作者:Jack Hsu
去(2021)年10月Edge Impulse推出EON Tuner AutoML工具時還沒有認真研究,最近花了一點時間把先前的介紹影片看完並簡單摘要了一下,覺得這項工具對不懂AI的MCU工程師有很大的幫助,相對於手動設定瞎猜調整參數來說,簡單、快速地解決了模型選用及優化工具,想更了解這項工具到底有什麼用途的朋友可參考一下這段影片「AI Tech Talk from Edge Impulse: EON Tuner: AutoML for real-world embedded devices」:
以下為影片重點摘要:
嵌入式設備(Embedded System Device)的需求在過去幾年中快速成長,預計到2021底將有1800億台嵌入式設備投入市場,若能使內嵌機器學習(Embedded Machine Learning)變得更普及,這便是未來的使命。
真實世界中充滿大量資訊來源方便人們進行辨識,包括聲音、影像及各種感測器信號。但在很多情況下是無法把這麼大量的資訊送回雲端進行計算,若能於裝置中內嵌機器學習,將會帶來更便捷的生活,但不幸地是極少量的計算資源,如CPU速度(功耗)、程式碼區(Flash)及記憶體(SRAM),讓這項工作變得極具挑戰性。
傳統程式開發是採輸入加上法則(rules)而得到結果。隨著機器學習算法的演進,開始轉變成輸入加上輸出結果進而找出關係和法則,以運動感測器獲取輸入信號為例,原始信號是參雜了非常多的高頻雜訊,所以先經過一些低通濾波器(Low Pass Filter)來令輸入信號變得較為乾淨(平滑),對於後續機器學習算法(信號分類或辨識)會有很大的幫助。

機器學習演算法改變了傳統程式開發法則(Source)
利用數位信號處理(Digital Signal Processing, DSP)後,可得到較少(乾淨)的特徵,同時亦可使後續辨識所需的模型隨之變小。
以聲音片段辨識為例,通常會有三個工作階段,輸入信號處理、語音特徵提取、建立模型及推論,而最後一個階段通常是大家花最多時間的地方,包括調整參數、改變模型結構、反覆驗證等。
為得到更好的辨識結果,這裡會採用更大範圍的參數處理,包括改變聲音輸入信號取樣的視窗大小(長度)、分割位置(移動步階)及降低取樣頻率等。而在特徵提取上提供不同類型的頻率域處理方式,包括梅爾頻率倒譜系數(Mel-Frequency Cepstral Coefficients, MFCC)、梅爾濾波器組能量(Mel-filter bank energy, MFE)、頻譜分析(Spectrogram)等,讓不同類型的聲音特徵能得到更好的強化。
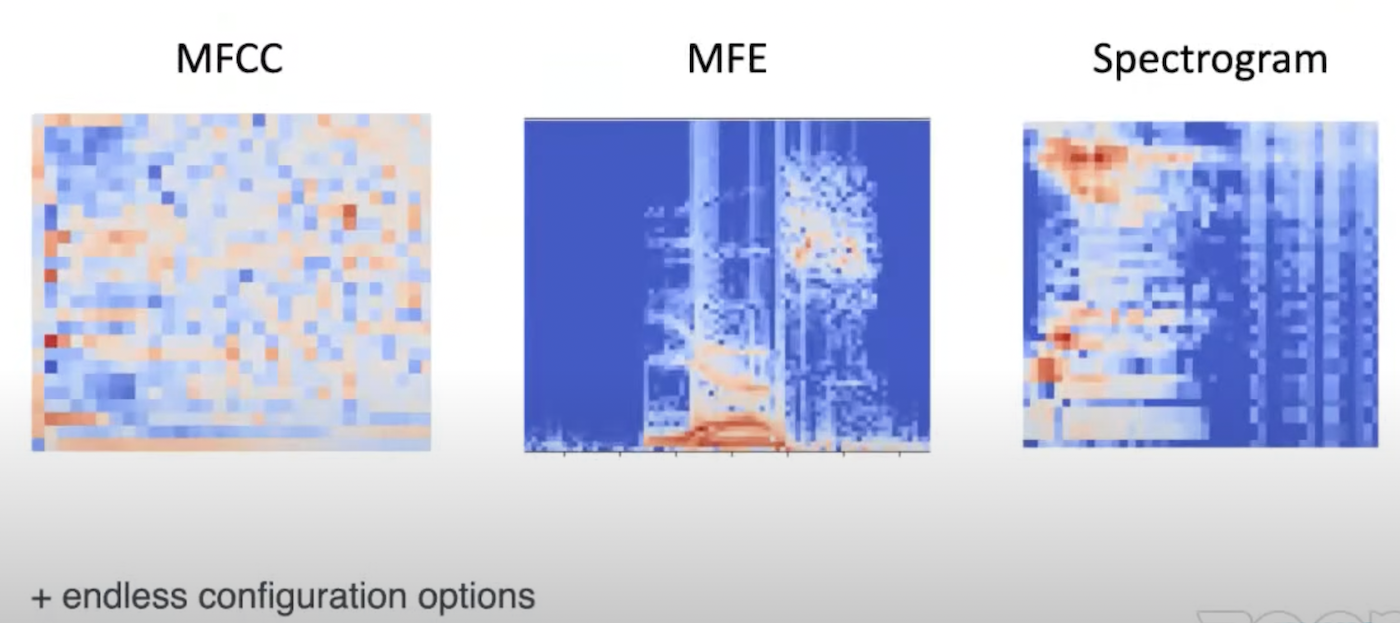
在特徵提取上提供不同類型的頻率域處理方式(Source)
除以上參數內容,還有更多的參數可供調整,當透過不同配置調整,可使模型得到不一樣的辨識精度、資源使用大小(Flash, SRAM使用量)及計算複雜度(推論時間)。
實際案例
接下來就以實際案例進行展示,並說明EON Tuner(AutoML Tools)是如何幫助大家快速建立可靠的模型。
假設在你的花園中錄了很多不同種類小鳥叫聲、背景雜音等,經處理後分段成為大量的學習及測試樣本(Training / Testing Sets)。再來設定好使用何種數位信號處理方式(如MFCC, MFE, Spectrogram)。接著就能指定EON Tuner的參數了,其中包括資料集來源、目標執行裝置(CPU種類及時脈速度)、預期推理時間等,方便後續自動調整(優化)模型網路結構(Model Architechrue)。尤其是指定預期推理時間,根據不同應用須強制推論時間以免造成實務應用問題,如無人機就需很快的反應時間(要犧牲一些推論精度)以免撞機,而分別鳥叫聲則無急迫性。完成設定後,按下執行(Start EON Tuner)就能開始分析及優化模型。
在執行EON Tuner期間,我們可以透過一些可視化圖表來觀察不同參數在模型各層的執行結果及性能。不過這個過程很長,以目前案例來說約要半小時,其它案例則會視資料集大小、原始模型(網路結構)複雜度、特徵提取方式(數位信號處理類型)及各種參數會有不同的優化時間。完成後,可依可視化圖表分析結果,選擇最優(或最適合)的模型行更新。此時再回頭檢查原先手動設定(Impulse Design)的項目都已被修正了。最後將結果佈署到指定硬體(開發板)就完成了。

EOL Tuner提供可視化圖表(Source)
在可視化圖表上會呈現數位信號處理(DSP)及神經網路(NN)在推論時間、SRAM及Flash的使用比例,同時會顯示推論精度、混淆矩陣,亦會列出不同信號處理方式所佔用的資源。由於同時會產生很多組結果,因此也支援依不同內容(如精度、推論速度、記憶體、程式碼、推論精度等)進行排序,方便選擇理想模型。
當然透過這些圖表上的數據也可間接得知自己選用的硬體(開發板)是否規格不足或超出太多,方便我們考慮是要以硬體成本還是推論效能優先。反之,若選用硬體還有餘力,但推論精度不足,則可考慮替換較大的模型來進行改善。
小結
EON Tuner這項工具相對於憑經驗手動逐一調整設定參數來說,可更輕鬆並快速找出多種合適且優化的模型,方便我們快速迭代及驗證想法。這項工具未來將採API模式,方便使用者能更彈性的應用及開發對應程式。對於搜尋部份的算法將會開源,使開發者更容易根據硬體或特殊使用情境進行改善。未來將加入更多感測器的支援,更優化搜尋法則,同時在多個模型上迭代工作,並將此作為一種時間線來掌握發展的脈絡。
問答時間
Q1:目前可支援多少種模型,是否可加入自己開發的模型?
目前可支援1D和2D的卷積神經網路,並可指定層數、神經元個數,對於大部份小型應用已足夠,目前因應視覺應用也在開發一個較大及較小版本的Mobilenet。
Q2:硬體加速器如何和ENO發揮作用?
這個問題會基於兩個方面,目前根據Edge Impulse可支援硬體清單已做了基本加速處理(包含硬體加速及模型優化加速推論),另外若要引入目前清單外的硬體則可透過EON API來協助分析,即可得知硬體加速器之性能。
Q3:如何更進一步了解EON的原理,以便了多是基於何種原因進行調整?
這部份未來會開源,目前有應用到貝葉斯(Bayes)和超頻帶(Hyperband)還有一些隨機(Random)搜索,並持續改善搜尋算法中。
Q4:未來會支援感測器融合(Sensor Fusion)嗎?
當然,這已在產品開發清單上,未來會透過API方式來完成這項需求。
以上僅是個人簡單看完影片後的快速摘要,並不是原文完整直接翻譯,如有理解錯誤之處還請見諒,若對以上內容有其它看法的朋友,歡迎留言進行討論。
(本文經歐尼克斯實境互動工作室同意後轉載,原文連結。)
延伸閱讀

主持歐尼克斯實境互動工作室(OmniXRI):http://omnixri.blogspot.com
Edge AI Taiwan邊緣智能交流區:https://www.facebook.com/groups/edgeaitw/
- Arduino UNO Q教學案例整理 - 2026/03/09
- 有了Intel AI Playground 不寫程式也能輕鬆玩生成式AI - 2025/09/02
- 【開發資源】TinyML MCU 等級開源推論引擎 - 2025/06/09
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


