- 以NNCF進行權重壓縮:為了減少記憶體佔用並提高語言模型的推論性能,使用神經網路壓縮框架(NNCF)進行權重壓縮。此方法對於LLM等受限大型記憶體(arge memory-bound)的模型非常有效。
- 語言模型的INT4壓縮:應用NNCF的4位元權重壓縮來減少記憶體消耗並提高執行速度。雖然這可能會因精度較低而稍微降低預測品質,但這對於大型模型的高效部署至關重要。
18. import nncf
19. compression_configuration = {
20. "mode": nncf.CompressWeightsMode.INT4_SYM,
21. "group_size": 64,
22. "ratio": 0.6,
23. }
24. # Check if weight compression is enabled
25. if to_compress_weights.value and not LANGUAGE_MODEL_PATH_INT4.exists():
26. ov_model = core.read_model(LANGUAGE_MODEL_PATH)
27. ov_compressed_model = nncf.compress_weights(ov_model, **compression_configuration)
28. core.save_model(ov_compressed_model, LANGUAGE_MODEL_PATH_INT4)
- Image Encoder的 INT8 量化:使用 NNCF 的訓練後量化來最佳化影像編碼器,透過將運算精度降低至8位元來加快推論速度。
29. # Load the pre-quantization model
30. ov_model = core.read_model(IMAGE_ENCODER_PATH)
31.
32. # Prepare the calibration data necessary for quantization
33. calibration_dataset = nncf.Dataset(calibration_data)
34. # Execute the quantization process
35. quantized_model = nncf.quantize(
36. model=ov_model,
37. calibration_dataset=calibration_dataset,
38. model_type=nncf.ModelType.TRANSFORMER,
39. subset_size=len(calibration_data),
40. advanced_parameters=nncf.AdvancedQuantizationParameters(smooth_quant_alpha=0.6))
41. # Save the quantized model for deployment
42. ov.save_model(quantized_model, IMAGE_ENCODER_PATH_INT8)
雖然 INT4 壓縮透過進一步降低精度來提供更大的效能改善,但它對模型精度的影響比INT8 更顯著。然而,NNCF 權重壓縮──特別是 INT4 ──的顯著優勢是它是免資料(data-free)的,不需要校準資料集,這簡化了壓縮過程。
5. 裝置選擇和配置:
為了獲得最佳性能,選擇適當的硬體裝置進行推論至關重要。這包括配置 OpenVINO Runtime以利用特定裝置,如 CPU、GPU 或 NPU,根據可用性和應用需求進行選擇。
6.推論流水線設置:
設置推論流水線對於配置推理設定和準備模型以有效執行預測至關重要;此程序利用 OVLavaForCausalLM 類別來產生與上下文相關的回應。
7. 執行和結果展示:
讓我們來看看LLaVA-NeXT的實際運作,同樣利用能允許使用者輸入文字和影像以與多模式聊天機器人互動的Gradio應用程式;Gradio介面有助於測試LLaVA-NeXT如何處理和回應組合輸入,展示其有效處理複雜語言和視覺任務的能力。

小結
多模態AI在先進量化技術的支援下,將AI系統的效率和反應能力提升到了新水準。LLaVA-NeXT模型能進行語言和視覺任務的複雜處理,展示了這些系統建立更自然、直覺互動的潛力。隨著技術的持續演進,這些先進技術的整合確保AI系統能夠滿足現實世界應用不斷成長的需求,提供強韌而可靠的性能。
透過利用OpenVINO的強大功能和先進的量化方法,我們可以有效部署這些複雜的AI系統,確保它們適應我們的需求,並強化我們與科技的互動。LLaVA-NeXT可用於零售業的智慧購物助理和視覺搜尋任務,或是醫療保健領域的醫學影像分析和複雜檔案的解釋,以及在客戶服務領域進行文字和視覺資訊的查詢。請繼續關注我們對AI技術更進一步發展的探索,以及對多模態AI系統功能的更深入研究!
(參考原文:Mastering Multimodal AI with LLaVA-NeXT and Advanced Quantization Techniques (NNCF)
;編譯:Judith Cheng)

- AI Agent時代來臨:看邊緣AI如何成為驅動智慧機器人的關鍵 - 2025/11/28
- OpenVINO×ExecuTorch:解鎖英特爾架構AI PC模型推論效能新境界 - 2025/11/21
- 讓生成式AI應用在Intel架構系統本地端高效率運作的訣竅 - 2025/10/16
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


