作者:高煥堂
本文摘自 高煥堂 的下列書籍,以及北京【電子世界雜誌】連載專欄

過去 IT 時代,電腦只能向人類的編程(作品)學習到「邏輯性智慧」。今天,像繪畫、音樂、文學作品等,人類逐漸知道了如何把豐富的直覺性智慧,讓 AI 學習領悟之。AI 從人類作品(如語句、小說詩篇等)學習捕捉創作者的「非邏輯性智慧」。進而依據人們對話語句(或文本)的意圖(Attention),重組非邏輯性智慧,以及邏輯性智慧。
人類天生都有一項能力,就是:人人皆有的觀察周遭世界的「非邏輯化」技能。這種憑藉「直覺」來獲取對事物或現象的整體觀,長久以來都被IT人士所忽略,因為傳統 IT 只關注事物或現象裡的「邏輯化」部分。凡事都要把它邏輯化,才能寫成電腦程式語言。
AI 的特長就是使用更接近人類的「非邏輯化」方式去識別周遭的事物,包括人類看不到的(也因而無法邏輯化的)的複雜現象,例如新冠肺炎與腸道菌生態變化之關係等。AI 技術雖然是來自 IT(猴子),但已經愈來越像人類,而不再只是進化版的猴子(猩猩)而已。也由於 AI 能使用更接近人類的「非邏輯化」方式去認識周遭的事物,包括人類看不到的(也因而無法邏輯化的)的複雜現象。所以 AI 從莎士比亞文學作品中,可以學習到人類所看不到的藝術創作(如非邏輯化部分)成分。
簡而言之,AI 很擅長於學習人類專家的直覺性智慧(即專家直覺),也就是非邏輯性智慧。愈是資深的行業專家,其直覺性智慧愈豐富,表現於「瞬間洞察」的能力愈強。例如,ChatGPT 驚動全人類,就是它從人類各種文字、圖像等作品學習其非邏輯性智慧,也直接吸納人類的專家直覺智慧,最後與人類專家(含非專家)對談來捕捉人類使用者的心意(Attention),來進一步強化其「貼心」能力。
從作品中學習專家創作
AI 生成(如AIGC),就是 AI 學會設計出自己的作品。
茲舉一個例子,俗語說:巧媳婦做不來沒米的飯。有一天 AI 來到廚房了,它想學習做飯,做出自己喜歡的飯。此時,請您試想一個問題:AI 從哪裡學習到智慧呢?有人回答:從大數據中學習。那我們繼續想更深入的問題:大數據是資料,到底是關於「米」的資料,還是關於「巧媳婦」的資料,還是關於「飯」的資料呢?
假設這只是一般家庭的廚房,沒有任何食譜。只有鍋爐、水、米、飯和巧媳婦而已。這樣思考,您就能輕易掌握「AI 生成」的真諦了。在 AIGC 潮流下,合理的答案是:關於「飯」的資料。因為「飯」是專家(如巧媳婦)的作品,而AI就從專家作品(的大數據)中學習創作的經驗直覺。
AI 裡的眾多模型之中,GAN 是箇中高手,最擅長從人類的藝術作品中學習到藝術家的風格等。
GAN 模型的學習模式
典型的 GAN 模型裡,包含了兩個小模型:判別器與生成器。
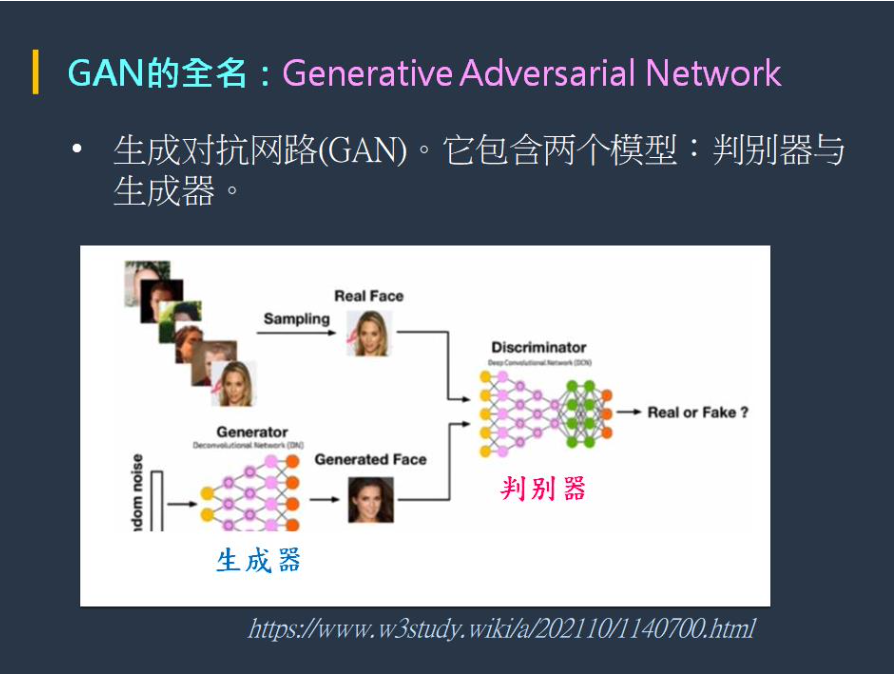
其中,判別器如同「老師」,而生成器則如同「學生」。
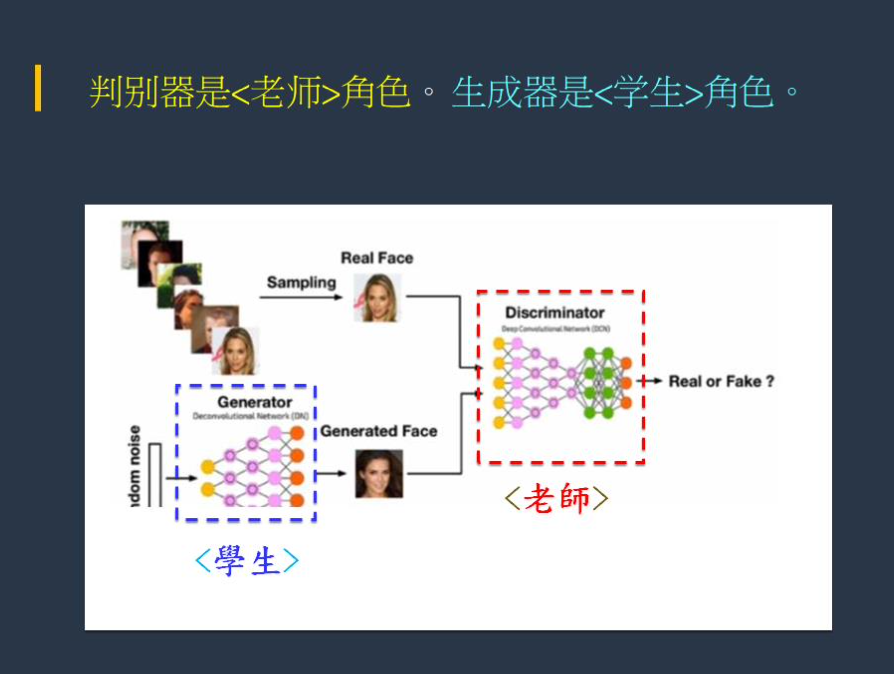
自從 2014年生成對抗網路(GAN)問世以來,在 AI (機器學習)領域裡,已經出現了許多關於該技術有深度的、創造性的貢獻。GAN 就是模擬這種過程的神經網路架構(Neural Networks)。
例如,在繪畫藝術領域裡,GAN 就像電腦生成藝術的畫筆。用 GAN 進行創作特別令人振奮。GAN 總是給人一種驚喜的感覺,它可以創作出更特別的效果。

在本文裡,就來詳細解說GAN的另一個重要角色:生成器(Generator)。兩個角色互相較量智慧,教學相長、共同成長。
GAN的學習模式:教學相長
學生和老師,兩者都是從零開始,共同成長。

雖然老師不會畫,但它會拿學生作品來與龍貓漫畫書來做特徵對比。

如果學生作品沒有龍貓漫畫的重要特徵,就會感覺畫得不像。

於是,AI機器學生開始作畫了。

老師發現了學生作品裡沒有龍貓漫畫的重要特徵:鬍鬚。

老師就要求學生加以改善。

老師又發現學生作品裡少了龍貓漫畫的另一項特徵:娃娃哭時嘴巴張很大。

老師就要求學生加以改進。

兩者互相較量,又協同創新、教學相長。
然後,持續不斷地改進下去,就會止於至善。在 AI(人工智慧)領域裡,像上述的協同創作機制,特別稱為生成對抗網路(Generative Adversarial Network,簡稱GAN)。學生(創作者)的角色,稱為生成器(Generator),而老師(鑒賞者)的角色稱為判別器(Discriminator)。
例如下圖裡,左圖是鑒賞者所握有的原圖,而右圖則是創作者所生成的創作品。經由 GAN 的協同創新,所生成的作品已經幾可亂真了。

小結
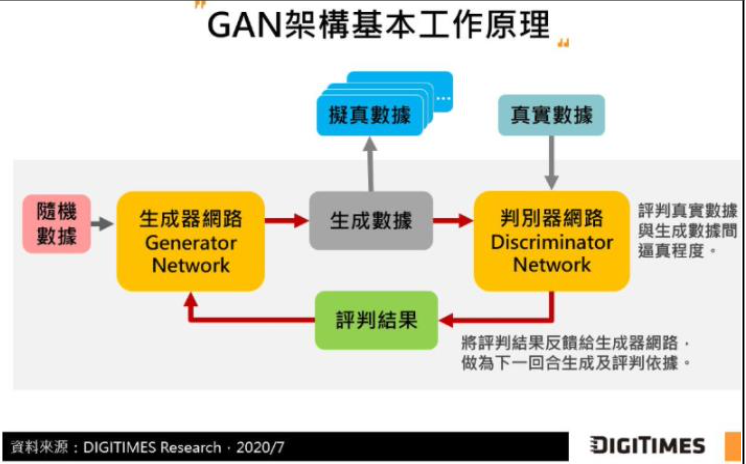
GAN 是一種能夠生成新數據的神經網絡。你可以輸入一點隨機噪音作為輸入,它可以生成馬匹、飛機、鳥類或其他經過訓練生成的逼真圖像。
GAN 網路模型,是由生成器和判別器兩部分組成,以非監督式機器學習的方式運行。在 GAN 的訓練過程中,生成網絡 G 的目標是儘量生成很逼真的圖片去欺騙判別網絡 D,而 D 的目標是儘量把生成的圖片和真實的圖片區分開來。看穿 G 的騙局。這樣地,由 G 和 D 兩種角色,來構成了一個動態平衡的博弈棋局,就是 GAN 的基本思維。
我們以交替的步驟來訓練這兩個網絡,並將它們鎖定在激烈的競爭中以提高自己的技能和判斷力。最終,鑑別器識別出真實作品與生成作品之間的差異,生成器則創建圖像,企圖讓鑑別器無法辨別真假。
這種 GAN 模型最後會收斂並生成自然外觀逼真的圖像。我們使用真實圖像和生成圖像來進行交替訓練,由 GAN 的鑑別器來了解哪些特徵使圖像變得更逼真。然後鑑別器會向生成器提供反饋,讓生成器的智慧提升,以創建看起來像真正的莫奈畫作的逼真畫作(假品)。
(責任編輯:謝嘉洵)

近5年來,從事於AI普及化教育工作,目前擔任銘傳大學AI課程、長庚智慧醫療研究所AI課程授課老師。也擔任永春國小、東園國小、立志中學、君毅中學、永春高中等學校的AI師資培育工作。
- LoRA微調三步驟:以大語言模型MT5為例 - 2024/05/02
- 為什麼Gemma採取Decoder-Only Transformer架構呢? - 2024/04/08
- 如何從0訓練企業自用Gemma模型 - 2024/04/03
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


