我們正在用AI生成的資料來訓練生成式AI,最終,將落入一場「模型崩塌」的輪迴詛咒?

(source)
幾年前,生成式AI還像是一場人類創造力的革命。從ChatGPT到Stable Diffusion,AI能寫詩、畫畫、編曲、寫程式,讓人們驚呼「創造力的界線正在模糊」。
然而,當這些AI生成的內容反過來被餵回模型訓練資料集時,一場「遞歸詛咒」(The Curse of Recursion)也悄然展開。
所謂「遞歸」(recursion),是指模型使用自己生成的輸出,作為下一代模型的訓練輸入。看似效率極高的自我迭代,卻隱藏著深層危機:模型可能不再學習新的世界,而只是複製自己的幻影。
這正是劍橋大學與牛津研究團隊在 2023 年於論文《The Curse of Recursion: Training on Generated Data Makes Models Forget》中提出的警訊。他們發現,當AI訓練資料逐漸被「合成資料」取代,模型的性能與多樣性會隨代數下降,最終出現「模型崩塌」(Model Collapse)現象。
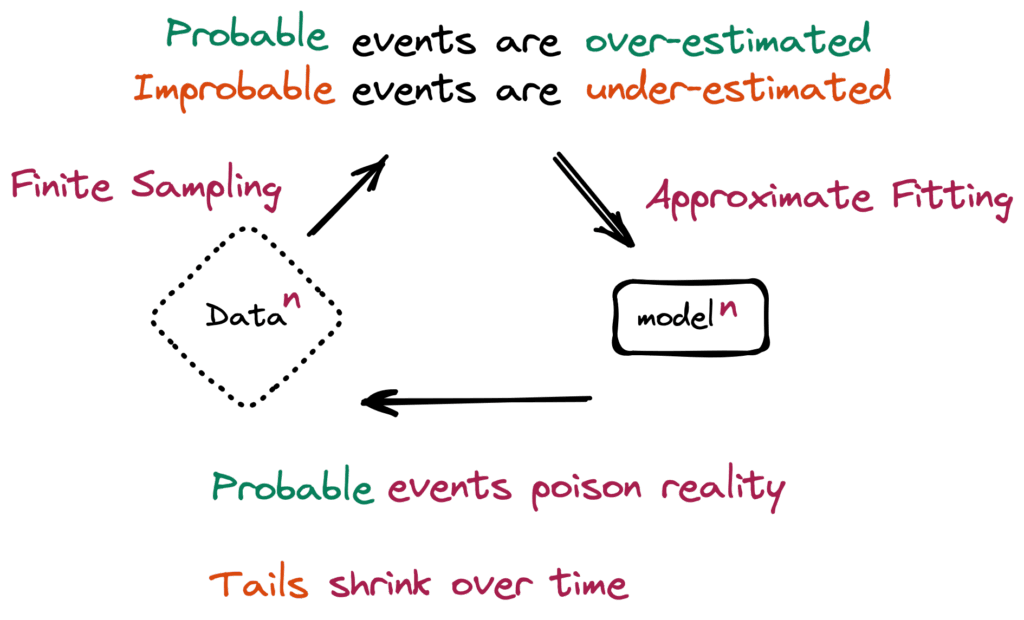
「模型崩潰」是指模型逐漸退化的學習過程,隨著時間的推移,模式會開始遺忘不太可能發生的事件,因為模型會被自身對現實的投射所毒害。(source)
換句話說,AI會忘記它曾經懂的東西,逐漸失去「學習真實世界」的能力。
當資料自己養自己:AI的資訊生態污染
要理解這場危機,得從資料說起。
生成式AI的崛起,仰賴海量的真實資料──人類的對話、文章、照片、程式碼與聲音。但如今,網路上充斥著AI生成的文字與影像。這些內容再被搜尋引擎索引、被社群轉傳、被開源資料庫蒐集。下一個世代的AI,便在不知不覺中,用上一代AI產出的內容進行學習。
這就是所謂的「資料遞歸污染」(Data Recursion Contamination)。
研究顯示,若這種「自生自滅」的資料循環持續下去,模型會越來越偏向常見模式,喪失對「尾部資料」(稀有事件、獨特語境)的感知。最終,AI的輸出會變得重複、保守、無創意──就像在影印影印機影印過的影印本。
AI社群戲稱這種現象為「資料近親繁殖」(Data Inbreeding):AI不再學習真實世界的多樣性,而是在模仿自己的模仿。
逆轉詛咒:累積真實與合成資料的新希望
不過,事情並非全然悲觀。2024年,一篇題為《Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data》的新研究,提出了破解之道。研究者發現,「崩塌」並非不可避免──關鍵在於如何管理資料的生成與使用。

兩種研究模型崩潰的設定。模型崩潰是指一系列基於自身輸出訓練的生成模型逐漸退化,直到最後一個模型失效的現象。左圖:許多先前的研究探討了每次模型擬合迭代都會取代資料的模型崩潰問題。右圖:本研究發現每次迭代都會累積資料的模型崩潰問題,並證明累積資料可以避免模型崩潰。(source)
傳統的遞歸訓練方式常採「替換策略」:每一代模型用上一代生成的新資料取代掉舊資料。這樣雖然節省儲存成本,但實際上會逐步削弱模型的多樣性。新研究則提出「累積策略」:保留原始真實資料,並持續加入新的合成資料。結果顯示,模型不但沒有崩塌,反而能持續維持穩定的表現。

資料累積避免了語言建模中的模型崩潰。基於Transformer的語言模型序列在TinyStories資料集上進行了迭代的預訓練(Cross-entropy驗證損失在重複替換資料時增加(左圖),但在累積資料時則不會增加(右圖)(source)
這個看似簡單的改變,揭示了一個深刻道理:創造力的維持,仰賴真實經驗的持續累積,而非自我複製。
研究團隊在論文中謹慎指出:「當我們說累積合成資料不會傷害AI系統時,我們並不是在宣稱合成資料總是好的。我們只是發現,如果真實資料不被取代,合成資料的加入不一定會導致退化。」
這句話意味深長。AI的未來,不在於完全拒絕合成資料,而是學會與之共存──找到一種能保留真實、多樣與創造性的平衡。
從模型崩塌到內容退化:媒體與社會的隱憂
這場看似技術層面的討論,其實與整個社會息息相關。
想像一個未來,網路上九成的內容都是AI生成的──新聞、圖片、影片、論文、社群貼文。當下一代模型再從中學習,它所理解的「世界」將越來越封閉,越來越不像人類真實的思想與語言。
這樣的資訊生態,將不只是技術問題,而是文化退化的開始。
在內容產業中,這現象尤為明顯。當AI工具成為主流創作引擎,平台上充滿「AI產出的AI內容」,人類創作者反而被邊緣化。作品之間的差異消失,創造力被平均化。最終,我們可能走向一個「無人創作卻滿地作品」的世界。
對科技媒體、設計師、開發者社群而言,這是一道新的命題:當AI的輸入與輸出都被AI佔據,創新從何而來?
資料多樣性:AI創造力的生命線
若要避免AI陷入自我複製的迴圈,關鍵在於維護「資料多樣性」。多樣性代表模型能接觸更多世界的邊界──不同語境、風格、文化與錯誤。這些「非典型」資料,正是創造力的源泉。
但合成資料的特性恰恰相反:它傾向強化平均,生成「最有代表性」的樣本,卻忽略了稀有與極端的情境。隨著合成資料比例增加,這些尾部資料逐漸消失,模型便失去了「創造性偏差」的空間。
有趣的是,這種現象與人類創造力的本質極為相似。藝術家、工程師與科學家之所以能創新,正是因為他們不斷探索「異常點」──那些不符合常規、卻孕育新可能的地方。如果AI只訓練在平均值上,它就再也無法「想像不一樣」。
不過,也有研究者認為,這場遞歸危機未必是死路。某些團隊正嘗試讓模型具備「自我察覺」機制——能判斷輸入資料是否為合成內容,並在學習過程中調整權重或濾除過於相似的樣本。另一些實驗則讓模型在生成資料時刻意引入隨機變異(stochastic perturbation),以保持資料分佈的廣度。
這些方法某種程度上讓AI「學會懷疑自己」,也讓它不再是單純的複製機器,而更像一個能反思的創作者。這樣的AI,不再只是模仿,而能在真實與虛構之間尋找新的創造空間。
創造力的守護戰
對於致力於推動創造與技術融合的開發者社群來說,「遞歸的詛咒」並非只是模型訓練問題,而是關於「創造力可持續性」的根本挑戰。
這提醒我們:科技創造力並非憑空生成,它來自人類的經驗、文化與多樣的真實資料。
AI或許能模仿創造,但它的靈魂仍然仰賴人類世界的真實供給。
因此,當產業開始大規模採用合成資料時,如何確保真實資料的保存、來源標註與多樣性,將成為下一波AI倫理與創新競爭的焦點。這場資料治理之戰,也將決定AI未來是成為「創造力的放大器」,還是「創造力的耗損者」。
(責任編輯:歐敏銓)
》延伸閱讀:
- The Curse of Recursion: Training on Generated Data Makes Models Forget (arXiv)
- Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data (arXiv)
- How Bad is Training on Synthetic Data? A Statistical Analysis of Language Model Collapse (arXiv)
- IBM Think: What is Model Collapse and Why It Matters
- Ryland Schaeffer: Is Model Collapse Inevitable? (Research Page)
- Why the fears of AI model collapse may be overstated

- NVIDIA與Hugging Face為LeRobot導入全新開源模型與框架 - 2026/07/13
- 電腦視覺結合AI、數位孿生 2026年世足賽號稱史上最「高科技」 - 2026/07/10
- Agentic PC來了?NVIDIA RTX Spark重塑邊緣、桌機算力版圖 - 2026/07/09
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


