作者:曾成訓(CH.Tseng)
有時我們的物件識別專案僅需要針對數種或單一種物件進行辨識,像是抓取道路中的汽車以便進行後續車牌或車型的辨識、取得影像中的犬貓以進行品種分類、框選影格中的人體,識別其關節特徵點來預測其動作等。
目前一些大型開源的深度學習圖庫如 Pascal VOC 及 COCO 等,皆提供種類繁多的物品標記圖片,其所訓練出的模型可辨識數十至上百種物品,因此我們可以利用這些開源圖庫來訓練辨識各種物件;但若我們只需要辨識貓與狗,卻需要辨識及過濾其它不相干的物品,不覺得太麻煩了嗎?是否能把該特定物品從這些開源圖庫取出,再加入其它或自己所搜集的圖片,單獨製作出專屬於該物品的 image dataset 呢?
Pascal VOC Dataset
Pascal VOC dataset 是由 PASCAL 組織所開源的影像圖庫,該組織全名相當冗長,為 Pattern Analysis, Statistical Modelling and Computational Learning Visual Object Classes,簡寫為 PASCAL,成立於 2003 年 12 月 1 日,是一個由歐盟所資助的研究機構。
PASCAL 的 VOC dataset 提供了物件識別模型最主要的兩種功能驗證:classification(分類)及detection(偵測),自 2005 年起每年舉辦一系列基於該 dataset 的 computer vision competition,識別範圍從基本的 Object Classification、Object Detection、Object Segmentation 到後來的 Human Layout、Action Classification,直到 2012 年的最後一屆為止,在此頁面還可看到歷屆的榜單。
VOC提供的物件類別
VOC dataset 的影像主要來自 flickr 與 Microsoft Research Cambridge(MSRC),包含 20 種不同的物件,區分為下列四種類別:
- Vehicles:Car、Bus、Bicycle、Motorbike、Boat、Train
- Household:Chair、Sofa、Dining table、TV/monitor、Bottle、Potted plant
- Animals:Cat、Dog、Cow、Horse、Sheep、Bird
- Person:Person
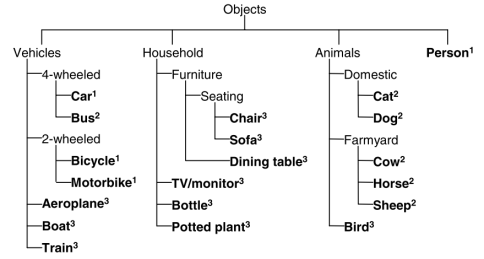
後方數字代表該類別加入的年份:1 為 2005、2 為 2006、3 為 2007(圖片來源:The PASCAL Visual Object Classes Challenge)
下方圖表統計不同物件所屬的圖片數目及標記數量,可以看到 Person 這個類別數量最多,其次為 Car。

不同物件所屬的圖片數目(圖片來源:The PASCAL Visual Object Classes Challenge)

不同物件所屬的標記數量(圖片來源:The PASCAL Visual Object Classes Challenge)
擷取感興趣的物件class
1. 請下載 VOC 2012 dataset(2 GB)
下載後的資料夾結構如下:
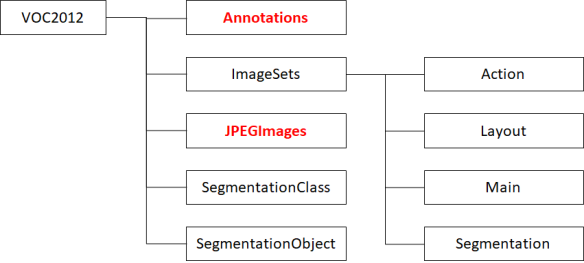
由於要使用於 Object detection,因此我們需要的是 Annotations 及 JPEGImages 這兩個資料夾,你會發現這兩個資料夾分別有 22,263 及 33,260 個檔案。
2. 下載 xml_file.txt 及 xml_object.txt 到工作目錄下
3. 參考下方的 pascalVOC_to_voc.py,修改一些參數:
pascalVOC_to_voc.py
# -*- coding: utf-8 -*-
import cv2
from shutil import copyfile
import os, time
import os.path
from xml.dom import minidom
#-------------------------------------------
labels_want = ["dog"]
pose = ["rear", "left", "right", "frontal"] #use lower case, []--> all, ["rear", "left", "right", "frontal", "unspecified"]
source_voc_path = "/DATA1/Datasets_download/Labeled/VOC/VOC_Dataset/2012/VOCdevkit/VOC2012/"
source_images = "JPEGImages"
source_labels = "Annotations"
target_voc_path = "/DATA1/Datasets_mine/labeled/dog_voc"
target_images = "images/"
target_labels = "labels/"
imgType = "jpg"
xml_file = "xml_file.txt"
object_xml_file = "xml_object.txt"
def chkEnv():
if not os.path.exists(os.path.join(source_voc_path, source_images)):
print("There is no source dataset in this path:", os.path.join(source_voc_path, source_images))
quit()
if not os.path.exists(os.path.join(source_voc_path, source_labels)):
print("There is no source dataset in this path:", os.path.join(source_voc_path, source_labels))
quit()
if not os.path.exists(os.path.join(target_voc_path, target_images)):
os.makedirs(os.path.join(target_voc_path, target_images))
print("Create the path:", os.path.join(target_voc_path, target_images))
if not os.path.exists(os.path.join(target_voc_path, target_labels)):
os.makedirs(os.path.join(target_voc_path, target_labels))
print("Create the path:", os.path.join(target_voc_path, target_labels))
def getLabels(imgFile, xmlFile):
labelXML = minidom.parse(xmlFile)
labelName = []
labelXmin = []
labelYmin = []
labelXmax = []
labelYmax = []
totalW = 0
totalH = 0
countLabels = 0
#print(xmlFile)
objects = labelXML.getElementsByTagName("object")
for object in objects:
pose_list = []
tmpArrays = object.getElementsByTagName("pose")
for id, elem in enumerate(tmpArrays):
pose_list.append(elem.firstChild.data)
id_list = []
tmpArrays = object.getElementsByTagName("name")
for id, elem in enumerate(tmpArrays):
if(str(elem.firstChild.data) in labels_want):
id_list.append(id)
#print(xmlFile, id, pose_list, "TEST:", pose_list[id].lower())
if(len(pose_list)>id):
if((pose_list[id].lower() in pose) and len(pose)>0):
labelName.append(str(elem.firstChild.data) + "_" + pose_list[id])
else:
labelName.append(str(elem.firstChild.data))
tmpArrays = object.getElementsByTagName("xmin")
for id, elem in enumerate(tmpArrays):
if(id in id_list):
labelXmin.append(int(float(elem.firstChild.data)))
tmpArrays = object.getElementsByTagName("ymin")
for id, elem in enumerate(tmpArrays):
if(id in id_list):
labelYmin.append(int(float(elem.firstChild.data)))
tmpArrays = object.getElementsByTagName("xmax")
for id, elem in enumerate(tmpArrays):
if(id in id_list):
labelXmax.append(int(float(elem.firstChild.data)))
tmpArrays = object.getElementsByTagName("ymax")
for id, elem in enumerate(tmpArrays):
if(id in id_list):
labelYmax.append(int(float(elem.firstChild.data)))
return labelName, labelXmin, labelYmin, labelXmax, labelYmax
def writeObjects(label, bbox):
with open(object_xml_file) as file:
file_content = file.read()
file_updated = file_content.replace("{NAME}", label)
file_updated = file_updated.replace("{XMIN}", str(bbox[0]))
file_updated = file_updated.replace("{YMIN}", str(bbox[1]))
file_updated = file_updated.replace("{XMAX}", str(bbox[0] + bbox[2]))
file_updated = file_updated.replace("{YMAX}", str(bbox[1] + bbox[3]))
return file_updated
def generateXML(imgfile, filename, fullpath, bboxes, imgfilename):
xmlObject = ""
for (labelName, bbox) in bboxes:
#for bbox in bbox_array:
xmlObject = xmlObject + writeObjects(labelName, bbox)
with open(xml_file) as file:
xmlfile = file.read()
img = cv2.imread(imgfile)
#print(os.path.join(datasetPath, imgPath, imgfilename))
cv2.imwrite(os.path.join(target_voc_path, target_images, imgfilename), img)
(h, w, ch) = img.shape
xmlfile = xmlfile.replace( "{WIDTH}", str(w) )
xmlfile = xmlfile.replace( "{HEIGHT}", str(h) )
xmlfile = xmlfile.replace( "{FILENAME}", filename )
xmlfile = xmlfile.replace( "{PATH}", fullpath + filename )
xmlfile = xmlfile.replace( "{OBJECTS}", xmlObject )
return xmlfile
def makeLabelFile(filename, bboxes, imgfile):
jpgFilename = filename + "." + imgType
xmlFilename = filename + ".xml"
#cv2.imwrite(os.path.join(datasetPath, imgPath, jpgFilename), img)
xmlContent = generateXML(imgfile, xmlFilename, os.path.join(target_voc_path, target_labels, xmlFilename), bboxes, jpgFilename)
file = open(os.path.join(target_voc_path, target_labels, xmlFilename), "w")
file.write(xmlContent)
file.close
#--------------------------------------------
if __name__ == "__main__":
chkEnv()
i = 0
imageFolder = os.path.join(source_voc_path, source_images)
for file in os.listdir(imageFolder):
filename, file_extension = os.path.splitext(file)
file_extension = file_extension.lower()
if(file_extension == ".jpg" or file_extension==".jpeg" or file_extension==".png" or file_extension==".bmp"):
#print("Processing: ", imageFolder + "/" + file)
xml_path = os.path.join(source_voc_path, source_labels, filename+".xml")
if os.path.exists(xml_path):
image_path = os.path.join(imageFolder, file)
labelName, labelXmin, labelYmin, labelXmax, labelYmax = getLabels(image_path, xml_path)
img_bboxes = []
print(labelName, labelXmin, labelYmin, labelXmax, labelYmax)
for i, label_want in enumerate(labelName):
x = int(float(labelXmin[i]))
y = int(float(labelYmin[i]))
w = int(float(labelXmax[i]))-int(float(labelXmin[i]))
h = int(float(labelYmax[i]))-int(float(labelYmin[i]))
img_bboxes.append( (label_want, [x,y,w,h]) )
if(len(img_bboxes)>0):
print(img_bboxes)
makeLabelFile(filename, img_bboxes, image_path)#想要取出的標記名稱,可多個。
labels_want = [“dog”, “cat”]
#例:”Labeled/VOC/VOC_Dataset/2007/VOCdevkit/VOC2007″
source_voc_path = “{VOC2012的path}”
#image圖檔的目錄名稱,例:JPEGImages
source_images = “{圖片檔path}”
#image標記檔的目錄名稱,例:Annotations
source_labels = “{標記檔path}”
#新建的dataset路徑,例:voc_coco_cars/
target_voc_path = “{新建dataset path}”
#新建dataset的圖檔目錄名稱,例:images/
target_images = “{圖檔目錄名稱}”
#新建dataset的標記檔目錄名稱,例:labels/
target_labels = “{標記檔目錄名稱}”
4. 執行 python pascalVOC_to_voc.py
下方我們以指定取出類別為「person」作為例子,在 pascalVOC_to_voc.py 程式執行結束後,便可見到所有類別為 person 的圖片及標記檔,皆已被取出並放置於指定的位置。
(圖片來源:曾成訓提供)
(圖片來源:曾成訓提供)
接著使用 LabelImg 工具檢視,確認每張圖片的標記皆有正確地被擷取,因此透過本程式,我們從 VOC dataset 取得了所有標記為 Person 的 image 及標記檔,數量有 14,721 張。
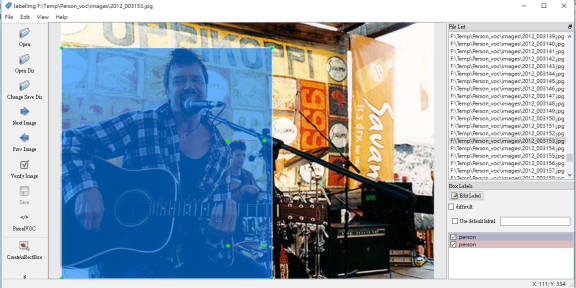
(圖片來源:曾成訓提供)

(圖片來源:曾成訓提供)
Pascal VOC Dataset 總共提供了 20 種類別的物件,除了範例的 Person,其它類別用如上的方式也能取得,只要修改 labels_want 參數的內容即可。
取得人體的部位標記
VOC 2011 起增加了所謂的「person layout」,也就是在標記檔中新增 head、hand、foot 三種人體標記(或稱 2-D Pose Annotation),透過 head、hand、foot 的位置,我們便能識別該人物目前的動作姿態。
這三種人體 annotation 位於標記檔的 part tag 底下,下方為圖檔 2011_000943.jpg,右側為透過其標記檔 2011_000943.xml 中的局部內容 ,可發現 tag 定義了 head、hand、foot 的位置區域。

2011_000943.jpg(圖片來源:曾成訓提供)
<part> <name>head</name> <bndbox> <xmin>153</xmin> <ymin>161</ymin> <xmax>192</xmax> <ymax>214</ymax> </bndbox> </part> <part> <name>hand</name> <bndbox> <xmin>79</xmin> <ymin>247</ymin> <xmax>102</xmax> <ymax>271</ymax> </bndbox> </part> <part> <name>hand</name> <bndbox> <xmin>230</xmin> <ymin>305</ymin> <xmax>264</xmax> <ymax>329</ymax> </bndbox> </part> <part> <name>foot</name> <bndbox> <xmin>195</xmin> <ymin>412</ymin> <xmax>221</xmax> <ymax>440</ymax> </bndbox> </part> <part> <name>foot</name> <bndbox> <xmin>89</xmin> <ymin>392</ymin> <xmax>126</xmax> <ymax>402</ymax> </bndbox> </part>
若要取得 VOC dataset 中的人體標記,請執行下方的 pascalVOC_to_peopleParts.py,所有的 2-D Pose Annotation 便會匯出在指定的路徑中。
pascalVOC_to_peopleParts.py
# -*- coding: utf-8 -*-
import cv2
from shutil import copyfile
import os, time
import os.path
from xml.dom import minidom
#-------------------------------------------
parts_want = ["head", "hand", "foot"]
source_voc_path = "/DATA1/Datasets_download/Labeled/VOC/VOC_Dataset/2012/VOCdevkit/VOC2012/"
source_images = "JPEGImages"
source_labels = "Annotations"
target_voc_path = "/DATA1/Datasets_mine/labeled/voc_people_parts"
target_images = "images/"
target_labels = "labels/"
imgType = "jpg"
xml_file = "xml_file.txt"
object_xml_file = "xml_object.txt"
def chkEnv():
if not os.path.exists(os.path.join(source_voc_path, source_images)):
print("There is no source dataset in this path:", os.path.join(source_voc_path, source_images))
quit()
if not os.path.exists(os.path.join(source_voc_path, source_labels)):
print("There is no source dataset in this path:", os.path.join(source_voc_path, source_labels))
quit()
if not os.path.exists(os.path.join(target_voc_path, target_images)):
os.makedirs(os.path.join(target_voc_path, target_images))
print("Create the path:", os.path.join(target_voc_path, target_images))
if not os.path.exists(os.path.join(target_voc_path, target_labels)):
os.makedirs(os.path.join(target_voc_path, target_labels))
print("Create the path:", os.path.join(target_voc_path, target_labels))
def getLabels(imgFile, xmlFile):
labelXML = minidom.parse(xmlFile)
labelName = []
labelXmin = []
labelYmin = []
labelXmax = []
labelYmax = []
totalW = 0
totalH = 0
countLabels = 0
#print(xmlFile)
objects = labelXML.getElementsByTagName("part")
for object in objects:
id_list = []
tmpArrays = object.getElementsByTagName("name")
for id, elem in enumerate(tmpArrays):
if(str(elem.firstChild.data) in parts_want):
labelName.append(str(elem.firstChild.data))
id_list.append(id)
tmpArrays = object.getElementsByTagName("xmin")
for id, elem in enumerate(tmpArrays):
if(id in id_list):
labelXmin.append(int(float(elem.firstChild.data)))
tmpArrays = object.getElementsByTagName("ymin")
for id, elem in enumerate(tmpArrays):
if(id in id_list):
labelYmin.append(int(float(elem.firstChild.data)))
tmpArrays = object.getElementsByTagName("xmax")
for id, elem in enumerate(tmpArrays):
if(id in id_list):
labelXmax.append(int(float(elem.firstChild.data)))
tmpArrays = object.getElementsByTagName("ymax")
for id, elem in enumerate(tmpArrays):
if(id in id_list):
labelYmax.append(int(float(elem.firstChild.data)))
return labelName, labelXmin, labelYmin, labelXmax, labelYmax
def writeObjects(label, bbox):
with open(object_xml_file) as file:
file_content = file.read()
file_updated = file_content.replace("{NAME}", label)
file_updated = file_updated.replace("{XMIN}", str(bbox[0]))
file_updated = file_updated.replace("{YMIN}", str(bbox[1]))
file_updated = file_updated.replace("{XMAX}", str(bbox[0] + bbox[2]))
file_updated = file_updated.replace("{YMAX}", str(bbox[1] + bbox[3]))
return file_updated
def generateXML(imgfile, filename, fullpath, bboxes, imgfilename):
xmlObject = ""
for (labelName, bbox) in bboxes:
#for bbox in bbox_array:
xmlObject = xmlObject + writeObjects(labelName, bbox)
with open(xml_file) as file:
xmlfile = file.read()
img = cv2.imread(imgfile)
#print(os.path.join(datasetPath, imgPath, imgfilename))
cv2.imwrite(os.path.join(target_voc_path, target_images, imgfilename), img)
(h, w, ch) = img.shape
xmlfile = xmlfile.replace( "{WIDTH}", str(w) )
xmlfile = xmlfile.replace( "{HEIGHT}", str(h) )
xmlfile = xmlfile.replace( "{FILENAME}", filename )
xmlfile = xmlfile.replace( "{PATH}", fullpath + filename )
xmlfile = xmlfile.replace( "{OBJECTS}", xmlObject )
return xmlfile
def makeLabelFile(filename, bboxes, imgfile):
jpgFilename = filename + "." + imgType
xmlFilename = filename + ".xml"
#cv2.imwrite(os.path.join(datasetPath, imgPath, jpgFilename), img)
xmlContent = generateXML(imgfile, xmlFilename, os.path.join(target_voc_path, target_labels, xmlFilename), bboxes, jpgFilename)
file = open(os.path.join(target_voc_path, target_labels, xmlFilename), "w")
file.write(xmlContent)
file.close
#--------------------------------------------
if __name__ == "__main__":
chkEnv()
i = 0
imageFolder = os.path.join(source_voc_path, source_images)
for file in os.listdir(imageFolder):
filename, file_extension = os.path.splitext(file)
file_extension = file_extension.lower()
if(file_extension == ".jpg" or file_extension==".jpeg" or file_extension==".png" or file_extension==".bmp"):
#print("Processing: ", imageFolder + "/" + file)
xml_path = os.path.join(source_voc_path, source_labels, filename+".xml")
if os.path.exists(xml_path):
image_path = os.path.join(imageFolder, file)
labelName, labelXmin, labelYmin, labelXmax, labelYmax = getLabels(image_path, xml_path)
img_bboxes = []
for i, label_want in enumerate(labelName):
x = int(float(labelXmin[i]))
y = int(float(labelYmin[i]))
w = int(float(labelXmax[i]))-int(float(labelXmin[i]))
h = int(float(labelYmax[i]))-int(float(labelYmin[i]))
img_bboxes.append( (label_want, [x,y,w,h]) )
if(len(img_bboxes)>0):
print(img_bboxes)
makeLabelFile(filename, img_bboxes, image_path)執行後,總共擷取了 664 張圖片及標記檔,再次使用 labelImg 工具驗證,會發現每張圖片中的人物都標記了三種人體部位,但若圖片中有很多人,VOC 並沒有每個人物皆標記,如下圖,最右側的人可能由於部份身體被遮住,因此略過不予標記。
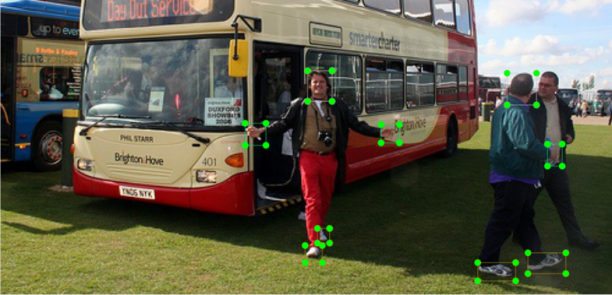
(圖片來源:曾成訓提供)
但又有些圖片中的人物很適合標記卻也省略沒標,因此人物是否需要標記身體部位看來是隨機的,如下圖:

(圖片來源:曾成訓提供)
透過取得 head、hand、foot 三種身體標記,我們可以識別影像中的人物動作,例如舉手、站立、躺或坐、搖擺或倒立等,不過可惜的一點,就是 VOC 並不是針對圖片中所有的人物進行人體部位標記,除非我們自己將圖片中未標記的部份補足,否則這仍然屬於未完成標記的 dataset,無法直接進行訓練。
取得pose標記
在 VOC dataset 中,有的 Object 標記會有 pose 這個 tag(有的沒有),它有五種值:Rear、Left、Right、Frontal、Unspecified,代表了該物體正面的方向,例如下方這張圖片中的四個人,有三個朝向右方,一個朝向左方(以第一人稱觀點),因此在這張圖片的標記檔中,會有 pose 這個 tag 來定義這四個值。

(圖片來源:曾成訓提供)
一樣使用上方 pascalVOC_to_voc.py 的程式,注意一下其中的參數 pose,把想要抓取的 pose 填入即可(若 pose=[] 空值則代表全部抓取),VOC 共定義了 rear、left、right、frontal、unspecified 等五種 pose 值。
透過 pose 標記,我們便能訓練識別物品的方向或方位。下面我們執行程式抓取所有為 dog 標記的圖檔,並設定 pose = [“rear”, “left”, “right”, “frontal”],則會取得 835 張圖片及標記檔,例如下圖有兩個 labels,其 class 名稱在擷取後取名為 dog_Frontal。

(圖片來源:曾成訓提供)
下面這張的兩個 label 分別為 dog_Right 以及 dog_Left。

(圖片來源:曾成訓提供)
此外,交通工具的識別也能搭配方向資訊作出各種應用。只要設定擷取 car、bus、motorbike 這三種標記,並定義 pose = [“rear”, “left”, “right”, “frontal”]、補足未標記的部份,就能擁有一個可用以訓練辨識交通工具及其行進方向的 dataset 了:

(圖片來源:曾成訓提供)

(圖片來源:曾成訓提供)
(本文經作者同意轉載自 CH.TSENG 部落格、原文連結;責任編輯:賴佩萱)

- 【模型訓練】訓練馬賽克消除器 - 2020/04/27
- 【AI模型訓練】真假分不清!訓練假臉產生器 - 2020/04/13
- 【AI防疫DIY】臉部辨識+口罩偵測+紅外線測溫 - 2020/03/23
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


