作者:楊亦誠
針對大語言模型(LLM)在部署過程中的性能需求,低位元量化技術一直是優化效果最佳的方案之一,本文將探討低位元量化技術如何幫助LLM提升性能,以及新版OpenVINO 對於低位元量化技術的支援。
大模型性能瓶頸
相比運算量的增加,大模型推論速度更容易受到記憶體頻寬的影響(memory bound),也就是記憶體讀寫效率問題,這是因為大模型由於參數量巨大、訪存量遠超記憶體頻寬容量,意味著模型的權重的讀寫速度跟不上硬體對於運算元的運算強度,導致算力資源無法得到充分發揮,進而影響性能。
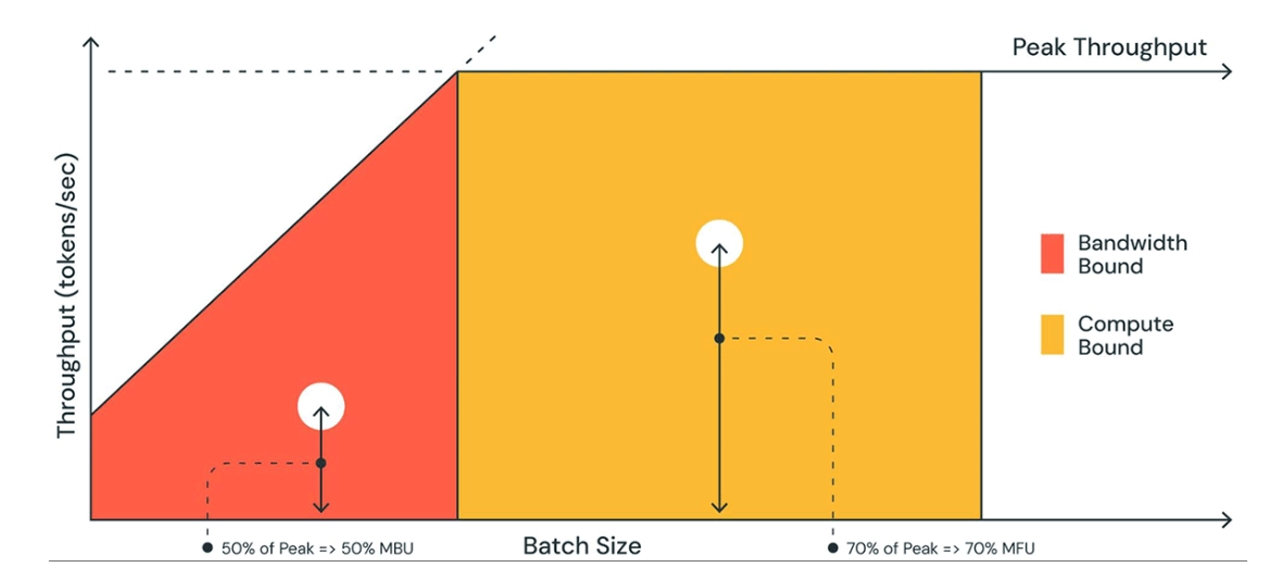
memory bound與compute bound比較
低位元量化技術
低位元量化技術是指將模型參數從fp32/fp16壓縮到更低的位元位寬表達,在不影響模型輸出準確性和參數量的情況下,降低模型體積,從而減少緩衝記憶體對於資料讀寫的壓力,提升推論性能。由於大模型中單個layer上的權重體積往往要遠大於該layer的輸入資料(activation),因此針對大模型的量化技術往往只會針對關鍵的權重參數進行量化(WeightOnly),而不對輸入資料進行量化,在到達理想的壓縮比的同時,盡可能保證輸出結果,實現最高的量化「性價比」。
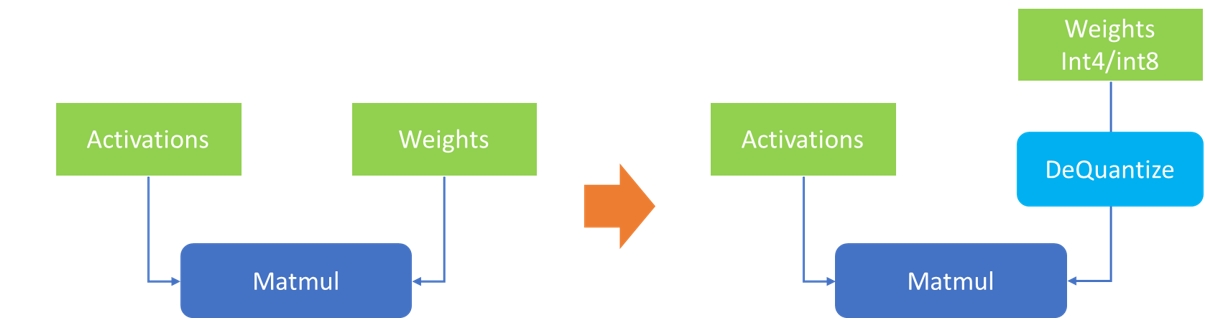
權重壓縮示意
經驗證常規的int8權重量化,對大模型準確性的影響極低,而為了導入像int4,nf4這樣的、更極致的壓縮精度,目前在權重量化演算法上也經過了一些探索,其中比較典型的就是GPTQ演算法,簡單來說,GPTQ對某個block內的所有參數逐個量化,每個參數量化後,需要適當調整這個block內其他未量化的參數,以彌補量化造成的精度損失。GPTQ 量化需要準備校準資料集,因此他也是一種PTQ (Post Training Quantization)量化技術。
OpenVINO更多的新功能陸續問世!新版本將新增對新硬體以及更多生成式AI模型的支援,在2024年的新開始,讓我們一起透過免費線上講座「掌握OpenVINO在生成式AI最新功能, 並實現Model Server創新應用」來探索這套越來越強大的工具,讓您的專案開發更如虎添翼,名額有限快來報名!
OpenVINO 2023.2對於int4模型的支援
OpenVINO 2023.2相較2023.1版本,全面導入對int4模型以及量化技術的支援。主要有以下2個方面:
1. CPU及iGPU支援原生int4模型推論
OpenVINO 工具目前已經可以直接讀取經NNCF量化以後的int4模型,或者是將HuggingFace中使用AutoGPTQ庫量化的模型轉換後,進行讀取及編譯。由於目前的OpenVINO後端硬體無法直接支援int4資料格式的運算,所以在模型執行過程中,OpenVINO runtime會把int4的權重反量化的到FP16或是BF16的精度進行運算。簡而言之:模型以int4精度儲存,以fp16精度運算,用運算成本換取空間及IO成本,提升運作效率。這也是因為大模型的性能瓶頸主要來源於memory bound,用更高的資料讀寫效率,降低對於記憶體頻寬與記憶體容量的開銷。
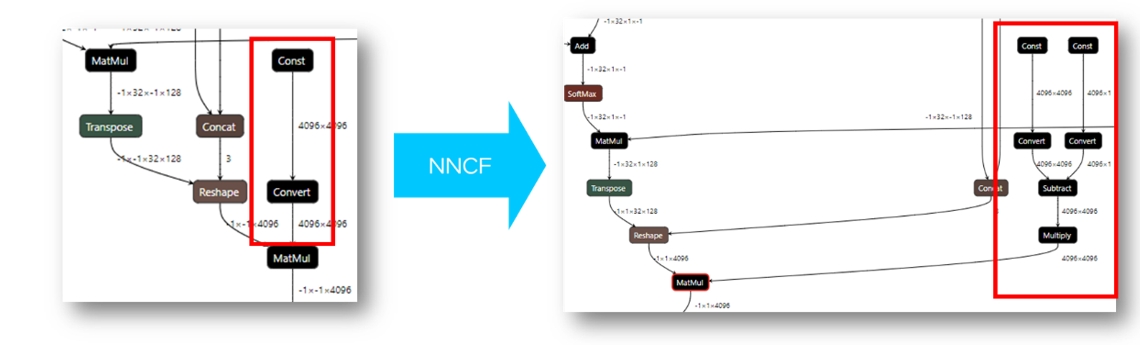
經NNCF權重壓縮後的模型結構
2. NNCF工具支援int4的混合精度量化策略(Weights Compression)
剛提到的GPTQ是一種data-based的量化方案,需要提前準備校驗資料集,借助HuggingFace的Transformers和AutoGPTQ資源庫可以完成這一操作。而為了幫助開發者縮短LLM模型的壓縮時間、降低量化門檻,NNCF工具在2.7.0版本中導入了針對int4以及nf4精度的權重壓縮模式,這是一種data-free的混合精度量化演算法,無需準備校驗資料集,僅對LLM中的Linear 和Embedding layers展開權重壓縮。整個過程僅用一行程式碼就可以完成:
compressed_model = compress_weights(model, mode=CompressWeightsMode.NF4, group_size=64, ratio=0.9)
其中model為PyTorch或OpenVINO的模型物件;mode代表量化模式,這裡可以選擇CompressWeightsMode.NF4,或是CompressWeightsMode.INT4_ASYM/INT4_SYM等不同模式;為了提升量化效率,Weights Compression使用的是分組量化的策略(grouped quantization),因此需要透過group_size配置組的大小,例如group_size=64意味64個channel的參數將共用同一組量化參數(zero point, scale value);此外鑒於data-free的int4量化策略是會帶來一定的準確度損失,為了平衡模型體積和準確度,Weights Compression還支持混合精度的策略,透過定義ratio值,我們可以將一部分對準確度敏感的權重用int8表示,例如在ratio=0.9的情況下,90%的權重用int4表示,10%用int8表示,開發者可以根據量化後模型的輸出結果調整這個參數。
在量化過程中,NNCF會透過搜尋的方式,逐層比較偽量化後的權重和原始浮點權重的差異(https://github.com/openvinotoolkit/nncf/blob/5eee3bc293da2e94b30cb8dd19da9f20fce95f02/nncf/quantization/algorithms/weight_compression/openvino_backend.py#L409C5-L409C5),衡量量化操作對每個layer可能帶來的誤差損失,並根據排序結果以及使用者定義的ratio值,將損失相對較低的權重壓縮到int4位寬。
中文大語言模型實踐
隨著OpenVINO 2023.2的發佈,大語言模型的int4壓縮示例也被添加到了openvino_notebooks資源庫中(https://github.com/OpenVINO-dev-contest/openvino_notebooks/tree/main/notebooks/254-llm-chatbot),這次特別新增了針對中文LLM的範例,包括目前熱門模型ChatGLM2和Qwen。在這個notebook中,開發者可以體驗如何從HuggingFace的資源庫中匯出一個OpenVINO IR格式的模型,並透過NNCF工具進行低位元量化,最終完成一個聊天機器人的構建。
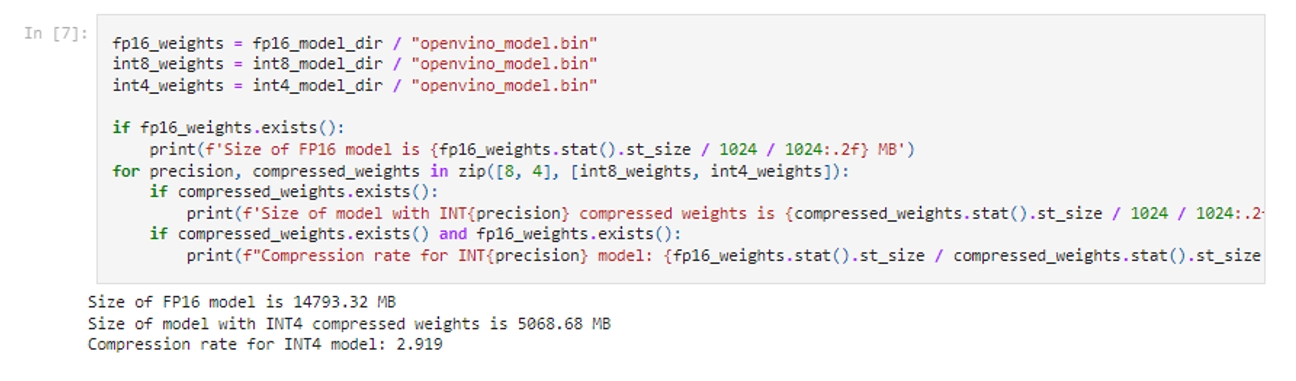
fp16與int4模型空間佔用比較
透過以上這個截圖可以看到,qwen-7b-chat經過NNCF的int4量化後,可以將體積壓縮到原本fp16模型的1/3,這樣使得一台16GB記憶體的筆記型電腦,就可以流暢運作壓縮以後的ChatGLM2模型。此外我們還可以透過將LLM模型部署於Intel Core CPU的整合式顯卡上,在提升性能的同時,減輕CPU側的任務負載。
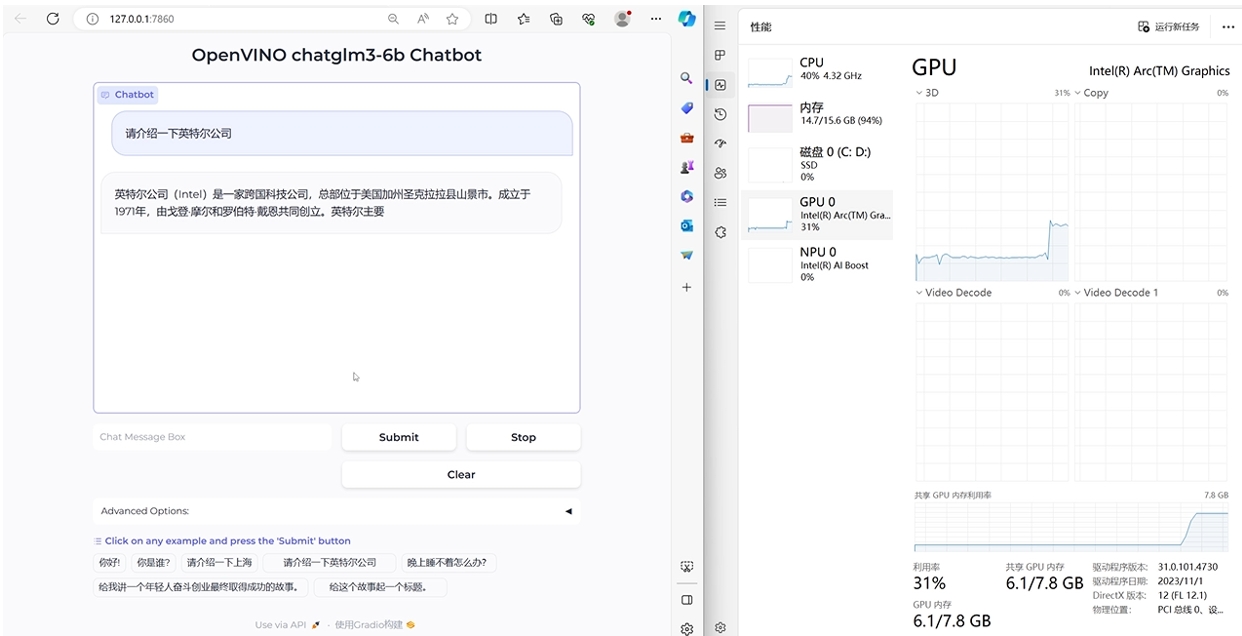
Notebook運作效果
總結
OpenVINO 2023.2中對int4 權重量化的支援,可以全面提升大模型在Intel平台上的運作性能,同時降低對於儲存和記憶體的容量需求,降低開發者在部署大模型時的門檻,讓當地語系化的大語言模型應用在普通PC上落地成為可能。
參考項目位址:
- https://github.com/openvinotoolkit/openvino_notebooks/tree/main/notebooks/254-llm-chatbot
- https://github.com/openvinotoolkit/nncf/tree/5eee3bc293da2e94b30cb8dd19da9f20fce95f02/nncf/quantization/algorithms/weight_compression

- 輕薄型筆電OK!利用OpenVINO部署Phi-3.5「全家餐」 - 2024/09/20
- LangChain框架已正式支援OpenVINO! - 2024/06/12
- 如何在Windows平台呼叫NPU部署深度學習模型 - 2024/03/04
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


