作者:Yamini Nimmagadda、Daniil Lyakhov、Mustafa Cavus、Surya Siddharth Pemmaraju與Aamir Nazir,Intel
對於PyTorch生態系的開發者而言,技術焦點正逐漸轉向邊緣端部署。隨著AI模型變得更加複雜,如何在各種裝置上——從入門等級硬體到強大的AI PC——有效率地進行部署,成為一項關鍵挑戰。在PyTorch生態系中,ExecuTorch 提供了這樣的基礎,它是一種可攜、高效能的裝置端推論Runtime (可參考ExecuTorch 1.0了解更多)。
這衍生了一個重要的問題:我們該如何彌補標準化的PyTorch匯出模型與現代裝置中多樣且異質硬體之間的差距?對於以Intel Core Ultra(第二代)架構驅動的最新一代AI PC而言,這個問題比以往更加關鍵。這些機器是專為本地AI運算任務打造,由單一晶片中緊密整合的多個專屬運算單元所定義──包括用於即時、低延遲反應的高效能CPU,負責艱鉅平行運算任務的高處理量整合式GPU,以及最重要的、專為持續性節能推論任務設計之強大神經處理單元(NPU)。
由於每種處理器是針對不同效能指標——延遲性、處理量與每瓦效能──最佳化,對開發者而言,基礎挑戰是:如何讓單一PyTorch模型智慧地運用整套專屬硬體,既不使得開發工作流程破碎化,也不脫離PyTorch生態系?
在這篇深度解析技術文章,我們將探討ExecuTorch的OpenVINO後端——這是一種專為簡化異質運算複雜度而設計的解決方案——檢視它是如何直接整合到PyTorch 2.x的開發流程中,實現整個最佳化流水線的自動化,讓單一模型能智慧地運用CPU、GPU與NPU的專有功能,達到近乎原生的效能表現。
解決方案的基礎:ExecuTorch和OpenVINO
為了解決裝置端部署的挑戰,PyTorch生態系提供了ExecuTorch——一個新世代、可攜且高效能的推論Runtime系統;它以「預先編譯」(Ahead-of-Time,AOT)原則為基礎,將模型轉換為輕量、自包含(self-contained)的.pte二進位格式,將Runtime的額外開銷(overhead)降至最低,並且與現代的torch.export工作流程完全相容。ExecuTorch雖內建了一套預設的 CPU核心函式庫以確保廣泛可攜性,但是實現高效能硬體加速的主要機制,是可擴充的後端系統,能夠將運算任務交給專屬後端執行。
英特爾(Intel)的OpenVINO (全名為:Open Visual Inference & Neural Network Optimization)正能彌補這樣的落差,該工具套件專為最佳化英特爾硬體AI效能所設計,是ExecuTorch的理想後端,能讓開發人員充分發揮英特爾硬體潛能。它提供了一整套的模型最佳化工具,包括硬體感知量化,以及一個強大的異質Runtime系統。這個Runtime是關鍵所在,它抽象化了底層晶片的複雜性,透過單一API就可以在CPU、GPU和 NPU 上使用經過最佳化的核心(kernels)來執行模型。
「我們正在讓PyTorch社群能更輕鬆地於AI PC時代構建應用,」英特爾客戶端和Edge AI框架副總裁Adam Burns表示:「透過將OpenVINO整合至ExecuTorch,開發者無需離開PyTorch工作流程,就能充分發揮英特爾CPU、GPU和NPU的全部潛能。」
旅程的起點:從nn.Module到Export IR (EXIR)
這段旅程從標準的PyTorch 2工作流程開始,我們首先建立一個典型的torch.nn.Module,然後使用torch.export來擷取模型的圖形化表示。這個過程由TorchDynamo驅動,它會追蹤模型的前向傳播(forward pass)過程,並生成一個 ExportedProgram,其中包含以ATen方言(PyTorch 的標準運算子集合)表示的清晰、圖形化模型結構。
這個 FX計算圖是我們的真實資料來源,一種靜態、可攜的模型表述,隨時可以進行最佳化。
OpenVINO 後端:技術詳解
OpenVINO後端並非簡單的後端,是一套整合式的編譯工具鏈,運作於EXIR圖上;它包含一個預先編譯(AOT)階段,用以產生最終可部署成果,另一個是負責執行模型的Runtime元件。
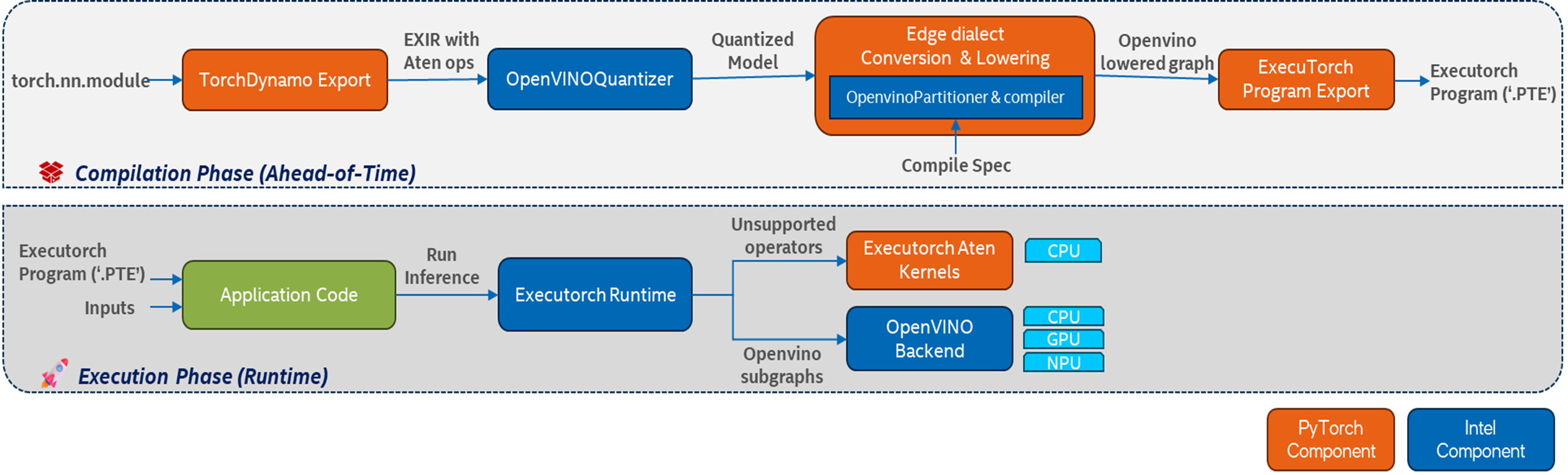
第一階段:AOT預先編譯
此初始階段是一個至關重要的離線預處理步驟,在此階段,標準的PyTorch模型將轉換為高效、可部署且針對英特爾硬體最佳化的工件(artifact)。在AOT階段,模型會經歷一連串複雜的分析和轉換。這個過程充分利用OpenVINO工具套件的強大功能,透過應用硬體感知最佳化和智慧地劃分計算圖(computational graph),使模型達到最佳效能。這種方法確保繁重的編譯和最佳化工作僅須在部署前執行一次,產生已準備好快速、高效執行的可攜資產。
步驟1:後端感知量化
流程的第一階段是透過 OpenVINOQuantizer 進行最佳化,該工具由神經網路壓縮框架(NNCF)驅動。此導出後處理步驟應用後端感知量化,將模型轉換為較低精度,以獲得最佳效能。 OpenVINOQuantizer 支援兩種不同的後端感知壓縮路徑,以針對目標硬體最佳化模型:訓練後量化(PTQ)和權重壓縮(WC)。
第一種方式是完整的訓練後量化,目標是最大化推論加速。在INT8_SYM或 INT8_MIXED等模式下,此流程會同時量化權重與激活值(activation),利用校準資料集分析整個模型中的張量(tensor)動態範圍,並計算最佳縮放係數,以在將FP32轉換為INT8時將精度損失降到最低。這種整體性的量化方式可大幅提升效能,因為可利用現代CPU上的Intel AMX、VNNI 等低精度硬體指令,以及NPU上的原生整數運算單元。
第二種方式是專注於「僅權重」(Weights-Only,WO)的壓縮模式,為因應大型模型──特別是大型語言模型(LLMs)──龐大的記憶體需求而設計。這種方法適用於INT8或更激進的INT4精度,且屬於無資料(data-free)方式,只壓縮模型的權重張量,而激活值仍維持浮點精度。這能大幅降低模型大小,是在裝置端部署生成式AI的關鍵需求。為了在如此低的精度仍維持模型品質,這裡使用NNCF的compress_pt2e API,讓使用者能結合AWQ、尺度估計(scale estimation)、分組縮放(group-wise scaling)以及混合精度壓縮等複雜的技術。
關鍵在於這兩種方式基本上都是「後端感知」,NNCF透過與OpenVINO後端的整合,能理解目標硬體(CPU、GPU或NPU)的哪些運算子(operators)能以低精度加速。它會自動產生最佳的混合精度模型,確保只有在能帶來效能提升的情況下才執行量化。這能避免傳統通用量化流程的弊端,最終得到一個以最高程度針對AI PC能力最佳化的模型。
步驟2:圖形劃分與降階(Graph Partitioning and Lowering)
這一步是後端智慧的核心,OpenvinoPartitioner 會逐一遍歷EXIR圖中的節點,識別OpenVINO Runtime支援的運算子最大連續子圖(contiguous subgraphs)。
最終會生成一個混合圖(hybrid graph),用於加速的子圖會被「降階」,也就是從PyTorch的 ATen運算子轉換為序列化的OpenVINO模型(ov::Model),並編譯成特定硬體的blob格式。這些降階後的子圖會在主圖中以單一、不透明的自訂運算子call_delegate取代。至於後端不支援的運算子則維持不變,仍為標準ATen運算子。
步驟3:序列化為.pte檔案
最後,整個混合圖——包括主圖的ExecuTorch位元碼、被委派降階子圖的OpenVINO模型blob,以及所有模型權重——會被打包成自包含的單一.pte檔案,這個可攜式資產就是在部署時會需要的全部。
第二階段:Runtime異質執行
在Runtime,ExecuTorch的Runtime會載入.pte檔案並作為主協調器(orchestrator)。
- 它會逐一執行圖形運算子。
- 遇到標準ATen運算子時,它會將其交給自身高效、可攜的CPU核心執行。
- 遇到call_delegate運算子時,則會呼叫OpenVINO後端。
- 後端會接收預先編譯的OpenVINO模型blob及輸入張量,使用OpenVINO Runtime在使用者指定的硬體上執行這段子圖——可能是CPU、整合或獨立GPU,或是NPU。
這種「混合執行」模式是一大關鍵優勢,確保整個PyTorch模型都能執行,並為後端不支援的運算子提供可靠的CPU後備路徑,可省略為了讓模型完全相容後端而進行人工手動修改的繁瑣過程。
將理論付諸實踐
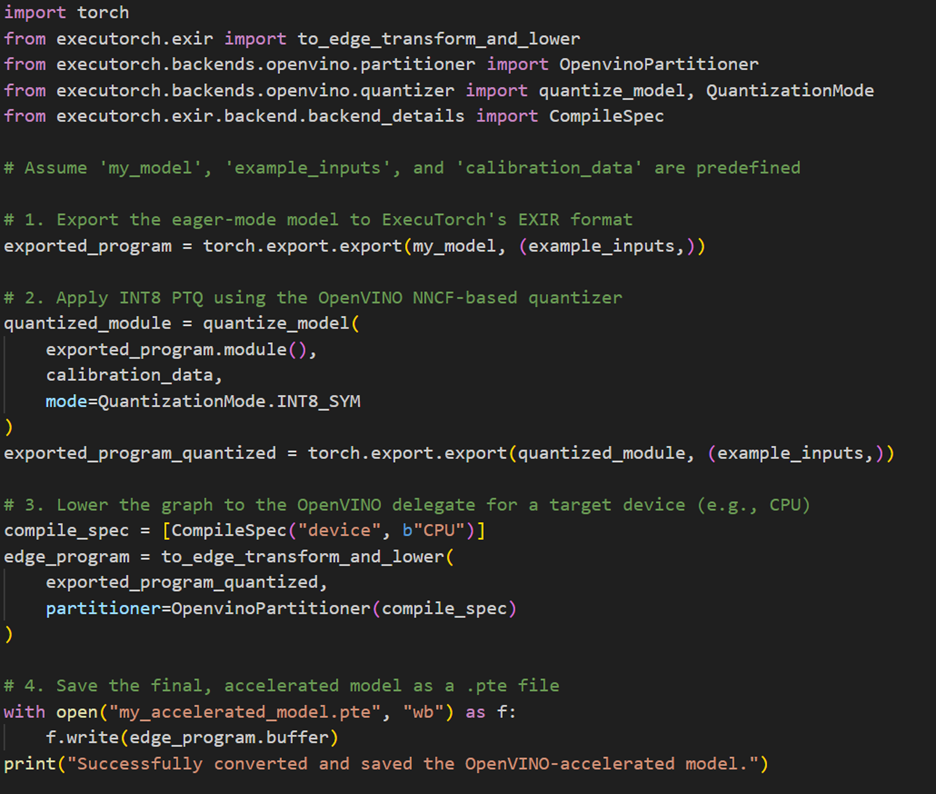
現在,讓我們把前面討論過的概念轉換為實際驅動整個工作流程的核心API呼叫。整個過程是一條程式化的多階段流水線,會透過串接以下的關鍵函式,將一個標準的torch.nn.Module轉換為高度最佳化的ExecuTorch程式(.pte檔案):
- 圖形擷取:此流程一開始是使用標準torch.export函式,取得以ATen方言表示的初始EXIR圖。
- 最佳化與量化:接著將匯出的圖形傳遞給quantize_model函式,它會利用 OpenVINOQuantizer和NNCF的進階PTQ演算法來執行後端感知量化。
- 圖形降階:最佳化之後的圖形隨後與OpenvinoPartitioner一起傳遞給 to_edge_transform_and_lower函式;這是關鍵步驟,會在此此識別要委派給OpenVINO Runtime的子圖。
- 完工:最後,降階後的圖形會轉換為.pte工件,是一個自包含、可部署的二進位檔案,隨時可以執行。
以下的程式碼片段截圖展示了如何將這些階段串接起來,以創建最終的硬體加速成果:
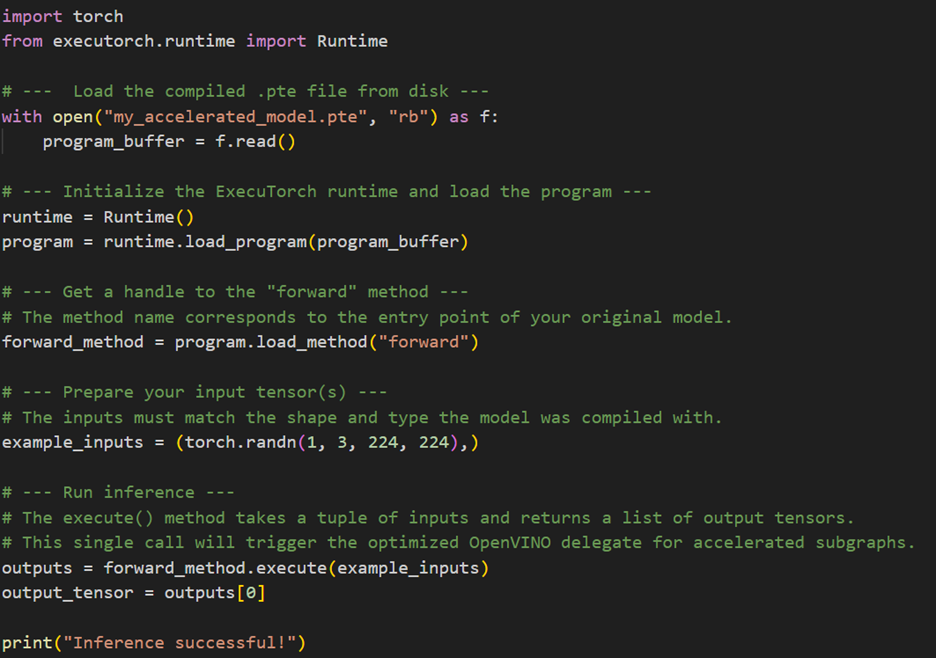
完成預編譯(AOT)後,會獲得一個可攜的.pte檔案,下一步就是使用ExecuTorch Runtime載入並執行此程式;這個Runtime被設計為輕量化、高效率,非常適合裝置端的應用。
範例腳本中的infer_model函式提供了一個實用的範本,示範了流程中的關鍵步驟:初始化 executorch.runtime. Runtime、從二進位緩衝區(buffer)載入程式、掌控主要的前向方法,然後透過輸入張量執行該方法。它也包含標準性能測試實踐步驟,例如在測試延遲前先進行預熱迭代,以確保快取被充分啟動、效能穩定。
以下程式碼片段截圖將此過程濃縮為必要的API呼叫,展示如何在你自己的應用中整合.pte模型進行推論:
實際應用案例
由Intel Core Ultra等異質運算平台驅動的AI PC問世,標誌著個人運算領域的基礎性變革,PC不再只是仰賴單一種處理器完成所有任務,而是整合於單晶片的一整套專用處理器,包括強大的CPU、高處理量的整合式繪圖處理器(iGPU),以及高效率的NPU。這種架構讓開發者在最適當的硬體上執行AI工作負載,也就是被稱為「異質執行」的概念。以下提供幾個應用案例,來展示ExecuTorch如何針對不同的專用處理器,將各類裝置端AI應用的效能與效率提升到新層次。
案例1:以YOLOv12進行即時物件偵測
物件偵測是推動裝置端AI普及最受歡迎、最具影響力的任務之一,無論是自動化倉儲盤點管理,或是智慧城市中的即時交通分析,這類模型正在轉變各式各樣的真實世界應用。YOLO系列模型一向以快速、精準度與可靠性著稱,使其成為下一代客戶端硬體部署的理想選擇,得益於ExecuTorch最佳化,最新版本的YOLOv12能以最小化Runtime與最佳效能在裝置端運作。建議的INT8量化方法能在幾乎不影響偵測品質的條件下,大幅降低部署模型的記憶體與能源消耗量。下方的GIF圖片展示YOLOv12在Intel Core Ultra (第二代)處理器上的物件偵測即時運作情況,突顯該平台CPU的卓越效能。

這個展示可以在Executorch範例中取得,使用OpenVINO後端。
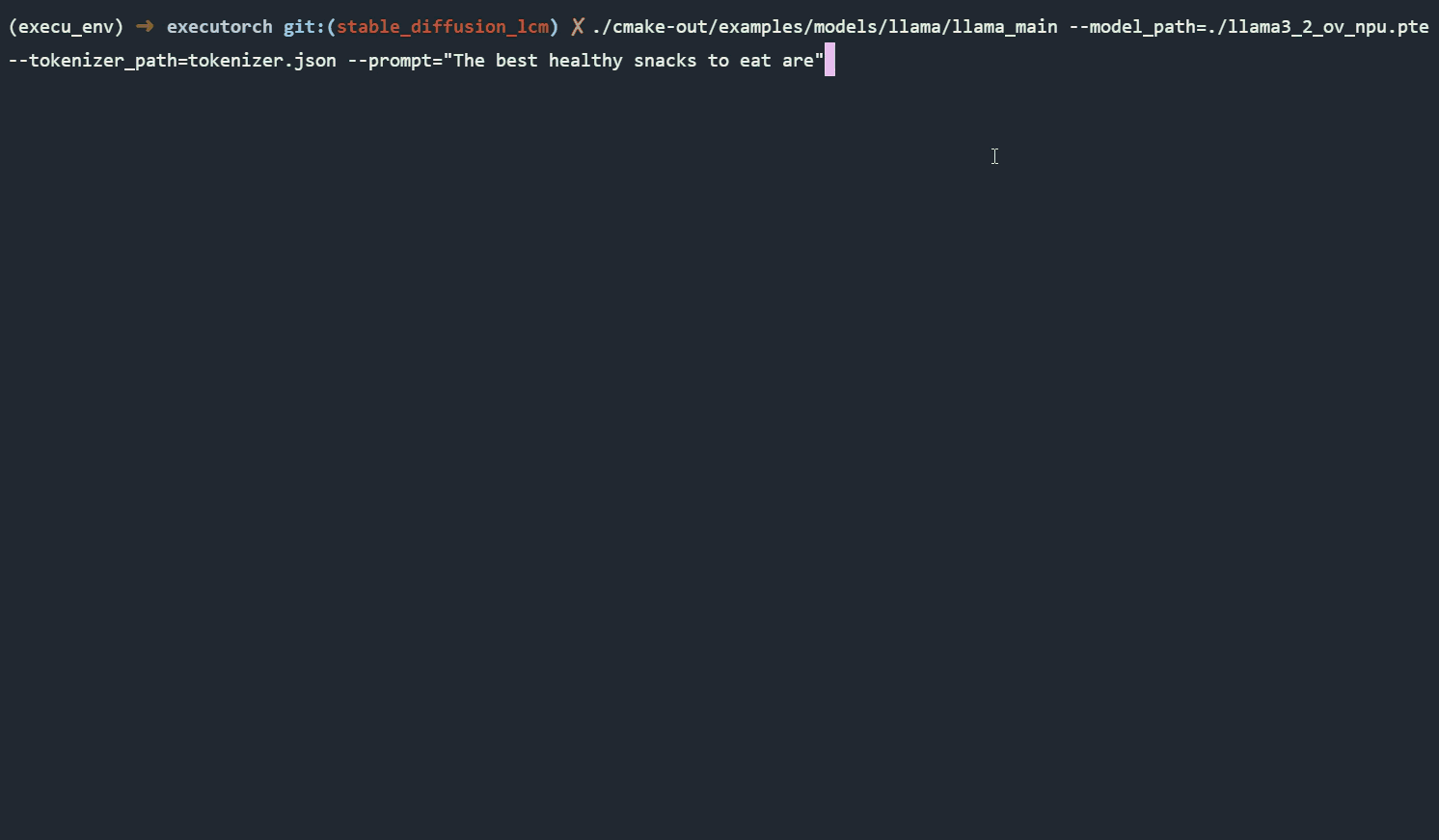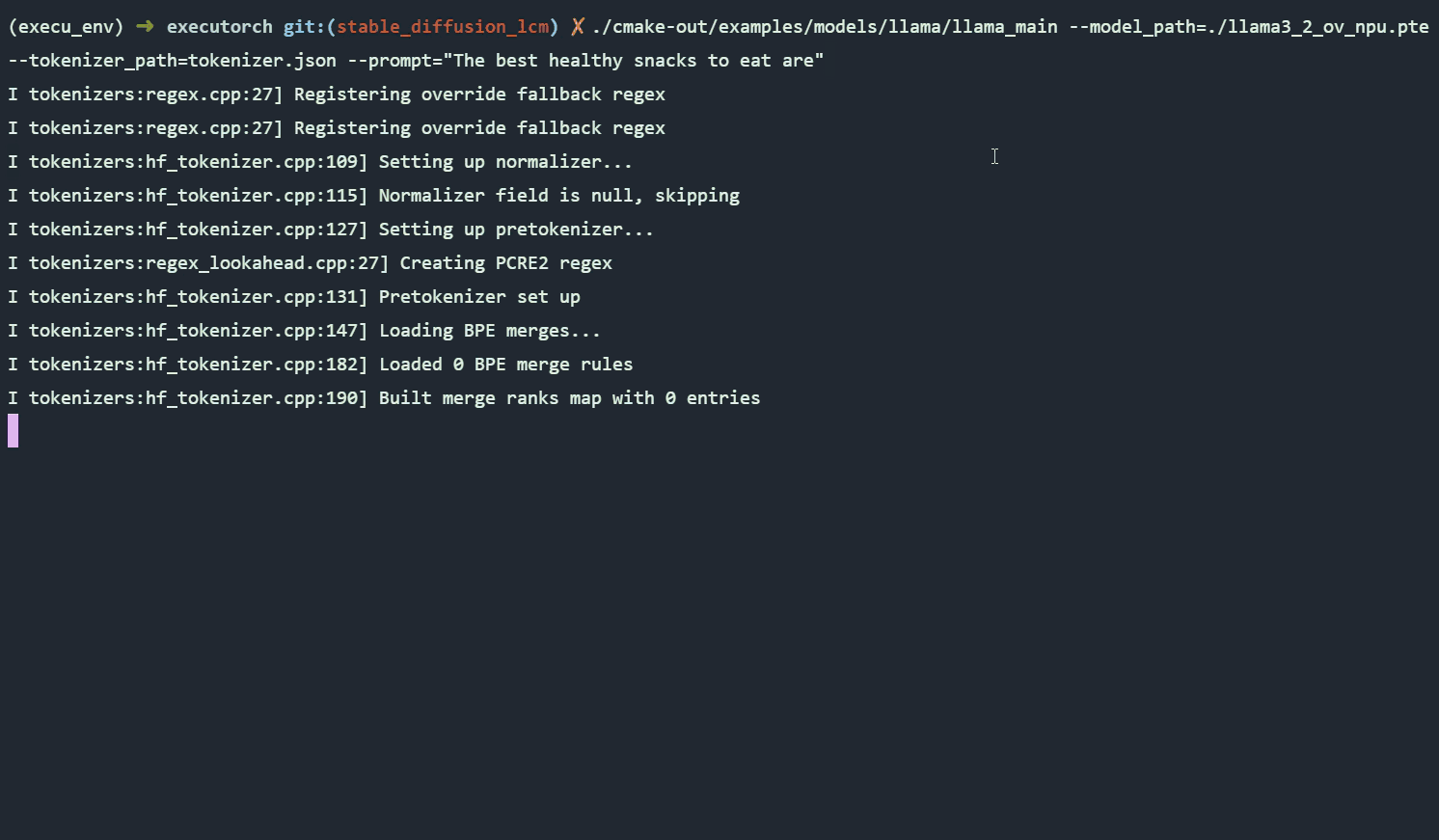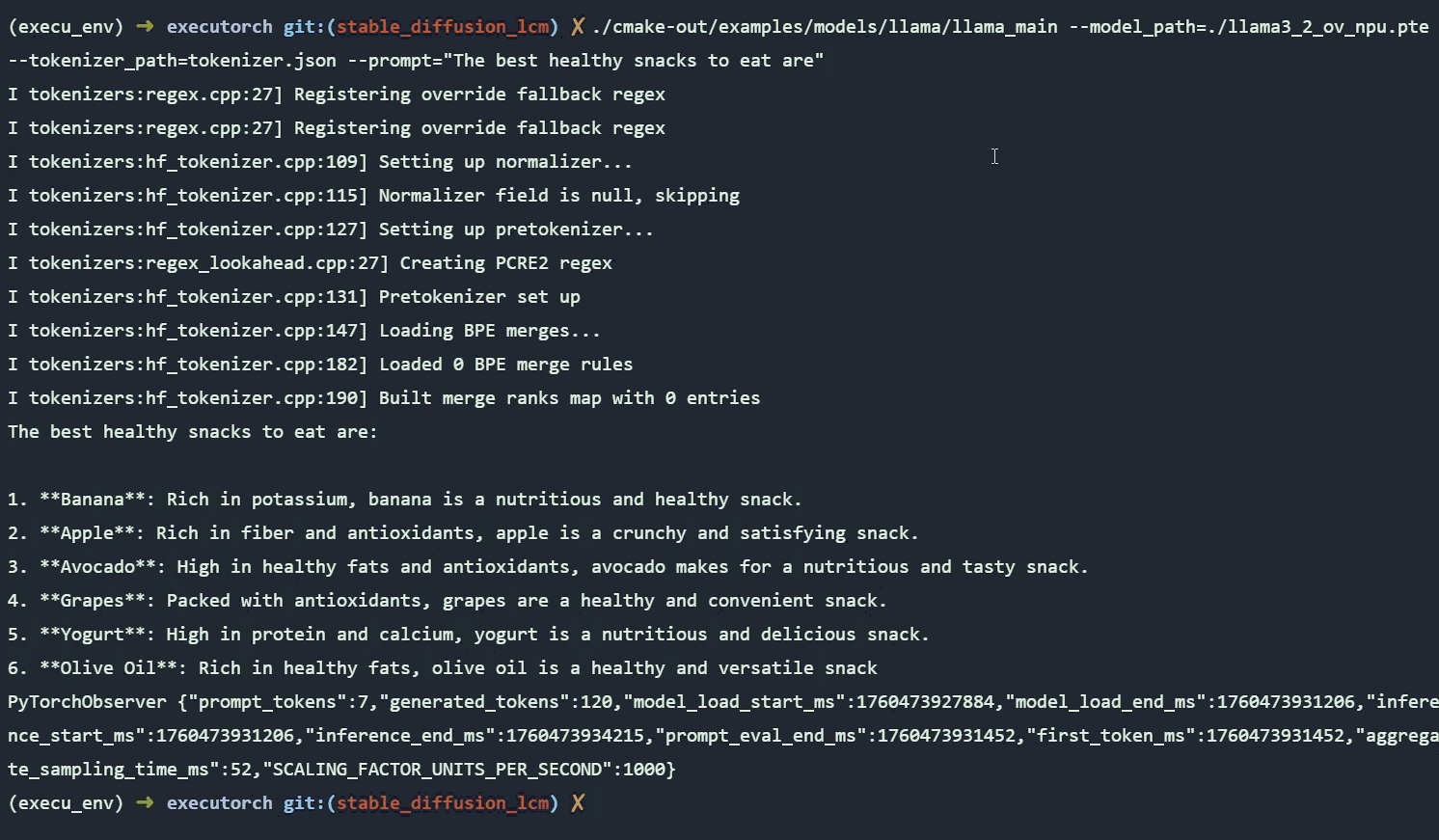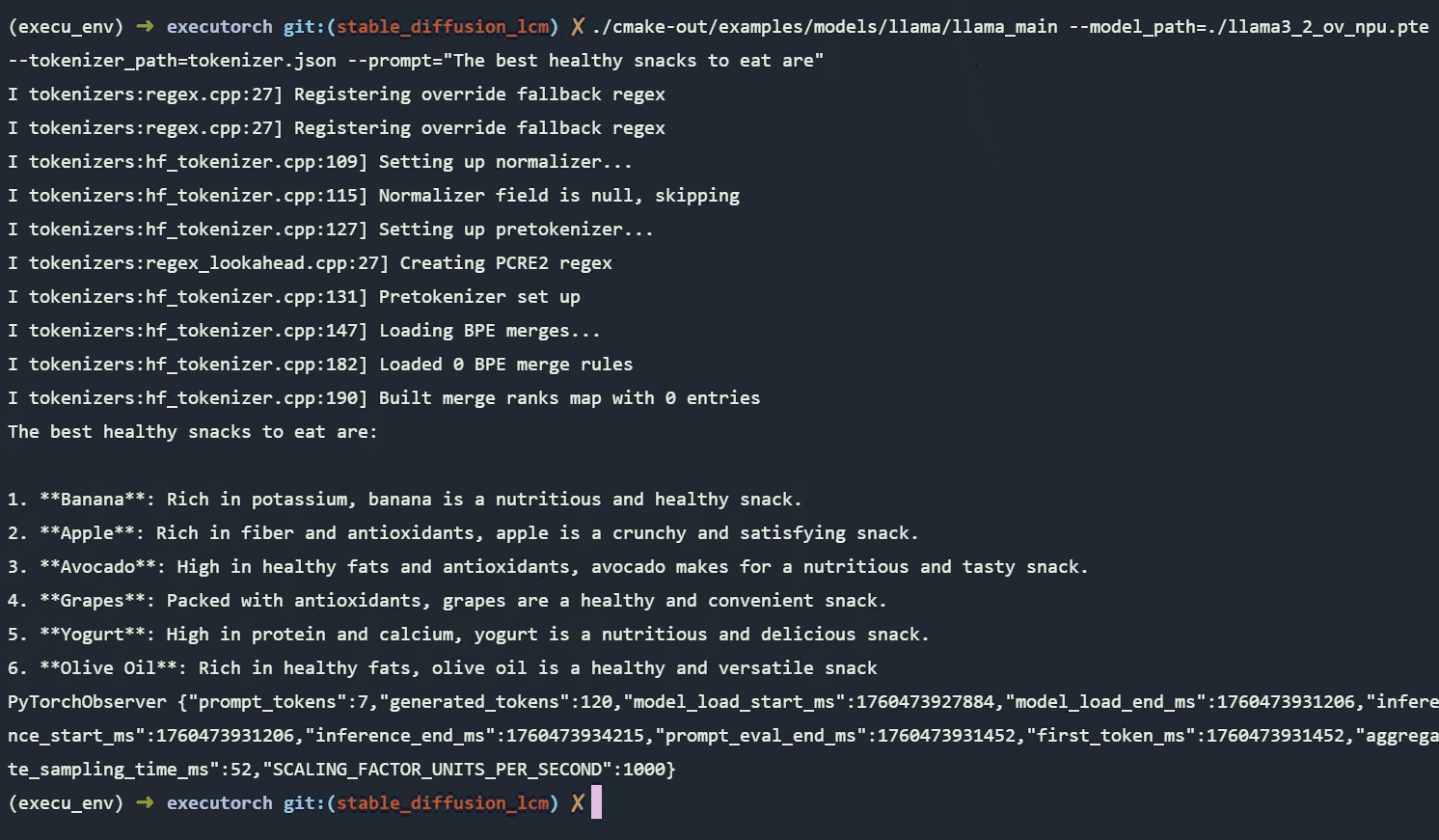
案例2:以Llama 3.2 1B實現裝置端聊天機器人
Llama是由Meta開發的一系列先進語言模型,旨在理解並生成類似人類的文字,應用於問答、寫作、摘要、程式碼編寫等任務。 Llama 3.2 1B 是一款為邊緣設備最佳化的輕量級版本,擁有約10億參數,支援長篇幅上下文(約128K tokens)和多語言,可用於摘要撰寫、指令遵循(instruction-following)和多語言文字生成等任務。
利用ExecuTorch將Llama 3.2 1B匯出到OpenVINO後端,即可在英特爾架構AI PC上高效率執行模型。此模型也能被量化為4位元整數(INT4)部署於OpenVINO後端,在充分利用英特爾硬體的同時,進一步加速推論速度與最佳化效能。
匯出與部署Llama 3.2 1B的詳細教學可在Llama官方網站範例頁面找到。下方的GIF圖檔展示Llama 3.2 1B在Intel Core Ultra (第二代) NPU上執行推論的效果。
案例3:Stable Diffusion圖片生成
Stable Diffusion是目前最先進的文生圖模型之一,可用文字描述生成高品質圖片,被廣泛應用於數位藝術、概念設計、原型製作與影像編輯等領域。Stable Diffusion的最佳化版本是Latent Consistency Model (LCM),只需要4到8個去雜訊步驟即可完成生成,相較於傳統 Stable Diffusion的25到50個步驟,不但大幅縮短了推論時間,也維持圖片品質。
藉由利用ExecuTorch與OpenVINO後端,開發者可以將LCM (SimianLuo/LCM_Dreamshaper_v7)部署於英特爾架構 AI PC 上直接執行文生圖任務。LCM 架構包含三個核心組件:文字編碼器、UNet與VAE解碼器,三者皆以FP16精度匯出,以便在英特爾架構硬體上利用OpenVINO進行部署。
匯出與執行此模型的詳細指引可以在Stable Diffusion官網的範例頁面找到。下方顯示的高解析度圖片就是透過Intel Core Ultra (第二代)處理器上的GPU加速推論所生成,只花了不到5 秒時間,展現該平台在縮短生成時間同時仍能產生高品質輸出的能力。

生成圖片時使用的提示詞是「日落時分的的山景搭配極光,數位藝術風格、鮮豔色彩」(Mountain landscape at sunset with aurora borealis, digital art style, vibrant colors)。
結語
ExecuTorch的OpenVINO後端是PyTorch生態系在裝置端AI推論上的一大突破,提供了一條穩健、對開發者友善的途徑,從研究模型到部署,皆遵循PyTorch 2.0的設計理念。透過將複雜的硬體感知量化與圖形劃分等任務自動化,讓開發者能無縫利用當代AI PC的全套運算資源,確保PyTorch模型能以使用者要求的效能與效率運作。
要了解更多相關資訊並開始使用,請參閱ExecuTorch官方文件和OpenVINO的可用資源。若想在英特爾架構硬體上實現更高的效能,或在邊緣、在雲端取得更多功能,快來使用原生OpenVINO工具套件吧!
(參考原文:Optimizing ExecuTorch on Intel-Powered AI PCs with OpenVINO™)

- AI Agent時代來臨:看邊緣AI如何成為驅動智慧機器人的關鍵 - 2025/11/28
- OpenVINO×ExecuTorch:解鎖英特爾架構AI PC模型推論效能新境界 - 2025/11/21
- 讓生成式AI應用在Intel架構系統本地端高效率運作的訣竅 - 2025/10/16
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


