作者:Annie Tallund,Arm
Arm正在運用以支援AI快速發展為設計目標的解決方案,來打造邁向未來的路徑。其中的一項挑戰,是讓相關社群能夠取用新興的技術。在這篇部落格文章中我們將介紹Arm機器學習推論諮詢工具(Arm ML Inference Advisor,Arm MLIA),並讓大家看到如何運用它來提升Arm IP的模型效能。我們同時也會解釋一些相關的前置作業,以及為何這些作業如此重要。
機器學習中未知的硬體部分
只要問過任何設計網路的人,就知道這件事相當具有挑戰性,你必須瞭解一些複雜的概念才能搞定。在機器學習的領域裡,許多人熟悉如TensorFlow 與PyTorch等高階的應用程式介面,這些強大的工具協助我們針對使用場景設立流程:訓練、微調與產生runtime。
當為了部署而對模型進行編譯時,一般的假設是任務已至尾聲;你在訓練過程中針對模型的參數進行微調,而你的機器學習流程也已完成最佳化。當你把這個模型部署到目標硬體將會如何呢?會影響整個處理器的效能嗎?今天我們就來了解這個任務的其他環節。
低階處理器架構不是個簡單的題目,要知道它的重要性不難,難在了解「為何」它很重要。對機器學習開發人員而言,了解執行推論的硬體或許不是優先事項。同時,嵌入式軟體開發人員要瞭解機器學習模型最佳化領域,可能頗為艱難。
有了Arm機器學習推論諮詢工具,我們的目標是縮短其間的落差,並讓所有抽象層級的開發人員,都能取用Arm的機器學習IP。在深入探討該工具的功能之前,我們先花點時間了解此一硬體觀點。
從雲端到邊緣再到終端裝置,Arm致力於為機器學習推論帶來極大的效能、功耗與面積效率。
- 我們最佳化神經網路的運算子,讓機器學習工作負載的運行更快速。這意味著我們檢視核心的實作,並使用Arm指令集來取代通用的呼叫。這可以為Arm IP對運算子進行加速。請參考CMSIS-NN 以及Arm NN TensorFlow Lite Delegate的實例。
- 我們在效能的分析上投入許多時間,以了解其瓶頸所在。我們藉由掌握指令週期在每一層所花的時間並執行記憶體管理,以極大化硬體與軟體的資源使用效率。
- 我們進行模型調節,以便極小化記憶體的面積或推論的時間。例如,使用量化方法可以縮小模型的大小,同時維持精確度。
這些面向將對神經網路的效能造成顯著的差異。其中一個實例是Arm Ethos處理器,這是一種神經網路處理器(NPU),可搭配Arm Cortex-M處理器核心。此一NPU的設計用意是在嵌入式裝置執行機器學習網路,意味著在這個空間內載入越多的運算子,你的網路運作效能就會越好。
舉例來說,Ethos-U65結合具備AI功能的Cortex-M55處理器,與現有的Cortex-M CPU相比,針對量化的關鍵詞辨識Micronet模型,機器學習的效能可提升高達1,916倍。
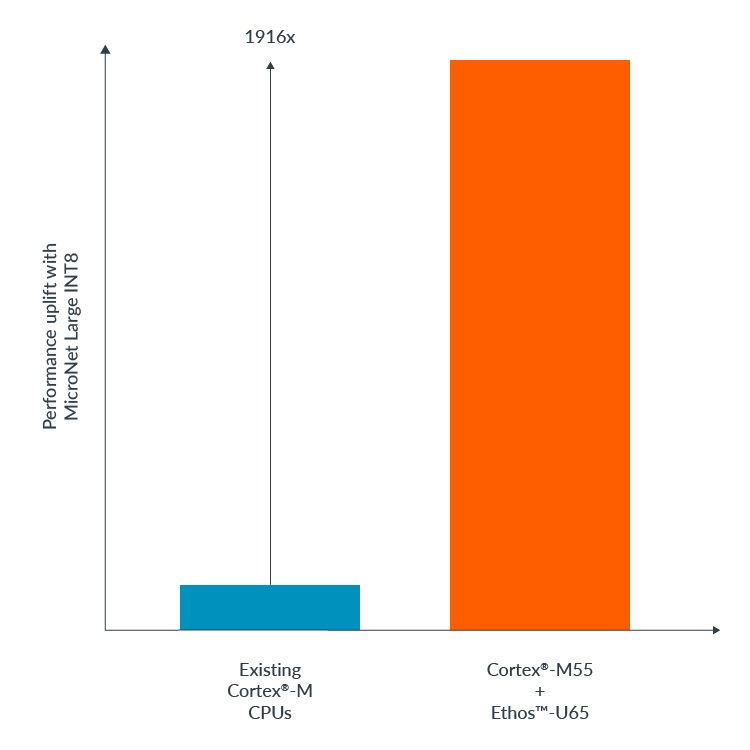
在Micronet模型上使用Ethos-U55帶來的效能提升。
現在我們已經了解對硬體目標進行模型最佳化如此重要的原因,現在就來談談如何開始強化神經網路的效能。
簡化硬體效能分析與最佳化
Arm MLIA是一種分析神經網路如何在Arm架構上運作的工具,它還能將最佳化參數套用到已知的模型。它的誕生源自於將Arm在這些領域的努力結果集結為一套工具的需求,並讓具備不同技能組合的各種開發人員都能使用。兩個主要的輸入資料包括模型檔案(Keras或TensorFlow Lite),與你打算部署的硬體配置。
Arm MLIA會分析這個組合,並針對如何改善該模型提出建議。它使用兩個基本指令:檢查與最佳化:第一個指令讓我們可以檢視主要的參數,以及此一複合結果對於推論代表什麼意義;第二個指令則會把最佳化的參數套用到模型上。下圖描述如何套用這些功能。
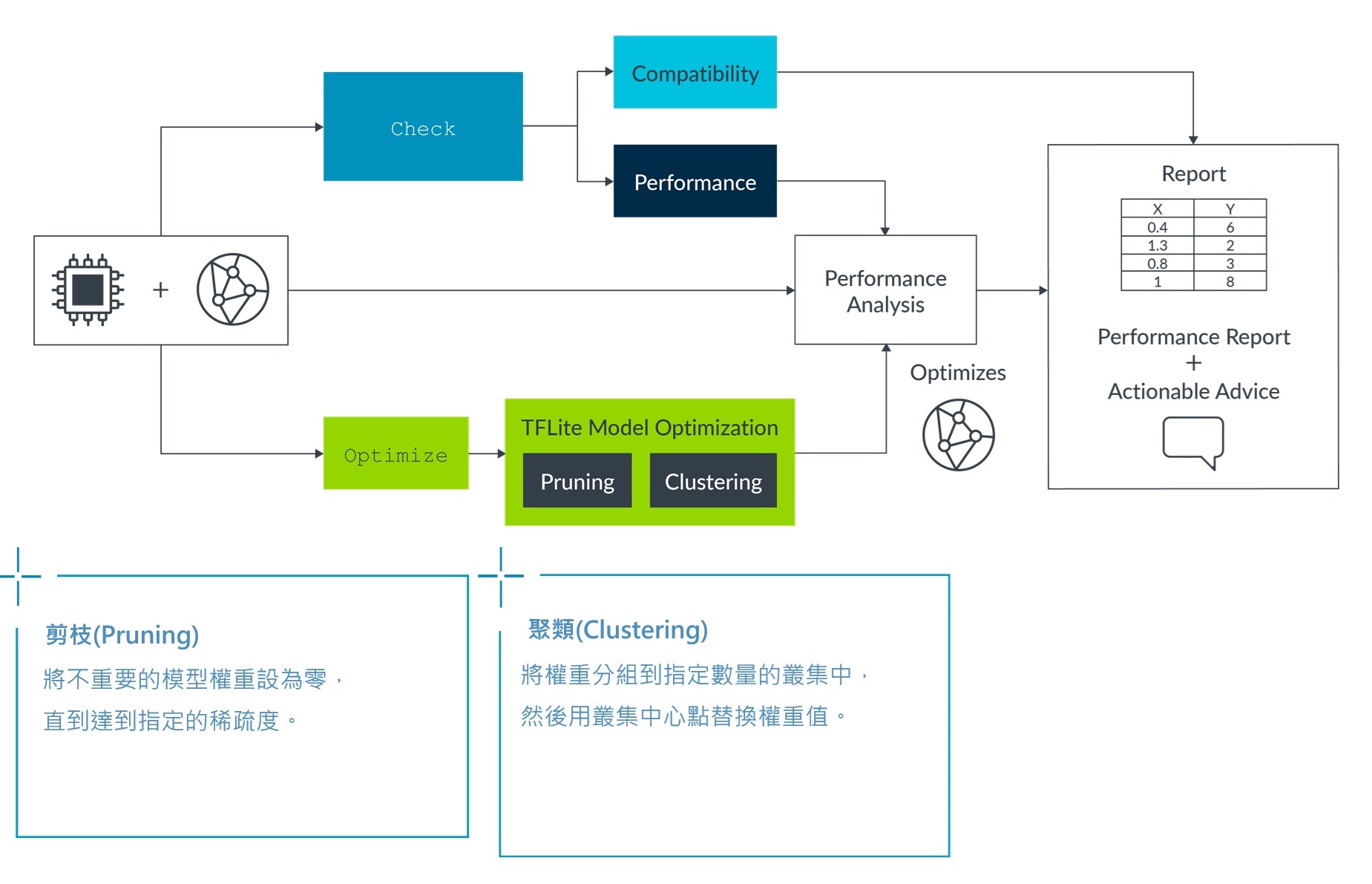
所有的目標都是使用後端來進行模擬的。我們可以把後端解釋成能夠模擬目標硬體特性、或預測它的效能的技術,或是兩者兼具。

讓我們一起看看它會是什麼模樣。我們聚焦在兩個使用場景,並針對Hello Edge報告中的DS-CNN Small關鍵詞辨識模型,以Ethos-U55為目標。該模型可以從Arm ML-Zoo取用;Arm ML-Zoo則是一套針對Arm IP完成最佳化的機器學習模型。
相容性
針對效能對神經網路進行分析,其重點在於找出瓶頸。Arm MLIA可為此一工具支援的多個目標,提供一份運算子的相容性報告。這意味著我們可以找出網路上針對已知目標但不具備最佳化實作的所有運算子,原因是它們存在讓推論慢下來的風險。
相容性表格可以表示哪些運算子能夠在NPU上運作,其他的則會退回到軟體實作,並在CPU上運作(結果是效能較低)。我們替換完那些運算子後,可以讓推論運行得更快。你可以使用已下另一個不同的指令來檢查與比較效能的差別:
mlia check -t ethos-u55-256 ../ML-zoo/models/keyword_spotting/ds_cnn_small/model_package_tf/model_archive/model_source/saved_model/ds_cnn_small/ \
--compatibility
這個指令會產出一個相容性表格,並顯示每一個層會執行何種IP;此外,它也會回報與NPU相容及不相容的運算子的比例。在這個實例中,我們看到NPU 百分之百支援DS-CNN Small模型的所有運算子,這也讓它極為適合在已知的目標上運作。
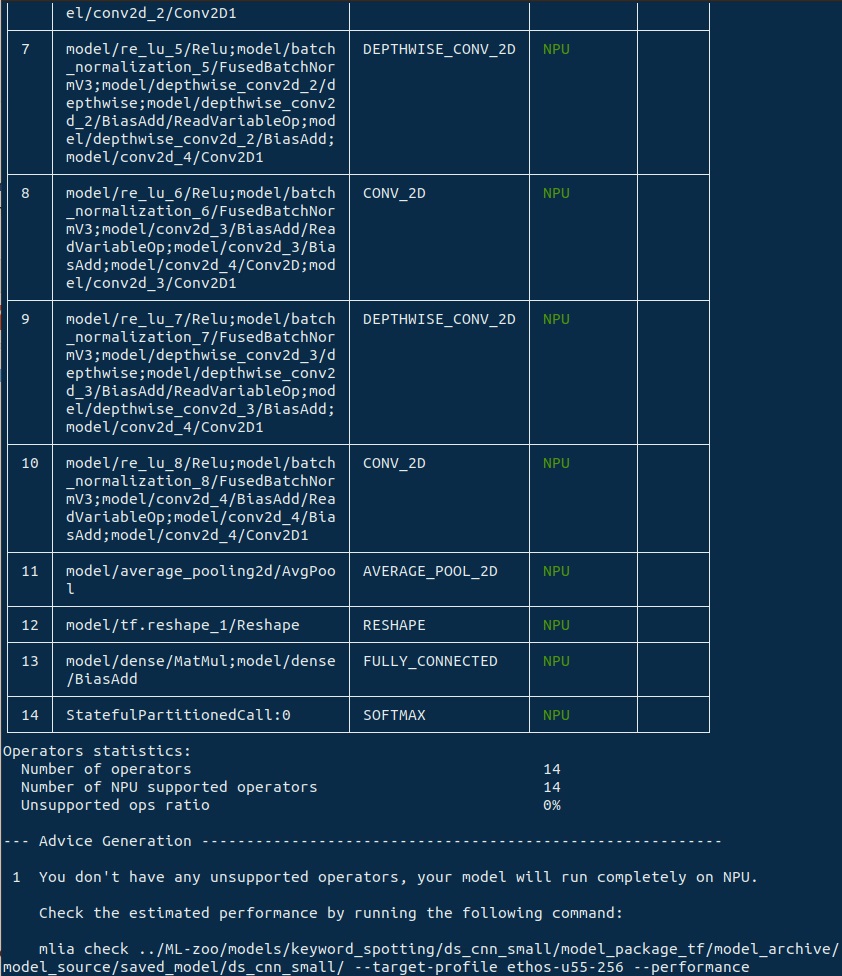
執行相容性指令後輸出的表格。
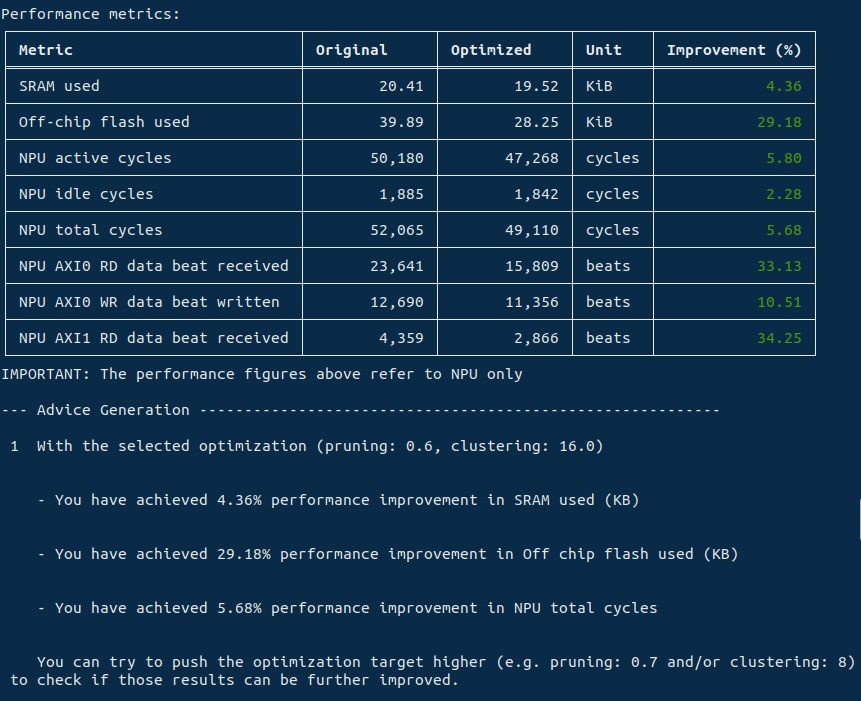
Arm MLIA提供一個工作流程,讓我們把最佳化技術部署到已知的模型上。我們可以試著運用它為模型進行不同的硬體組合,並看看哪一類型的最佳化最有利於您的應用場景。這裡我們顯示剪枝、分群與量化的實例。MLIA最終會輸出最佳化過的模型(請注意最佳化後的模型不會保有精確度,它的用途是進一步的開發與除錯),以及您最終可以預期看到的效能提升報告。
這種端對端的方式,可以降低開發人員把硬體最佳化技術套用到他們網路的門檻,而且還不需要取用到硬體。這套工作流程最多可以為模型的效能提升1.2到2倍,同時因為量化同時維持住模型的精確度,它最多可以把模型的尺寸縮小至四分之一。
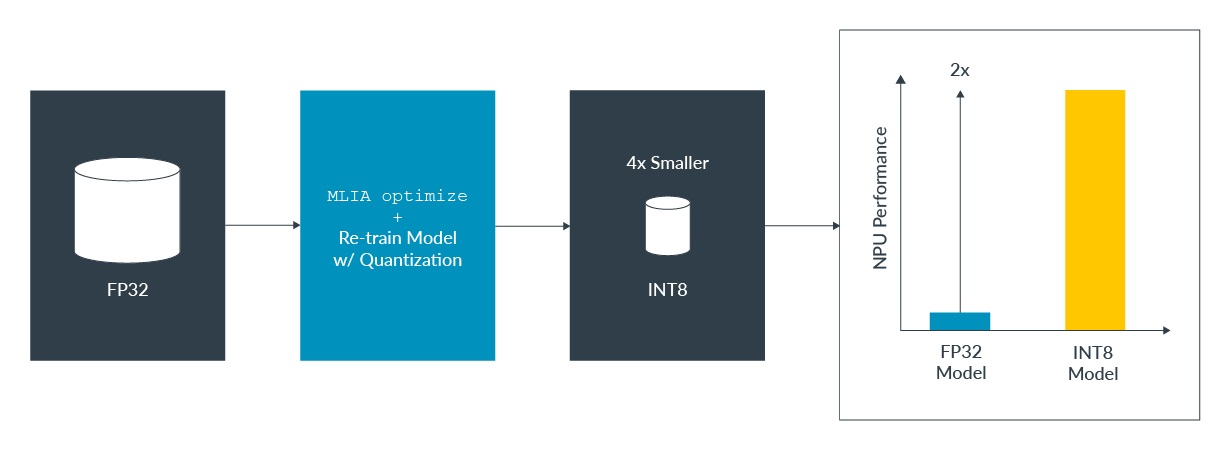
以下有個實例:
# Custom optimization parameters: pruning=0.6, clustering=16
mlia optimize ../ML-zoo/models/keyword_spotting/ds_cnn_small/model_package_tf/model_archive/model_source/saved_model/ds_cnn_small/ \
--target-profile ethos-u55-256 \
--pruning \
--pruning-target 0.6 \
--clustering \
--clustering-target 16
下方表格顯示了效能的提升,我們會在最後部份提供更進一步的建議。針對剪枝-分群的最佳化,我們目前需要輸入一個Keras模型,而檢查(check)的指令也同時支援TFLite。
總結
希望我們的這篇文章能引起您在Arm IP上進行模型最佳化的興趣,並將您的神經網路推升至更高的境界。Arm致力於支援明日的AI科技,並讓所有對此使命做出貢獻的開發人員都能使用到這些技術。
我們努力的其中一環就是提供正確的工具。隨著這篇文章進入尾聲,我們希望大家都自行嘗試。Arm MLIA是開源的工具,可透過pip取得:
pip install mlia
若要執行上述指令,您可從Arm Model Zoo下載模型:
git clone https://github.com/ARM-software/ML-zoo.git
備註:若要正確複製Model Zoo裡的檔案,您可能需要配置Git Large File Storage (LFS)。
我們致力於讓Arm MLIA更為完善。未來的努力方向包括為這個工具增添更多類型的Arm IP,以及自動化一些最佳化的建議。我們歡迎新的建議與回饋。如果您需要協助或有任何問題,請跟我們聯絡。請來信,或是使用AI與ML論壇,並在您的留言中tag MLIA。
(參考原文:Take your neural networks to the next level with Arm’s Machine Learning Inference Advisor;中文版校閱者為Arm主任應用工程師林宜均;責編:Judith Cheng)
- 【Arm的AI世界】打造車用裝置端多模態助理 - 2026/06/16
- 【Arm的AI世界】運算平台開發者必看:無須硬體也能進行OpenBMC+UEFI模擬與驗證! - 2026/04/09
- 【Arm的AI世界】運用ExecuTorch與Arm SME2加速裝置端機器學習推論 - 2026/03/18
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


