作者:高煥堂、鄭仲平
上一篇文章說明了如何利用英特爾(Intel)所研發的新產品:IPEX (Intel-Extension-for-PyTorch )軟體搭配GPU硬體,並透過 PyTorch的<xpu>裝置來發揮GPU潛能,大幅加速AI模型的訓練和推論;同時也以<ResNet + LoRA>微調訓練的範例,來說明其使用方法和流程。而與上述兩項產品息息相關的重要技術是:
- BF16半精度浮點數。2721
- 將影像資料設為 Channel_last資料格式(即NHWC格式)。
本文就要來介紹以上這兩項技術,並延續上一篇的<ResNet50 + LoRA>微調模型訓練,以完整程式碼示範如何發揮這兩項新技術的用法和魅力。
這兩項技術常常互相搭配,以提供進階的最佳化效益。例如在大語言模型(LLM)中,常常採取自動混合精度(Automatic mixed precision)訓練模式,此時會在模型訓練過程中,針對各層(Layer)而選擇不同的資料精度(如FP32或BF16等),來搭配不同的影像資料格式(如NCHW或NHWC),從而實現節省記憶體,並加快訓練速度之目的。
使用BF16半精度浮點數格式
簡介BF16單精度浮點數格式
首先複習一下,在電腦裡的數值常分為整數(integer)與浮點數(floating point)兩種。例如,一隻獵狗的年紀(如5歲),即是一個整數。而它的體重是11.753公斤,這即是浮點數。其中,浮點數的電腦儲存格式又可分為:單精度浮點數(float)與雙精度浮點數(double)兩種。而單精度浮點數(全名:Single-precision floating-point)又分為三種,如圖1所示:
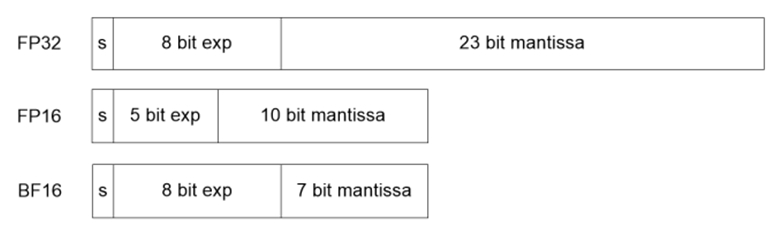
圖1:單精度與半精度浮點數格式
在圖1,FP32是IEEE 754-2008 方案的單精度浮點數格式,為32位元長度。而FP16(又稱為float16),它的全名稱是:半精度浮點數(Half-precision floating-point)。至於BF16,又稱為:bfloat16 (全名是:Brain float point)浮點格式。它使用16位元(2位元組)來儲存一個浮點數。如圖1所示,分為三部分:
- 符號(Sign):佔1位元,0代表正值,1代表負值。
- 指數(Exponent):佔8位元。
- 尾數(Mantissa):佔7位元。
例如,32767這個數值,以科學計數法可以寫成3.2767*10^(4)。其中3.2767即是尾數,而4即為指數。
從圖1可以看出,FP32格式擁有比較長的尾數(23位元),能表達很高精確度的數值。它的指數部分(8位元),是用來表達其數值大小的有效範圍,又稱:動態範圍(dynamic range)。
接下來比較看看FP16與BF16的差別。FP16 較 BF16 擁有更長的尾數,但指數部分較短。因此 FP16 的精(確)度高於BF16。採用BF16格式的用意是藉由降低精度,來換取較大的有效範圍。
OpenVINO更多的新功能陸續問世!新版本將新增對新硬體以及更多生成式AI模型的支援,在2024年的新開始,讓我們一起透過免費線上講座「掌握OpenVINO在生成式AI最新功能, 並實現Model Server創新應用」來探索這套越來越強大的工具,讓您的專案開發更如虎添翼,名額有限快來報名!
從機器學習(ML)的角度看BF16的特性
為什麼要特別提到這BF16格式呢? 因為它是專為人工智慧(AI) / 深度學習(DL)的張量(Tensor)運算最佳化發展而來。它原來是由Google Brain團隊發明,並使用於其第三代Tensor Processing Unit (TPU),用來降低記憶體(Memory)存儲需求。如今已被許多公司(如Intel、Arm等)的AI加速器廣泛採用。
採用BF16格式的用意是藉由降低數值的精確度,來減少讓張量相乘所需的運算資源和功耗。目前有許多ML運算使用FP32格式,雖然可以達到非常準確的運算,但需要強大的硬體而且極其耗電。而BF16雖然較低精度,但在相同硬體上的傳輸效率,因而更省電,只是預測的準確性較低一些。
例如,在大語言模型(LLM)的訓練任務中是更重要的,由於注意力(Attention)機制中使用了大量的exp運算,此時更大的有效範圍比精確度更為重要。因為在訓練時梯度很容易超過FP16的表示範圍,導致訓練loss值爆掉,而BF16表示範圍跟FP32一致,訓練模型時就穩定多了。
使用<IPEX + GPU + BF16>環境訓練
在上一篇文章裡,曾經建置了<IPEX + GPU>訓練環境。在本篇裡,就來加以擴大,採用BF16半精度浮點數格式。並延續上一篇的<ResNet50 + LoRA>模型訓練範例,來觀察BF16對性能優化的貢獻。
Step-c1:準備訓練資料(Training data)
本篇範例使用的訓練資料集,與上一篇(第2篇)的訓練資料集是相同的。請您參考上一篇文章的說明。
Step-c2: 定義<ResNet50+LoRA>模型,並展開訓練
本範例的<ResNet50 + LoRA>整合模型,與上一篇文章的模型是一致的(訓練資料集也是一致的),請您參閱其中的說明。在本範例裡,只是將原來的<IPEX + GPU>訓練環境,擴大為<IPEX + GPU + BF16>而已。此範例的程式碼如下:
# lora_RESNET_basic_003_train_xpu_bf16_cl.py
import numpy as np
import torch
import torch.nn as nn
from torchvision import transforms
from torchvision.datasets import ImageFolder
from torch.utils.data import Dataset, DataLoader
from torchvision.models import resnet50, ResNet50_Weights
import time
data_path = '/home/eapet/resnet_LoRA/m_data/train/'
base_path = '/home/eapet/resnet_LoRA/m_data/'
# Make torch deterministic
# 設定:每次訓練的W&B初始化都是一樣的
_ = torch.manual_seed(0)
#-------------------------------------
# 載入ResNet50預訓練模型
# Step 1: Initialize model with the best available weights
weights = ResNet50_Weights.IMAGENET1K_V1
resnet_model = resnet50(weights=weights)
# 遷移學習不需要梯度(不更改權重)
for param in resnet_model.parameters():
param.requires_grad = False
#-------------------------------
resnet_model.eval()
#------------------------------------------
# 準備Training data
# 把圖片轉換成Tensor
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor()
])
data_set = ImageFolder(data_path, transform=transform)
length = len(data_set)
print("\n")
print(length, "張圖片\n")
bz = 60
test_loader = DataLoader(data_set, batch_size=bz, shuffle=True)
#--------------------------------------
def process_lx(labels):
lx = labels.clone()
for i in range(bz):
if(labels[i]==0):
lx[i]=340
elif(labels[i]==1):
lx[i]=24
elif(labels[i]==2):
lx[i]=947
return lx
for idx, (images, la) in enumerate(test_loader):
break
labels = process_lx(la)
print(labels)
#-----------------------------------
def test():
correct = 0
total = 0
wrong_counts = [0 for i in range(3)]
with torch.no_grad():
for idx, (images, la) in enumerate(test_loader):
labels = process_lx(la)
prediction = resnet_model(images)
for idx, zv in enumerate(prediction):
if torch.argmax(zv) == labels[idx]:
correct +=1
else:
#print(idx)
wrong_counts[la[idx]] +=1
total +=1
#print(correct)
print('\n', f'Accuracy: {round(correct/total, 3)}')
for i in range(len(wrong_counts)):
print(f'wrong counts for the digit {i}: {wrong_counts[i]}')
#------------------------------------------
print('\n------ 原模型測試: ------')
test()
#==========================================
class Lora(nn.Module):
def __init__(self, m, n, rank=10):
super().__init__()
self.m = m
self.A = nn.Parameter(torch.randn(m, rank))
self.B = nn.Parameter(torch.zeros(rank, n))
def forward(self, inputs):
#print(inputs.shape)
#inputs = inputs.view(-1, self.m)
inputs = torch.reshape(inputs, [60,3*224*224])
#print(self.m)
return torch.mm(torch.mm(inputs, self.A), self.B)
lora = Lora(224 * 224 * 3, 1000)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(lora.parameters(), lr=1e-4)
#========================================================
print('\n------ 外掛LoRA模型,協同訓練: ------')
import intel_extension_for_pytorch as ipex
resnet_model = resnet_model.to(memory_format=torch.channels_last)
#lora = lora.to(memory_format=torch.channels_last)
loss_fn = loss_fn.to("xpu")
lora = lora.to("xpu")
lora, optimizer = ipex.optimize(lora, optimizer=optimizer, dtype=torch.bfloat16)
resnet_model = resnet_model.to("xpu")
resnet_model = ipex.optimize(resnet_model, dtype=torch.bfloat16)
base = 0
epochs = 100
begin = time.time()
for ep in range(epochs+1):
total_loss = 0
for idx, (images, la) in enumerate(test_loader):
labels = process_lx(la)
images = images.to("xpu")
labels = labels.to("xpu")
images =images.to(memory_format=torch.channels_last)
with torch.xpu.amp.autocast(enabled=True, dtype=torch.bfloat16):
pred = resnet_model(images) + lora(images)
loss = loss_fn(pred, labels)
loss.backward()
optimizer.step()
optimizer.zero_grad()
total_loss += loss.item() * bz
if((base+ep)%5 == 0):
loss_np = total_loss / 120
print('ep=', base+ep,'/',base+epochs, ', loss=', loss_np)
end = time.time()
print("TTT =", end-begin)
#------ Saved to *.CKPT ---------------------------
FILE = base_path + 'LORA_for_RESNET_ep50.ckpt'
torch.save(lora.state_dict(), FILE)
print('\nsaved to ' + FILE)
#-------------------------------------
def test22():
correct = 0
total = 0
wrong_counts = [0 for i in range(3)]
with torch.no_grad():
for idx, (images, la) in enumerate(test_loader):
labels = process_lx(la)
images = images.to("xpu")
labels = labels.to("xpu")
with torch.xpu.amp.autocast(enabled=True, dtype=torch.bfloat16):
prediction = resnet_model(images) + lora(images)
for idx, zv in enumerate(prediction):
if torch.argmax(zv) == labels[idx]:
correct +=1
else:
#print(idx)
wrong_counts[la[idx]] +=1
total +=1
#print(correct)
print('\n', f'Accuracy: {round(correct/total, 3)}')
for i in range(len(wrong_counts)):
print(f'wrong counts for the digit {i}: {wrong_counts[i]}')
#------------------------------------------
print('\n------ 原模型測試: ------')
test22()
#------------------------
#END
此範例使用Pytorch的指令:
lora = lora.to("xpu")
lora, optimizer = ipex.optimize(lora, optimizer=optimizer, dtype=torch.bfloat16)
resnet_model = resnet_model.to("xpu")
resnet_model = ipex.optimize(resnet_model, dtype=torch.bfloat16)
其設定由GPU來執行這lora模型和resnet_model模型。並且設定兩個模型的優化器(Optimizer)都採取BF16浮點數,也就是反向傳播的計算時採取BF16浮點數。繼續使用指令:
with torch.xpu.amp.autocast(enabled=True, dtype=torch.bfloat16):
prediction = resnet_model(images) + lora(images)
其設定兩個模型的正向推演計算時,也採取BF16浮點數。如下圖所示:
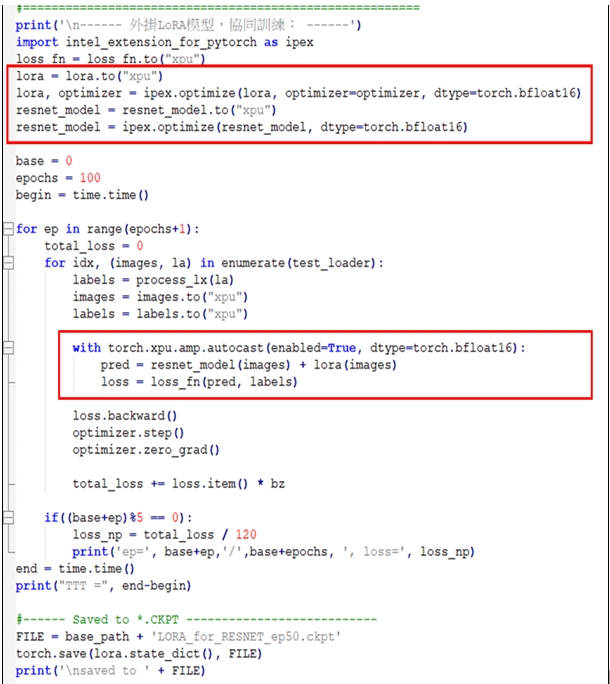
請仔細觀察這程式的執行情境:它使用<IPEX+GPU+BF16>環境,並搭配Windows或Ubuntu作業系統來展開協同訓練。例如,在Ubuntu環境裡,使用命令(Command):
就展開訓練100回合,執行結果顯示如下圖:
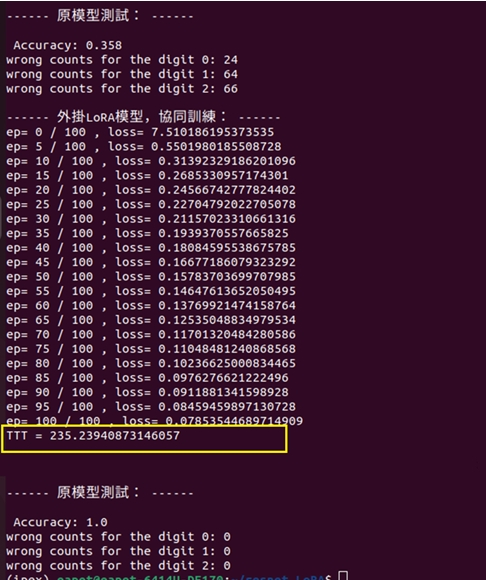
從上圖的訓練輸出結果,我們可以觀察到:在上一篇文章裡,曾採取<IPEX+GPU>的軟硬體搭配的模式,針在單純CPU環境下進行訓練,我們把LoRA外掛到ResNet50,然後進行協同訓練100回合,其訓練的耗時為:235秒。
而在本範例裡,採取<IPEX+GPU+BF16>的軟硬體搭配的模式,針對相同的<ResNet50 + LoRa>模型,一樣進行訓練100回合,其訓練的耗時很明顯,已經下降為210秒;這呈現出BF16浮點數的加速效益了。
使用NHWC影像資料格式
從顏色(Color)特徵說起
著名的物理學家牛頓首先發現了光的三原色:RGB(紅藍綠)。R是代表紅色(Red)、G代表綠色(Green)、B代表藍色(Blue)。RGB這三種顏色的組合,可形成各種不同的顏色。例如紅色與綠色按各種比例混合而形成黃色(系列)了。
大家都知道,白光通過稜鏡後被分解成多種顏色,依序為:紅、橙、黃、綠、藍、靛、紫。當年牛頓就發現了,其中的紅、綠、藍三種色光是無法被分解的,所以就稱之為「光的三原色」。

圖2:光的三原色
這三原色的色純度最高,最純淨、最鮮豔,可以調配出絕大多數色彩。例如,您的電腦螢幕的色彩也是這樣組合而成的。換句話說,像電視機或電腦的彩色螢幕都是具備產生上述三原色光的發光設備,所以電腦就依據R、G、B三個數值的大小來表示每一個像素(Pixel)的顏色。
像素(Pixel)
在電腦領域裡,每一幅螢幕畫面或一張圖片,都是由許多小光點所組成的,其中一個小光點就稱為一個像素。由像素所組成的圖像,通稱為數位圖像。簡而言之,像素就是圖像的點的數值,然後從點連成線,線再組合成面。例如,常見的JPG格式的數位圖像的彩色採樣點,即是像素。
電視、電腦或照相機經常會強調像素與解析度(Resolution)。像素高表示小光點很多,而解析度很高,則表示小光點很密集,人們眼睛會感覺圖像清晰細緻。每一個像素都具有三個數值,代表紅光、綠光、藍光的亮度;就是剛才所介紹的RGB三色光。經由三色光的疊合來得到各種顏色。在電腦中,以整數 0 ~ 255的值來代表小光點的R、G和B的亮度。其中0是最暗,255 是最亮。例如,當RGB都是255時,疊合之後就呈現出白光。因此白色光的RGB值常表示為:[255,255,255]。反之,當RGB值為[0,0,0]時,就是無光、呈現黑色。再如,當RGB值為[0,255,0]時,就是綠色。如圖3所示:
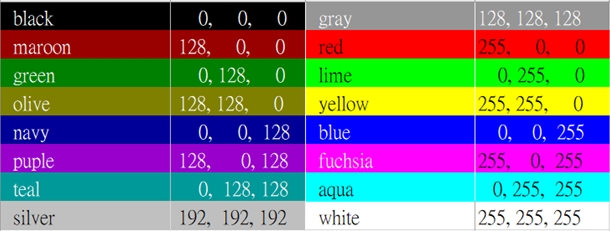
圖3:像素與RGB值
以上所述的三原色,其原理並不是出於物理原因,而是由於人體的生理原因所造成的。人們的眼睛內有三種錐型感光細胞,這種細胞有感受顏色的物質。當三原色的光以不同的比例複合後,就會對三種錐形細胞產生刺激,就能對人的眼睛形成與各種頻率的可見光等效的色覺了。
說明影像資料的格式
剛才說明了,一個彩色像素(Pixel)都有RGB三個值。那麼,每一張彩色圖片(Image),也就具有高度(Height),寬度(With)和顏色通道(Channel)三個維度。這裡的顏色通道,即是RGB值。例如,一張圖像裡含有3個像素,如下圖所示:
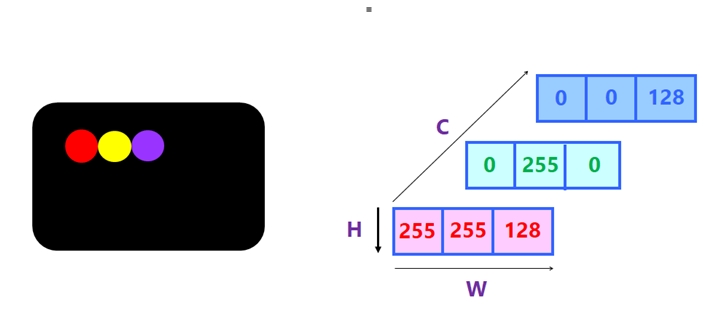
圖4:影像的資料格式
所以,當我們把一張圖片表示為三維陣列時,通常有兩種格式(Data_format),就是:
- 通道在後(Channels Last)。此格式的最後維度代表顏色通道,亦即:[height], [with], [channel]。如果也表示圖片的張數(Number 或Btach),就成為:[number], [height], [with], [channel]了。其簡稱為:NHWC格式。如圖5所示:
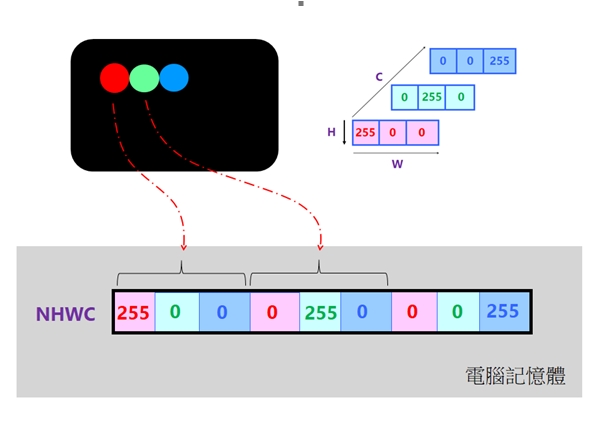
圖5:NHWC資料格式
從圖5可以看出來,這NHWC格式的特性是:逐像素地儲存。
- 通道在先(Channels First)。此格式的第一通道代表顏色通道,例如彩色通道。 [channel],[height],[with]。如果添加上圖片張數(Number或Batch),就成為:[number], [channel], [height], [with], [channel]了。其簡稱為:NCHW格式。
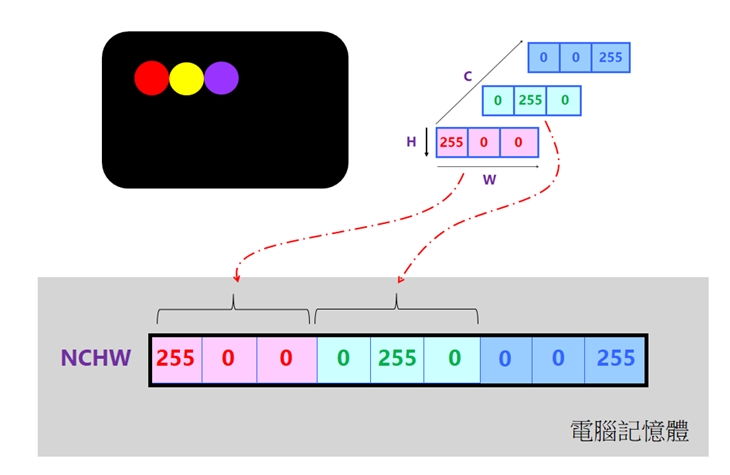
圖6:NCHW資料格式
其中的N表示這批圖片有幾張,H表示圖片在垂直方向有多少像素,W表示水平方向像素,C表示通道數(例如黑白圖片的通道數C=1,而 RGB彩色圖片的通道數C=3)。從圖6可以看出來,在電腦記憶體裡,其佈局是把各通道的所有像素值都儲存在一塊連續的空間裡。它比較方便於對各通道單獨做運算的操作。
從機器學習看兩種影像資料格式
當今流行的機器學習(ML)框架中,常用的就是剛才所介紹的NHWC和NCHW格式。一般而言,在不同的硬體加速的需求情況下,會採取不同的格式。由於NCHW格式更適合那些需要對每個通道單獨做運算的操作。例如在進行CNN模型的卷積運算(如「MaxPooling」)時,若希望在訪問同一個通道(Channel)的像素是連續的,就會選用NCHW格式。
然而,NHWC格式則更有利於處理多通道的圖像資料,它在處理多通道圖像資料時,可以更高效地利用硬體的計算資源。因為它更方便支援不同通道的圖像資料同時輸入到卷積核中去計算。
再如,當採取自動混合精度(Automatic mixed precision)訓練模式時,會在模型訓練過程中,針對各層(Layer)而選擇不同的資料精度(如FP32或BF16等),來搭配不同的圖像資料格式(如NCHW或NHWC),從而實現節省記憶體,並加快訓練速度之目的。其中的BF16常搭配NHWC格式來進行效能優化,因為有些常用機器學習運算(如MaxPool2d),若搭配NHWC就更容易實現向量化,而大幅優化性能。
從Pytorch看兩種影像資料格式
當今最流行的AI模型框架是PyTorch,其預設的是NCHW (即Channels First)格式。由於其記憶體佈局是把各通道的所有像素值都儲存在一塊連續的空間裡。所以又稱之為:連續格式(Contiguous_format)。Pytorch 提供了tensor.is_contiguous() 函數可以用來檢查當前的圖像張量(Tensor)是屬於NCHW還是NHWC格式。一般而言,在Pytorch裡有些運算搭配NCHW會比較好;反之,有些運算搭配NHWC則會比較好:
- 與NHWC比較友善的運算有:Conv2d,MaxPool2d ConvTransposed2d,UpsampleNearest2d等。
- 與NCHW比較友善的運算有:GroupNorm2d,ChannelShuffle,PixelShuffle等。
其中,NHWC格式的特性是:我們可以在NHWC記憶體格式的最核心維度上進行向量化。例如,就可為AVX2和AVX512來建構出向量化CPU核心。亦即,NHWC的性能優化是在模型的核心層級實現的,這提供機會可搭配NHWC一起應用,來進行性能最佳化。例如,對於卷積層的池化(Pooling)和上採樣(Upsampling)層,這NHWC可以沿最內部維度進行向量化。其能應用於GPU和CPU上來實現高達22%以上的效能提升。這項最佳化動作,就無法在NCHW上實現。
使用IPEX+GPU+BF16+NHWC環境訓練
剛才說明了,AI模型訓練師可以活用IPEX來搭配Intel的CPU 與 GPU系列產品,然後透過 PyTorch的<xpu>裝置來最佳化它們,發揮其潛在威力,將效能與效率提升至全新的境界。
Step-d1:準備訓練資料(Training data)
本篇範例使用的訓練資料集,與上一篇文章的訓練資料集是相同的,請參考其中的說明。
Step-c2: 定義<ResNet50+LoRA>模型,並展開訓練
本範例的<ResNet50 + LoRA>整合模型,與上一篇文章的模型是一致的(訓練資料集也是一致的),請參閱其中說明;在本範例裡,只是將原來的訓練環境,擴大為<IPEX + GPU + BF16 + CL>而已,這裡的CL就是「Channel Last」的簡寫。此範例的程式碼如下:
# lora_RESNET_basic_003_train_xpu_bf16_cl.py
import numpy as np
import torch
import torch.nn as nn
from torchvision import transforms
from torchvision.datasets import ImageFolder
from torch.utils.data import Dataset, DataLoader
from torchvision.models import resnet50, ResNet50_Weights
import time
data_path = '/home/eapet/resnet_LoRA/m_data/train/'
base_path = '/home/eapet/resnet_LoRA/m_data/'
# Make torch deterministic
# 設定:每次訓練的W&B初始化都是一樣的
_ = torch.manual_seed(0)
#-------------------------------------
# 載入ResNet50預訓練模型
# Step 1: Initialize model with the best available weights
weights = ResNet50_Weights.IMAGENET1K_V1
resnet_model = resnet50(weights=weights)
# 遷移學習不需要梯度(不更改權重)
for param in resnet_model.parameters():
param.requires_grad = False
#-------------------------------
resnet_model.eval()
#------------------------------------------
# 準備Training data
# 把圖片轉換成Tensor
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor()
])
data_set = ImageFolder(data_path, transform=transform)
length = len(data_set)
print("\n")
print(length, "張圖片\n")
bz = 60
test_loader = DataLoader(data_set, batch_size=bz, shuffle=True)
#--------------------------------------
def process_lx(labels):
lx = labels.clone()
for i in range(bz):
if(labels[i]==0):
lx[i]=340
elif(labels[i]==1):
lx[i]=24
elif(labels[i]==2):
lx[i]=947
return lx
for idx, (images, la) in enumerate(test_loader):
break
labels = process_lx(la)
print(labels)
#-----------------------------------
def test():
correct = 0
total = 0
wrong_counts = [0 for i in range(3)]
with torch.no_grad():
for idx, (images, la) in enumerate(test_loader):
labels = process_lx(la)
prediction = resnet_model(images)
for idx, zv in enumerate(prediction):
if torch.argmax(zv) == labels[idx]:
correct +=1
else:
#print(idx)
wrong_counts[la[idx]] +=1
total +=1
#print(correct)
print('\n', f'Accuracy: {round(correct/total, 3)}')
for i in range(len(wrong_counts)):
print(f'wrong counts for the digit {i}: {wrong_counts[i]}')
#------------------------------------------
print('\n------ 原模型測試: ------')
test()
#==========================================
class Lora(nn.Module):
def __init__(self, m, n, rank=10):
super().__init__()
self.m = m
self.A = nn.Parameter(torch.randn(m, rank))
self.B = nn.Parameter(torch.zeros(rank, n))
def forward(self, inputs):
#print(inputs.shape)
#inputs = inputs.view(-1, self.m)
inputs = torch.reshape(inputs, [60,3*224*224])
#print(self.m)
return torch.mm(torch.mm(inputs, self.A), self.B)
lora = Lora(224 * 224 * 3, 1000)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(lora.parameters(), lr=1e-4)
#========================================================
print('\n------ 外掛LoRA模型,協同訓練: ------')
import intel_extension_for_pytorch as ipex
resnet_model = resnet_model.to(memory_format=torch.channels_last)
#lora = lora.to(memory_format=torch.channels_last)
loss_fn = loss_fn.to("xpu")
lora = lora.to("xpu")
lora, optimizer = ipex.optimize(lora, optimizer=optimizer, dtype=torch.bfloat16)
resnet_model = resnet_model.to("xpu")
resnet_model = ipex.optimize(resnet_model, dtype=torch.bfloat16)
base = 0
epochs = 100
begin = time.time()
for ep in range(epochs+1):
total_loss = 0
for idx, (images, la) in enumerate(test_loader):
labels = process_lx(la)
images = images.to("xpu")
labels = labels.to("xpu")
images =images.to(memory_format=torch.channels_last)
with torch.xpu.amp.autocast(enabled=True, dtype=torch.bfloat16):
pred = resnet_model(images) + lora(images)
loss = loss_fn(pred, labels)
loss.backward()
optimizer.step()
optimizer.zero_grad()
total_loss += loss.item() * bz
if((base+ep)%5 == 0):
loss_np = total_loss / 120
print('ep=', base+ep,'/',base+epochs, ', loss=', loss_np)
end = time.time()
print("TTT =", end-begin)
#------ Saved to *.CKPT ---------------------------
FILE = base_path + 'LORA_for_RESNET_ep50.ckpt'
torch.save(lora.state_dict(), FILE)
print('\nsaved to ' + FILE)
#-------------------------------------
def test22():
correct = 0
total = 0
wrong_counts = [0 for i in range(3)]
with torch.no_grad():
for idx, (images, la) in enumerate(test_loader):
labels = process_lx(la)
images = images.to("xpu")
labels = labels.to("xpu")
with torch.xpu.amp.autocast(enabled=True, dtype=torch.bfloat16):
prediction = resnet_model(images) + lora(images)
for idx, zv in enumerate(prediction):
if torch.argmax(zv) == labels[idx]:
correct +=1
else:
#print(idx)
wrong_counts[la[idx]] +=1
total +=1
#print(correct)
print('\n', f'Accuracy: {round(correct/total, 3)}')
for i in range(len(wrong_counts)):
print(f'wrong counts for the digit {i}: {wrong_counts[i]}')
#------------------------------------------
print('\n------ 原模型測試: ------')
test22()
#------------------------
#END
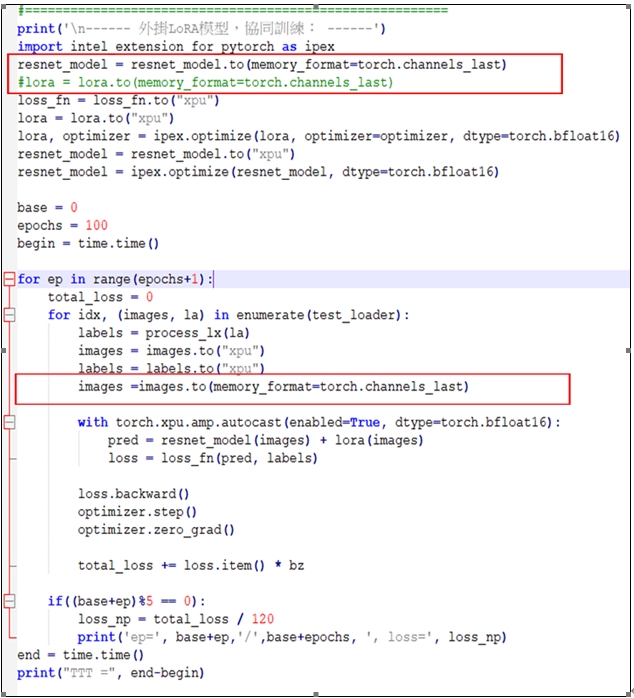
此範例使用Pytorch的指令:
resnet_model = resnet_model.to(memory_format=torch.channels_last)
其設定resnet_model模型採用CL(即NHWC)記憶體儲存格式。繼續使用指令:
images =images.to(memory_format=torch.channels_last)
with torch.xpu.amp.autocast(enabled=True, dtype=torch.bfloat16):
pred = resnet_model(images) + lora(images)
其把images圖像張量設定為CL儲存格式,然後把images輸入給lora和resnet_model模型。如下圖所示:
請仔細觀察這程式的執行情境:它使用<IPEX+GPU+BF16+CL>環境,並搭配Windows或Ubuntu作業系統來展開協同訓練。例如,在Ubuntu環境裡,使用命令(Command):
![]() 就展開訓練100回合,執行結果顯示如下圖:
就展開訓練100回合,執行結果顯示如下圖:
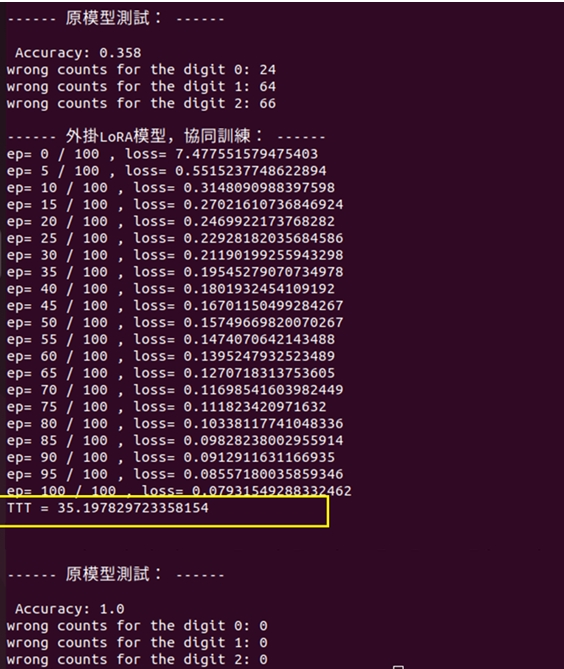
訓練環境是:IPEX + GPU + BF16 + CL
在本範例裡,採取<IPEX+GPU+BF16+CL>的軟硬體搭配的模式,針對相同的<ResNet50 + LoRa>模型,一樣進行訓練100回合,其訓練的耗時已經下降為35秒。這呈現出CL(即NHWC)儲存格式的最佳化效益了。
結語
我們以三篇文章記錄了透過深度學習模型的訓練,基於伺服器Intel CPU及GPU平台,比較四種不同的軟硬體組合,檢測AI模型訓練的性能優化效果。同時,也以實際程式碼來解說如何建構測試環境與訓練模型用的Python script編寫要點。
其中,用來作為評測的深度學習模型是基於預訓練Resnet50模型,而外掛LoRA模型來進行微調(Fine tuning)訓練,在訓練過程中即僅更新LoRA權重而不更新Resnet50的權重(亦即所載入的Resnet50模型的權重參數維持不變)。
測試時以四種組合來展開<Resnet50+LoRA>模型的微調訓練,所耗費的時間如下所列:
- 使用單純CPU:405秒。請參閱第一篇文章。
- 使用IPEX+GPU:235秒。請參閱第二篇文章。
- 使用IPEX+GPU+BF16:210秒。請參閱第三篇文章(即本文)。
- 使用IPEX+GPU+BF16+CL:35秒。請參閱第三篇文章(即本文)。
從測試結果可看出,使用GPU、低精度BF16、Channel Last(NHWC)後,將充分發揮效用,耗時縮減只需不到原來的 1/10 時間。

近5年來,從事於AI普及化教育工作,目前擔任銘傳大學AI課程、長庚智慧醫療研究所AI課程授課老師。也擔任永春國小、東園國小、立志中學、君毅中學、永春高中等學校的AI師資培育工作。
- LoRA微調三步驟:以大語言模型MT5為例 - 2024/05/02
- 為什麼Gemma採取Decoder-Only Transformer架構呢? - 2024/04/08
- 如何從0訓練企業自用Gemma模型 - 2024/04/03
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


