作者:陸向陽
眾所皆知,人在關注細節時會改變頭的方位角度而後定睛仔細觀察,例如在野外看到一隻蜜蜂飛過去,隨後停留在自身偏左下方的位置開始採花蜜,這時人就會把頭轉向左邊往下看,而後專注看,以便掌握蜜蜂活動的細節。
同理,目前一般的視訊監控除了在定點配置攝影機外有時也會配置一種PTZ攝影機,所謂PTZ是指平移(Pan)、俯仰(Tilt)與變焦(Zoom),P與T模擬人的頸部動作,Z則模擬人眼焦距變化以便近看與遠看。
人如此、視訊監控如此,但有意思的是,今日多數的AI電腦視覺應用的是定點影像感測,即在一處放置一部攝影機,靜靜且無差別地收集攝影機視界內所感測的影像,從而實現各種AI智慧判定,如影像中有幾輛車經過?車牌號碼為多少?
這其實有點不合理,為了更精準的智慧判斷,AI電腦視覺也應該跟人跟視訊監控一樣,是可以改變觀察方位角度與遠近的,為此上海交通大學以Qwen2.5-VL 7B為基礎延伸發展,開發出可用於機器人眼球智慧操作的AI模型,稱為EyeVLM。
VLM基礎認知
要說明EyeVLM前,先簡單解釋何謂VLM視覺語言模型,過去ChatGPT剛上線提供服務時,只能用文字詢問而後獲得文字回覆,之後可以同時饋入兩種以上的表達以獲得回覆,例如上傳一段聲音檔並用文字詢問:該聲音檔內可有鳥叫聲?這時ChatGPT是同時參看聲音與詢問句,而後才給出「有」或「無」的智慧判定回覆,凡是有兩種以上的表達饋入就稱為多模態(Multimodal),此為AI模型朝通用人工智慧路線發展上的一種技術摸索嘗試。
而VLM視覺語言模型即是種多模態模型,只要饋入視覺資料(Vision)與問句(Language)而後就能獲得智慧判定答案,例如給出一張圖片問其中有幾隻貓?是否有黃貓等?現在已諸多VLM可用,如LLaVA、InternVL3等,有些則是從LLM大語言模型衍生練就成的,如Llama3.2-vision、Granite3.2-vision等,而EyeVLM用的Qwen2.5-VL 7B正是以通義千問2.5版的LLM模型衍生而成的VLM,參數量70億。
EyeVLM獨到技術之處
上海交大運用該模型Qwen2.5-VL 7B然後搭配一個PTZ攝影機(嚴格而論,鏡頭不只左右平移,其實是可以完全旋轉平移)來實現EyeVLM,上海交大對Qwen2.5-VL 7B模型進行強化學習的再訓練,讓它對人們下達的命令與所感測到的場景有更高的智慧感知,而且EyeVLM會預測出所謂的action token,這些token指令傳達到攝影機就會驅動其改變鏡頭的左右、俯仰、遠近。
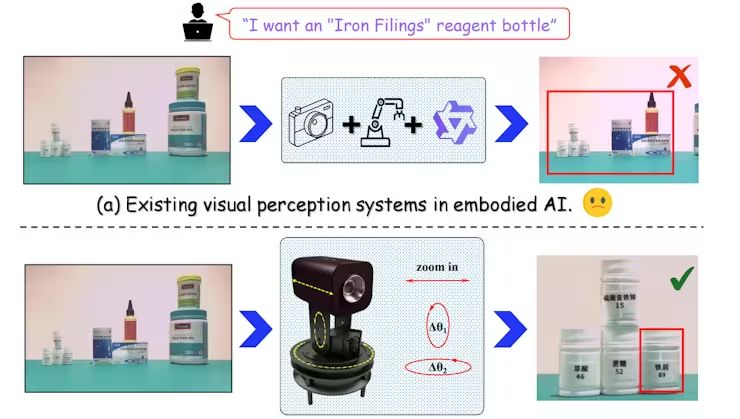
圖1:EyeVLM示意,先用文字詢問試劑罐在哪?攝影機鏡頭會改變視角去尋找、識別出試劑罐(圖片來源:上海交大J. Yang等人)
為了達到這個機理效果,EyeVLM研究團隊把二維邊界框資訊(2D bounding-box information, bbox)整合到Qwen2.5-VL 7B模型的推論鏈(reasoning chain)中,這樣EyeVLM可以識別出潛在值得進一步關注的影像區域,而將鏡頭的方位、遠近往該區域調整,以便捕捉到更仔細的影像細節,有了更多細節,影像的AI智慧判定也會更準確。
而這裡頭也用到階層式token編碼機制,並且把複雜的攝影機動作壓縮成少量的token,這樣使EyeVLM可以在硬體效能有限、硬體資源有限下也能有效率地運作。
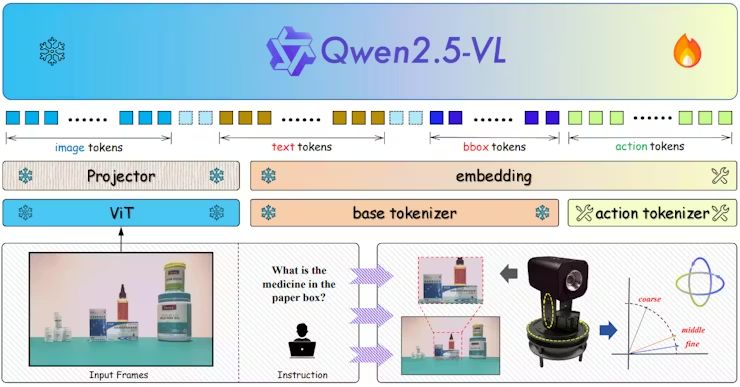
圖2:EyeVLM運作流程圖,過程中用及影像、文字、bbox等多種類型的token,並產生action token(圖片來源:上海交大J. Yang等人)
EyeVLM模型訓練完成後也實際與完全靜態鏡頭(稱為RGB-D,單純三原色感測外加深度)進行AI智慧判定能力的比較,EyeVLM的效果確實更好。更有意思的是,EyeVLM的模型訓練只用了500張左右的真實世界樣本,這主要是因為用了強化學習與偽資料標記擴展(pseudo-labeled data expansions)等技術。
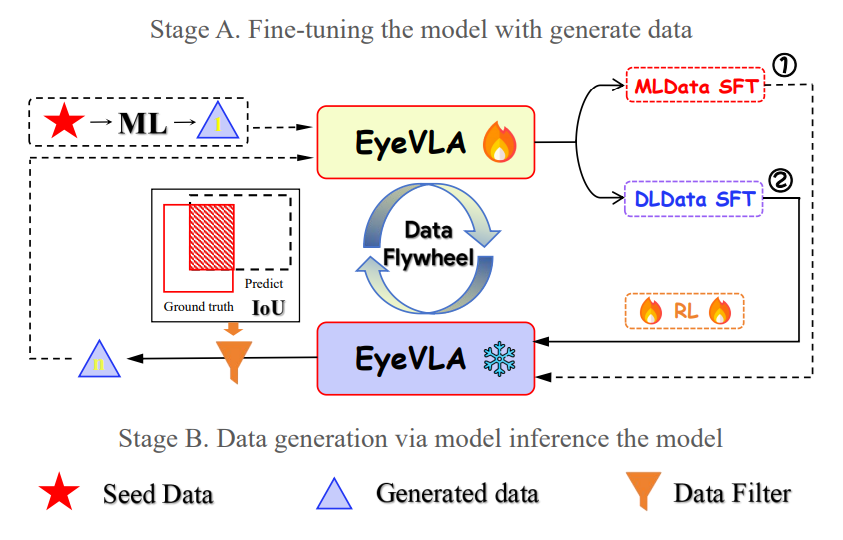
圖3:EyeVLA模型在訓練後的微調(fine-tune)階段用及資料產生器,而資料的產生是透過模型推論模型,稱為資料飛輪(Flywheel)(圖片來源:上海交大J. Yang等人)
未來應用設想
最後,EyeVLM最終目標還是要應用落地的,目前的應用設想是裝配在各種實體移動機器人上,成為其眼球,然後用於基礎設施的巡檢、倉庫自動化管理、家用機器人或環境監測等工作。
有了具智慧性的眼球,搭配上現在業界積極倡議的實體人工智慧(Physical AI)技術,看來人們離追求智慧化的人形機器人又邁出了一大步。
延伸閱讀:

- 月之暗面Kimi K3模型技術觀察 - 2026/07/29
- 推探OpenAI Codex Micro專屬控制器 - 2026/07/27
- 「公升級」Agentic AI方案比較:Apple、NVIDIA、AMD - 2026/06/29
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


