作者:楊亦誠
LangChain是一個強大的框架,目標是幫助開發者使用語言模型構建端對端的應用程式。它提供了一套工具、元件和介面,可簡化創建由大型語言模型(LLM)和聊天模型提供支援的應用程式的過程。透過LangChain,開發者可以輕鬆構建基於RAG或者Agent流水線的複雜應用體系,而目前我們已經可以在LangChain 的關鍵元件LLM、Text Embedding和Reranker中直接呼叫OpenVINO進行模型部署,提升本地RAG和Agent服務的性能,接下來就讓我們一起來看看這些元件的使用方法吧!
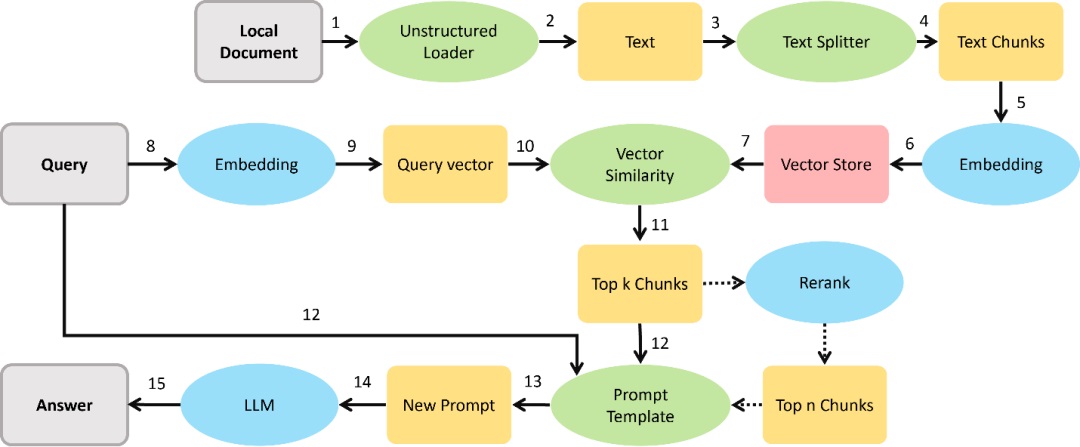
RAG系統參考流水線。
安裝方式
相較常規的LangChain安裝,如果想在LangChain中呼叫OpenVINO,只需再額外安裝 OpenVINO的Optimum-intel組件。其中已經包含對 OpenVINO runtime 以及NNCF等依賴項的安裝。
pip install langchain
pip install --upgrade-strategy eager "optimum[openvino,nncf]"
LLM
大型語言模型是LangChain框架中最核心的模型服務元件,可以實現RAG系統中的答案生成與Agent系統中的規劃和工具呼叫能力,鑒於OpenVINO的Optimum-intel元件目前已經適配了大部分 LLM 的推論任務,並且該套件可以無縫對接HuggingFace的Transformers函式庫,因此在和LangChain的整合中,我們將OpenVINO添加為了 HuggingFace Pipeline 中的一個 Backend後端,並直接重複使用其程式碼。
開發者可透過以下方式在LangChain的 HuggingFace Pipeline中對OpenVINO的LLM物件進行初始化,其中model_id可以是一個HuggingFace的模型ID,也可以是本地的PyTorch或者OpenVINO格式模型路徑:
from langchain_community.llms.huggingface_pipeline import HuggingFacePipeline
ov_config = {"PERFORMANCE_HINT": "LATENCY", "NUM_STREAMS": "1", "CACHE_DIR": ""}
ov_llm = HuggingFacePipeline.from_model_id(
model_id="gpt2",
task="text-generation",
backend="openvino",
model_kwargs={"device": "CPU", "ov_config": ov_config},
pipeline_kwargs={"max_new_tokens": 10},
)
在創建好OpenVINO的LLM模型物件後,我們就可以像呼叫其他LLM元件一樣來部署推論任務。
from langchain_core.prompts import PromptTemplate
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate.from_template(template)
chain = prompt | ov_llm
question = "What is electroencephalography?"
print(chain.invoke({"question": question}))
如果你想把LLM部署在Intel的GPU上,也可以透過修改model_kwargs={“device”: “GPU”}來進行遷移。此外也可以透過Optimum-intel的命令列工具先將模型匯出到本地,再進行部署,這個過程中可以直接匯出INT4量化後的模型格式。
optimum-cli export openvino --model gpt2 --weight-format int4 ov_model_dir
關於OpenVINO LLM元件更多的資訊和使用方式可參考以下連結:
https://python.langchain.com/v0.1/docs/integrations/llms/openvino/
Text Embedding
Text Embedding模型是作用是將文字轉化成特徵向量,以便對基於文字進行相似度檢索,該模型在RAG系統中得到了廣泛應用,期望從Text Embedding任務中得到Top k個候選上下文Context,目前Text Embedding模型可以透過Optimum-intel中的feature-extraction任務進行匯出:
optimum-cli export openvino --model BAAI/bge-small-en --task feature-extraction
在LangChain中,我們可以透過OpenVINOEmbeddings和OpenVINOBgeEmbeddings這兩個物件來部署傳統BERT 類的Embedding模型以及基於BGE的Embedding模型,以下是一個BGE Embedding模型部署範例:
model_name = "BAAI/bge-small-en"
model_kwargs = {"device": "CPU"}
encode_kwargs = {"normalize_embeddings": True}
ov_embeddings = OpenVINOBgeEmbeddings(
model_name_or_path=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
)
embedding = ov_embeddings.embed_query("hi this is harrison")
Reranker
Reranker本質上是一個文字分類模型,透過該模型,我們可以得到每一條候選上下文Context 與問題Query的相似度列表,對其排序後,可以進一步過濾RAG系統中的上下文 Context,Reranker模型可以透過Optimum-intel中的text-classification任務進行匯出:
optimum-cli export openvino --model BAAI/bge-reranker-large --task text-classification
在使用過程中,透過OpenVINOReranker進行創建Renrank任務,搭配 ContextualCompressionRetriever 使用,實現對檢索器Retriever的搜尋結果進行壓縮。透過定義top n大小,可以限制最後輸出的上下文語句數量,例如在下面這個例子中,我們會對檢索器retriever的top k個檢索結果進行重排,並選取其中與Query相似度最高的4個結果,達到進一步壓縮輸入Prompt長度的目的。
model_name = "BAAI/bge-reranker-large"
ov_compressor = OpenVINOReranker(model_name_or_path=model_name, top_n=4)
compression_retriever = ContextualCompressionRetriever(
base_compressor=ov_compressor, base_retriever=retriever
)
關於 OpenVINO Reranker 元件更多的資訊和使用方式可參考以下連結:
https://python.langchain.com/v0.1/docs/integrations/document_transformers/openvino_rerank/
總結
基於OpenVINO的模型任務目前已整合到LangChain框架元件中,開發者能以更便捷的方式,在原本基於LangChain構建的上層AI應用中,取得對於關鍵模型推論性能上的提升。對於Intel的AI PC開發者來說,借助LangChain和 OpenVINO的整合,也能以更低的硬體門檻和資源佔用來創建LLM服務。
參考資料

- 輕薄型筆電OK!利用OpenVINO部署Phi-3.5「全家餐」 - 2024/09/20
- LangChain框架已正式支援OpenVINO! - 2024/06/12
- 如何在Windows平台呼叫NPU部署深度學習模型 - 2024/03/04
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!