作者:Per Åstrand,Arm首席工程師 & Fredrik Knutsson,Arm首席工程師暨團隊主管
AI正在變得更輕量。不再受限於雲端或高效能智慧型手機,次世代智慧正逐步進入最微小的裝置:智慧感測器、穿戴式裝置,以及僅靠毫瓦級功耗與數十KB記憶體運作的工業系統。這些環境極為嚴苛,因為每一個時脈週期、每一個位元組都需謹慎運用。要將現代AI帶入這類平台,過去往往必須在準確度、效率與開發效率之間做出艱難取捨。
隨著ExecuTorch 1.0 進入正式版(GA)階段,過去的取捨正逐漸不再構成阻礙。做為PyTorch生態系的一部分,ExecuTorch在創新與嵌入式部署之間建立起更順暢的連結,讓開發者能在各類Arm 邊緣裝置上執行最先進的模型——從搭配Arm Ethos-U NPU、強調低功耗的微控制器,到採用Arm CPU、支撐高效能需求的工業級解決方案皆然。
ExecuTorch:可攜、效能強、開發更輕鬆
ExecuTorch將PyTorch的優勢直接帶到邊緣端,並以三大核心原則為基礎建構而成:
- 可攜性(Portable):提供一致的執行堆疊,可同時支援Arm CPU、GPU與NPU,開發者無需重寫模型即可跨平台部署。
- 高效能(Performant):透過最佳化的執行階段與後端,協助模型在嵌入式裝置的嚴格資源限制下順利運行。
- 高生產力(Productive):維持PyTorch熟悉的開發流程,並提供原生的降低 (lowering)與量化工具,使部署流程更簡潔明瞭。
有了ExecuTorch 1.0,在邊緣端部署AI不僅變得可行,更能以完整的PyTorch流程實現。無需額外框架、無需轉換,只需透過一條從研究到量產的直接、最佳化路徑即可完成。
從PyTorch到邊緣端:完整、一致的流程
ExecuTorch讓PyTorch模型往高效率嵌入式執行的流程更加順暢。如下圖所示,模型可透過不同的後端指定,進行匯出與降低,並對應到完整範圍的Arm邊緣端IP──從NPU到Cortex-A與Cortex-M CPU皆可支援。這套統一的軟體堆疊讓開發者能以PyTorch做為起點,並以一致的工具鏈、可預期的效能,順利在各類Arm邊緣裝置上部署,同時建立起從研究到量產更明確的開發路徑。
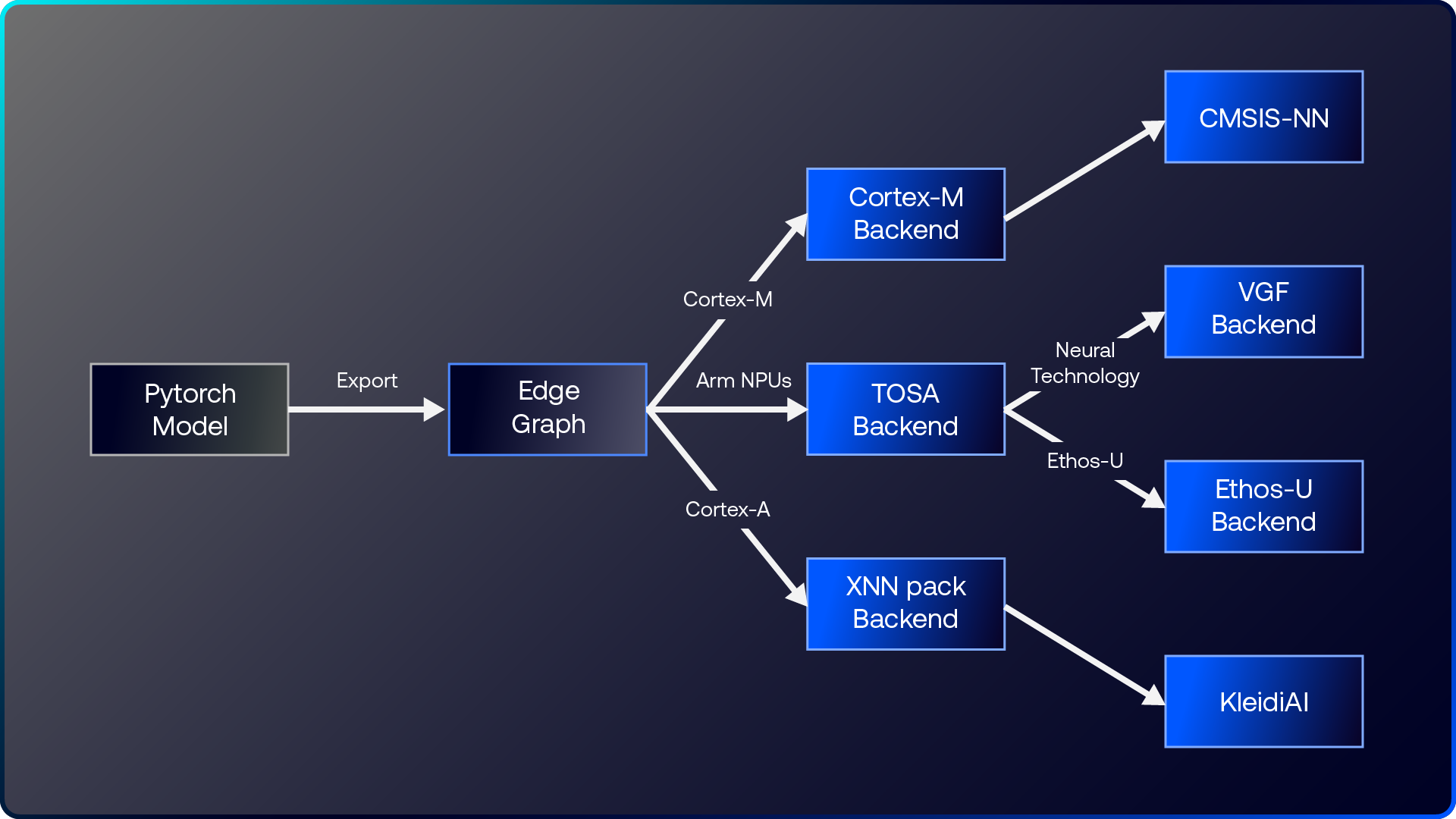
圖1:透過ExecuTorch後端指定支援Arm邊緣端IP的方式
TOSA:為 Arm NPU 打造的統一基礎
2025年稍早發布的TOSA(Tensor Operator Set Architecture)1.0 規格與工具,為在Arm NPU與類神經網路技術上部署 AI 工作負載奠定了一致且穩定的基礎。在 ExecuTorch 之中,TOSA 後端會將大多數邊緣端常用的運算元(int8 與 float32)降低成通用且具可攜性的格式,以維持可預期的執行行為。而尚未被涵蓋的運算元(operators)則會回退至CPU,透過參考核心(reference kernels)進行執行。這條統一化的路徑讓TOSA成為大規模嵌入式AI的核心支柱,使Arm全系列NPU均能以一致方式獲得加速、順利推動邊緣端的 AI 部署。
Ethos-U:量產就緒等級的AI加速方案
ExecuTorch 1.0對Ethos-U系列NPU提供量產就緒等級的支援,而這些NPU正是為超低功耗AI加速所設計。其主要特色包括:
- 約80%的邊緣端AI運算元涵蓋率。
- 支援int8,並提供int16的實驗性支援。
- 超過100個模型可從TorchVision、TorchAudio與HuggingFace等主流來源,順利在Ethos-U上完成端對端執行。
- 在多組具代表性邊緣端工作負載上的效能表現與其他AI框架相當,證明TOSA合法化與執行流程的效率。
這也讓Ethos-U成為目前在微控制器層級執行進階PyTorch模型最完整的解決方案。例如,過去難以想像的情況,如今已能實現:以Transformer為基礎的架構——例如Conformer模型——現在已可在採用Ethos-U85的邊緣裝置上順利運作。
搭配 VGF 後端的神經網路技術
ExecuTorch 1.0也透過全新的VGF (Vulkan Graph Format)後端,加入對Arm即將推出、並將在2026年Arm GPU中導入的類神經網路技術支援。這項能力使開發者能以AOT(Ahead-of-Time)方式匯出與執行神經網路,支援未來Arm GPU上的多種應用情境,例如類神經超取樣 (Neural Super Sampling,NSS)、降噪(denoising)以及以機器學習驅動的渲染流程。更完整的技術內容已在另一篇部落格文章中說明,不過最關鍵的重點在於:當前支撐Ethos-U的ExecuTorch與TOSA基礎架構,同樣延伸至次世代神經圖像加速技術。這代表開發者現在就能開始嘗試,並以同一套Python 與PyTorch為基礎的開發流程,為未來的圖像與AI整合做好準備。
Cortex-M + CMSIS-NN:隨處均可展現高效率
Arm Cortex-M CPU 是嵌入式領域的核心基礎,每年在全球出貨數十億個裝置。透過ExecuTorch與CMSIS-NN的整合,即使是在僅使用CPU的情況下,模型推論也能從最佳化後的核心中獲得效能提升。目前Cortex-M的加速支援已可使用,且後續仍持續進行改進,將在整個產品系列中帶來更高的效率。
Cortex-A + XNNPACK:透過 Arm KleidiAI 擴展效能
針對高效能、以 Linux為基礎的平台,ExecuTorch 1.0也將同樣順暢的開發流程帶到Cortex-A CPU。透過XNNPACK並結合Arm KleidiAI的最佳化調校,開發者能在邊緣端工作負載上達到峰值效能。這樣的能力讓模型能夠自然從微控制器擴展至以Cortex-A為基礎的邊緣運算裝置,而無需更動整體工作流程。
無需硬體即可進行評估
並非每位開發者手邊都有硬體,而啟動邊緣端AI開發不應取決於晶片到位與否。透過不同的Arm後端,開發者即使在硬體尚未取得前,也能先行評估與驗證模型:
- Ethos-U:透過Arm Corstone子系統,開發者可使用固定虛擬平台(Fixed Virtual Platform,FVP)來模擬Ethos-U目標平台。從這裡開始,部署流程相當明確:可先從FVP過渡到FPGA原型設計,最終再部署至基於Arm Corstone的晶片實作。
- 支援類神經網路技術的GPU:針對未來的GPU加速,ExecuTorch提供可模擬硬體行為的仿真途徑,讓開發者在第一代晶片問世前,就能提早進行開發與測試。
這種分層式的方法讓開發者即使在沒有實體硬體的情況下,也能著手進行AI工作負載的原型設計、驗證與調校。這與ExecuTorch所追求的高生產力目標相當契合。
Python原生後端:可調整、可擴充
ExecuTorch 1.0與Arm的整合有一大特色:從模型降低到後端編譯器,整個流程皆以Python實作。這讓後端具備高度透明性並可自由調整:
- 開發者可以輕鬆檢視並修改降低路徑。
- 若有功能缺口,也能在不必深入複雜C++或專有工具鏈的情況下加以補強。
- 更容易回饋貢獻至專案社群,有助擴充運算元支援並強化效能最佳化。
這個設計選擇讓開發體驗與PyTorch高度貼近,同時仍能發揮Arm硬體的效率優勢。這也代表:當您需要依據自身的模型、工作流程或硬體架構調整ExecuTorch 時,所需的工具都能在熟悉的開發環境中直接取得。
在部署階段,ExecuTorch提供一個輕量的C++ runtime,可輕鬆整合至各類應用之中。這個runtime以可攜性與效率為核心設計,即使在資源受限的裝置上仍能提供可預期的效能,同時維持相當精簡的部署體積。Python的開發流程與C++的執行階段相互配合,形成從試驗到量產一條順暢銜接的路徑。
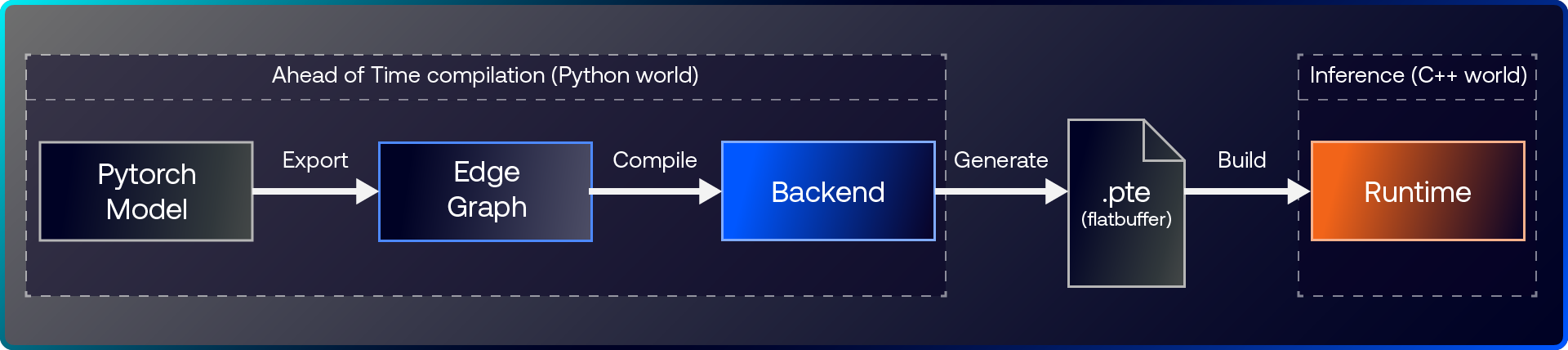
圖2:ExecuTorch具備高效的C++ 執行階段與可調整的AoT編譯流程
開發流程範例:從PyTorch到Ethos-U
使用ExecuTorch 時,針對Ethos-U的典型工作流程如下:
- 在PyTorch中開始開發,可選用來自HuggingFace、TorchAudio或TorchVision的模型。
- 透過ExecuTorch的原生工具,在Python中直接進行量化與降低。
- 部署至Ethos-U,達成毫瓦級功耗下的推論效能。
- 在Corstone FVP上進行驗證而無需實體硬體,或在Cortex-M上透過CMSIS-NN執行後備路徑。
將 PyTorch 模型轉換成可部署的 .pte 成品相當直覺。下方程式片段示範了典型的流程步驟:
# Conformer model with the same hyper parameters as how we have trained it.
model = Conformer(num_classes=vocab_size)
dataset = torchaudio.datasets.LIBRISPEECH()
# Pick 100 random indexes for calibration
calibration_set = torch.utils.data.Subset(dataset, random.sample(range(len(dataset)), 100))
calibration_loader = torch.utils.data.DataLoader(
calibration_set, batch_size=1, shuffle=False, collate_fn=collate_fn
)
# Load the checkpoint data for the model weights
checkpoint = torch.load(path_to_checkpoint, weights_only=True)
model.load_state_dict(checkpoint["model"])
model.eval()
exported_program = torch.export.export(model, example_inputs, strict=True)
graph_module = exported_program.module()
compile_spec = EthosUCompileSpec("ethos-u85-256")
# Create the quantizer and use the ExecuTorch PT2E flow to quantize the model
compile_spec = EthosUCompileSpec("ethos-u85-256")
quantizer = EthosUQuantizer(compile_spec)
quantizer.set_global(get_symmetric_quantization_config(is_per_channel=True))
quantized_graph_module = prepare_pt2e(graph_module, quantizer)
# Do the post-training quantization calibration using the dataset
for feats, feat_lens, *_ in calibration_loader:
feats, feat_lens, *_ = next(
iter(calibration_loader)
)
quantized_graph_module(feats, feat_lens)
# quantization parameters are captured and the model is re-exported
quantized_exported_program = torch.export.export(
convert_pt2e(quantized_graph_module), example_inputs, strict=True
)
# Create partitioner that delegates the parts it can accelerate to the backend
edge_program_manager = executorch.exir.to_edge_transform_and_lower(
quantized_exported_program,
partitioner=[EthosUPartitioner(compile_spec)],
)
# Create the artifact representation of the quantized model
executorch_program_manager = edge_program_manager.to_executorch(
config=executorch.exir.ExecutorchBackendConfig(extract_delegate_segments=False)
)
# And save to disk for deployment on the Ethos-U85 target
executorch.exir.save_pte_program(
executorch_program_manager, "conformer_quantized_ethos-u85-256.pte"
)
這個端對端的流程示範了ExecuTorch 1.0如何讓Ethos-U部署達到量產就緒等級,同時維持開發者熟悉且具彈性的 PyTorch 開發環境。完整範例可參考ExecuTorch 文件,以及ASR 範例中的 PTQ 部分。
展望未來:下一步發展方向
ExecuTorch 1.0只是起點,接下來Arm的規劃將包括:
- 更智慧的量化方法:導入動態範圍量化 (Dynamic Range Quantization,DRQ)與選擇性量化,以便更精準地掌控模型準確度。
- 更廣泛的CPU加速:擴充 CMSIS-NN 支援,進一步最佳化 Cortex-M 的效能。
- 更豐富的範例:加入更多實際應用情境與操作教學,展示 ExecuTorch 在真實部署中的效益。
- 更完整的資料類型支援:從現有的 int8、float32 與實驗性的 int16,擴展至TOSA延伸套件所涵蓋的更廣範圍類型。
綜合上述進展,AI在Arm上的發展將不僅效率更高,也能讓全球開發者更容易採用。ExecuTorch 1.0已是一項重要的里程碑,提供高效率的CPU執行路徑、順暢的PyTorch-to-Arm工作流程,以及在模擬硬體上即可完成的簡易原型設計。邊緣端 AI 的未來已然成形。立即前往ExecuTorch 網站,開始以ExecuTorch部署您的PyTorch模型。
延伸閱讀
- Arm Newsroom blog
- ExecuTorch documentation
- ASR training example on Ethos-U using ExecuTorch
- Learning paths: 學習路徑
- Arm Community blog post on ExecuTorch support for Arm neural technology
- ExecuTorch Ethos-U minimal example notebook.
(參考原文:Ethos-U and Beyond: How ExecuTorch 1.0 powers AI at the edge;本文中文版校閱者為 Arm 首席應用工程師林宜均)
- 【Arm的AI世界】運用ExecuTorch與Arm SME2加速裝置端機器學習推論 - 2026/03/18
- 【Arm的AI世界】重新思考CPU在AI中的角色:在DGX Spark上實作實用的RAG - 2026/02/12
- 【Arm的AI世界】運用本地端LLM推論重塑智慧家庭的隱私與延遲表現 - 2026/01/19
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!