在人工智慧(AI)領域,大型語言模型(LLMs)的發展速度令人震驚。2024年4月18日,Meta正式開放了LLama系列的新一代大模型Llama3的原始程式碼,在此領域樹立了新的里程碑。Llama3不僅繼承了先前模型的強大能力,還透過技術革新,在多模態理解、長篇文字處理及語言生成等多個方面實現了品質上的大幅提升,其開放性和靈活性也為開發者提供了前所未有的便利。無論是進行模型微調,還是整合到現有的系統中,Llama3都展現了極高的適應性和易用性。
除此之外,提到Llama3模型的部署,除了將其部署在雲端之外,模型的當地語系化部署可以讓開發者能夠在不依賴雲端運算資源的情況下,實現資料處理和大模型運算的高效率和高隱私性。利用OpenVINO部署Llama3到本地運算資源,例如AI PC,不僅意味著更快的回應速度和更低的運作成本,還能有效地保護資料安全,防止敏感資訊外洩。這對於需要處理高度敏感性資料的應用場景尤其重要,如醫療、金融和個人助理等領域。
本文將從Llama3模型簡介出發,教大家如何使用OpenVINO對Llama3模型進行最佳化和推論加速,並將其部署在本地裝置上,進行更快、更智慧的AI推論。
Llama3模型簡介
Llama3提供了多種參數量級的模型,如8B和70B參數模型。其核心特點和優勢可總結如下:
- 先進的能力與強大的性能:Llama3模型提供了在推論、語言生成和程式碼執行等方面的SOTA性能,為大型語言模型(LLMs)設定了新的產業標準。
- 增強的效率:採用僅解碼器的Transformer架構與分組查詢注意力(Group Query Attention,GQA),最佳化了語言編碼效率和運算資源使用,適用於大規模AI任務。
- 全面性的訓練與微調:在超過15兆tokens上進行預訓練,並透過SFT和PPO等創新的指令微調技術,Llama3在處理複雜的多語言任務和多樣化的AI應用中表現卓越。
- 聚焦開源社群:作為Meta開源倡議的一部分發佈,Llama3鼓勵社群參與和創新,開發者可以輕鬆造訪其生態系並貢獻其成果。
利用OpenVINO最佳化並加速推論
如前所述,部署Llama3模型到本地裝置上,不僅意味著更快的回應速度和更低的運作成本,還能有效地保護資料安全,防止敏感資訊外泄。因此,本文將重點介紹如何利用OpenVINO將Llama3模型進行最佳化後,再部署到本地裝置。這個過程包括以下具體步驟,使用的是我們常用的OpenVINO Notebooks GitHub儲存庫中的llm-chatbot 程式碼範例。詳細資訊和完整的原始程式碼可以在此連結找到。
由安裝必備軟體套件開始
運作OpenVINO Notebooks儲存庫的具體安裝指南請點此連結;執行這個llm-chatbot的程式碼範例,需要安裝以下的必備依賴項目(dependencies)套件。
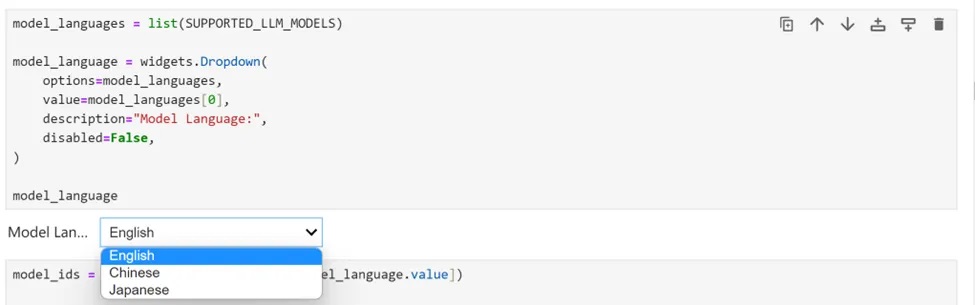
選擇推論模型
由於我們在Jupyter Notebook展示中提供了一組由OpenVINO支援的多語種大語言模型,可以從下拉清單中首先選擇語言;針對Llama3,我們選擇英語。
接下來選擇「llama-3-8b-instruct」來執行該模型的其餘最佳化和推論加速步驟。當然,很容易切換到其他列出的任意模型。
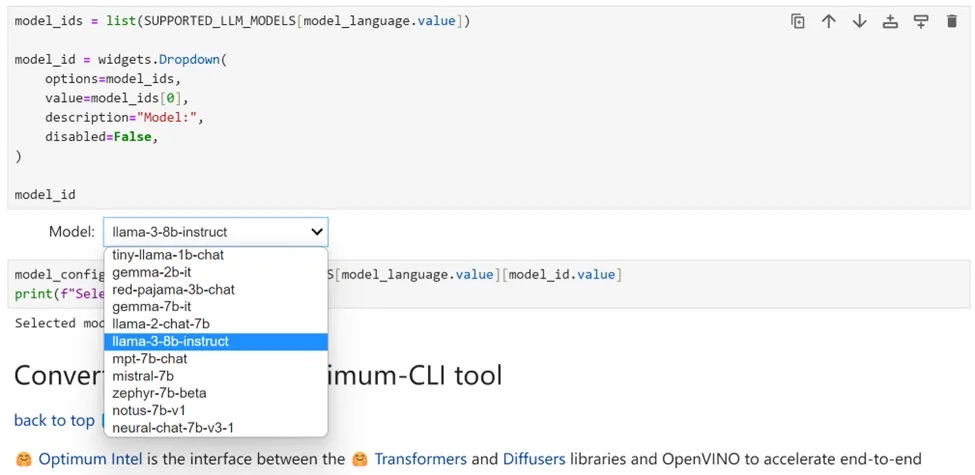
使用Optimum-CLI進行模型轉換
Optimum Intel是Hugging Face Transformers和Diffuser程式庫與OpenVINO之間的介面,用於加速Intel體系結構上的端對端流水線。它提供了易於使用的cli介面,即命令列介面,用於將模型匯出為OpenVINO的IR格式。使用下面的一行命令,就可以完成模型的匯出:
optimum-cli export openvino --model --task
其中,--model參數是來自HuggingFace Hub的模型ID,或具備模型ID、已經將模型下載到本地目錄的路徑位址(使用.save_pretrained方法保存),--task是匯出模型應解決的支援任務之一。對於LLM,它會是text-generation-with-past。如果模型初始化需要使用遠端程式碼,則應額外傳遞–trust-remote-code遠端程式碼標誌。
模型權重壓縮
儘管像Llama-3-8B-Instruct這樣的LLM在理解和生成類人文字方面變得越來越強大和複雜,但管理和部署這些模型在運算資源、記憶體佔用、推論速度等方面帶來了關鍵挑戰,尤其是對於AI PC這種客戶端設備。權重壓縮演算法旨在壓縮模型的權重,並可用於最佳化大型模型的模型佔用空間和性能,其中權重的大小相對大於激勵(activations)的大小,例如LLM。與INT8壓縮相比,INT4壓縮可以進一步壓縮模型大小,並提升文字生成性能,但預測品質略有下降。因此,在這裡我們選擇模型權重壓縮為INT4精度。

當使用Optimum-CLI匯出模型時,還可以選擇在線性、卷積和嵌入層上應用FP16、INT8位元或INT4位元權重壓縮。使用方法非常簡便,就是將--weight格式分別設置為fp16、int8或int4。這種類型的最佳化能減少記憶體佔用和推論延遲,預設情況下,int8/int4的量化方案將是不對稱的量化壓縮。如果需要使用對稱壓縮,可以添加--sym。
對Llama-3-8B-Instruct模型進行INT4量化,我們指定以下參數:
compression_configs = {
"llama-3-8b-instruct": {
"sym": True,
"group_size": 128,
"ratio": 0.8,
},
}
--group size參數將定義用於量化的群組大小,為128。
--ratio參數控制4位和8位量化之間的比例。這意味著80%的層將被量化為int4,而20%的層將量化為int8。
執行Optimum-CLI進行模型的下載及權重壓縮的命令如下:
optimum-cli export openvino --model "llama-3-8b-instruct" --task text-generation-with-past --weight-format int4
--group-size 128 --ratio 0.8 --sym
執行上述命令後,模型將從Hugging Face Hub自動下載Llama-3-8B-Instruct模型,並進行相對應的模型壓縮操作。
對於模型下載有困難的開發者,也可以從ModelScope開源社群的以下連結:
透過Git的方式進行下載:
git clone https://www.modelscope.cn/LLM-Research/Meta-Llama-3-8B-Instruct.git
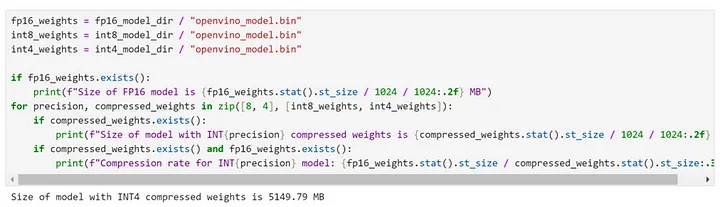
經過權重壓縮後,我們可以看到,8B模型的體積大小已經被壓縮為僅有5GB左右。
選擇推論裝置和模型變體
由於OpenVINO能夠在一系列硬體裝置上輕鬆部署,因此還提供了一個下拉選單可供選擇執行推論的裝置。考量到模型尺寸和性能需求,在這裡我們選擇搭載了Intel Core Ultra7 155H處理器之AI PC的GPU作為推論裝置。
使用Optimum Intel產生實體模型
Optimum Intel可用於載入已下載到本地並透過權重壓縮完成最佳化的模型,並建立推論流水線,透過Hugging FaceAPI使用OpenVINO Runtime執行推論。在這種情況下,這意味著我們只需要將AutoModelForXxx類別替換為相對應的OVModelForXxx類別,就能設置並執行Llama-3-8B-Instruct的推論流水線。
運作聊天機器人
現在萬事具備,在這個Notebook程式碼範例中,我們還提供了一個基於Gradio的使用者友善介面。現在就讓我們運作聊天機器人吧!
小結
關於英特爾OpenVINO工具套件的詳細資料,包括其中我們提供的300百多個經驗證並最佳化的預訓練模型的詳細資料,請點擊以下連結:
https://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit/overview.html
除此之外,為了方便大家快速掌握OpenVINO的使用,我們還提供了一系列開源的 Jupyter Notebook範例。執行這些Notebook,就能快速了解在不同場景下如何利用OpenVINO實現一系列、包括電腦視覺、語音及自然語言處理任務。
OpenVINO Notebooks資源可以在 GitHub 下載安裝:https://github.com/openvinotoolkit/openvino_notebooks 。

- AI Agent時代來臨:看邊緣AI如何成為驅動智慧機器人的關鍵 - 2025/11/28
- OpenVINO×ExecuTorch:解鎖英特爾架構AI PC模型推論效能新境界 - 2025/11/21
- 讓生成式AI應用在Intel架構系統本地端高效率運作的訣竅 - 2025/10/16
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


