作者:歐敏銓
正如一位研究者在接受訪問時所言:「過去十年,我們讓 AI 學會思考;未來十年,我們要讓 AI 學會行動。」而 VLA,正是這場變革的開端。
喜歡用聽的?可收聽本文Podcast的精采對話喔(by GenAI):
「如果說大型語言模型(LLM)讓機器學會『理解』語言,那麼 VLA(Vision-Language-Action)模型則讓機器能夠『行動』。」在 2022 年至今短短幾年內,這項新興技術已從研究室的實驗性嘗試,走向機器人、智慧駕駛與嵌入式系統的實際應用,成為全球 AI 技術演進中最受矚目的多模態協同突破。
技術浪潮的起點
在 AI 發展的時間軸上,2022 年被視為一個重要的分水嶺。彼時,ChatGPT 帶動了語言模型的爆發,但在機器人領域,研究者開始思考:僅僅能「說話」與「理解」還不夠,如果 AI 無法根據視覺感知做出精準的行動,智慧化的落地仍舊遙不可及。
VLA 的誕生正是為了解決這一缺口。它將視覺(Vision)、語言(Language)與行動(Action)統合在同一個框架中,讓機器不再只是被動回應指令,而能主動在真實世界中執行任務。例如,當人類對機器人下達「請把桌上的紅色杯子遞給我」的指令,VLA 模型不僅要理解語句,還要辨識環境中的物體、推理正確的動作路徑,最終把杯子安全送到使用者手中。
三階段演進:從整合到泛化
短短三年間,VLA 模型的演進被劃分為三個明確的階段。
第一階段是基礎整合:研究人員嘗試將視覺模型與語言模型透過「後期融合」的方式連結,形成能夠同時處理圖像與文字的框架。但由於視覺與語言特徵之間的對齊不足,這類系統在複雜任務上常顯得力不從心。
第二階段是專業化:隨著自駕車與機器人應用需求上升,研究開始引入物理推理與場景理解,讓模型能夠處理真實環境的不確定性。3D 場景重建、動態障礙辨識,以及記憶機制的引入,使 VLA 能從一次性指令過渡到長期、多步驟的任務控制。
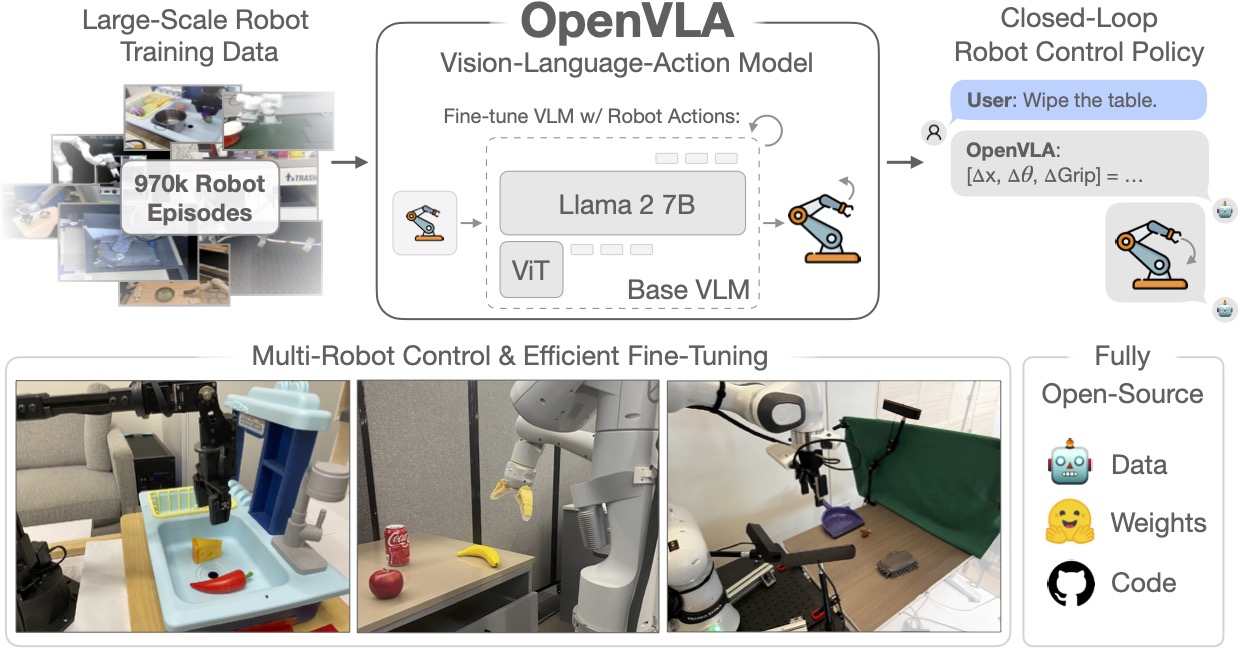
第三階段則是泛用化:代表性成果如 OpenVLA 與 NVIDIA 的 GR00T N1,不僅強調跨場景能力,還能支援不同平台的嵌入式部署,這使得「一次訓練,多處應用」成為可能。這正是 AI 技術商業化落地的關鍵所在。
架構創新的故事
要理解 VLA 的突破,就不能忽視架構上的設計革新。
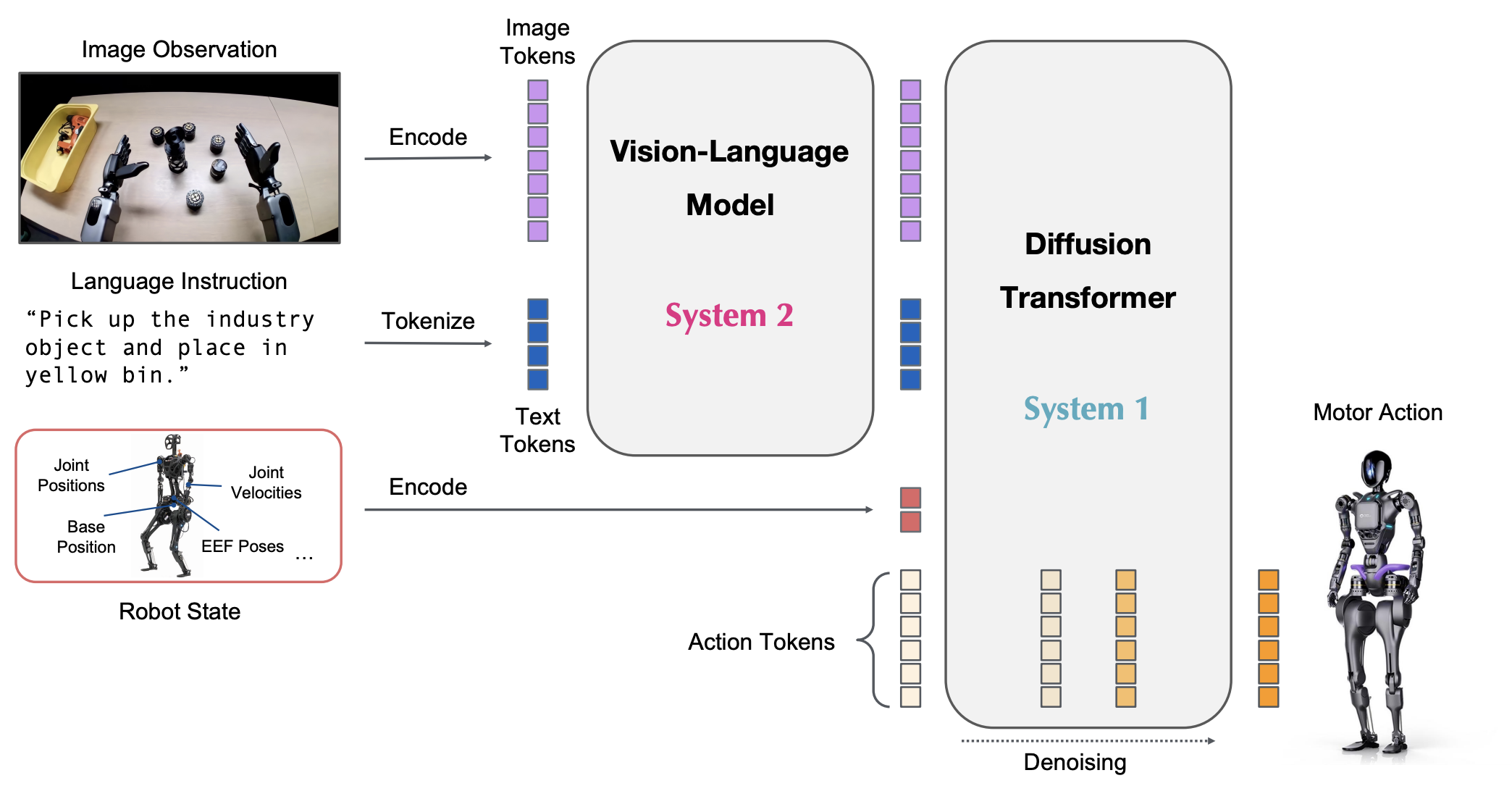
NVIDIA 推出的 GR00T N1 被視為里程碑之一。它採用「雙系統架構」:一個快速反應模組負責即時動作執行,另一個大型語言模型規劃器則負責長期決策與策略制定。這種設計就像是把「小腦」和「大腦」放進同一台機器人裡,讓它既能迅速避開眼前的障礙,也能持續追蹤任務的全局目標。
》延伸閱讀:為人形機器人設計的開放式基礎模型: GR00T N1
另一個典型案例是 OpenVLA。它採取早期融合(early fusion)的方式,利用雙視覺編碼器和 Llama 2 語言模型,直接將圖像訊號與語言向量映射到共享空間。這樣的策略讓模型在遇到「請把綠色書放在書架上方」的指令時,能即時把「綠色」和「上方」轉換為操作性的空間概念,而不是等到後期才做笨拙的轉換。
這些創新共同解決了 VLA 的核心難題:如何讓感知、語言與行動三者真正協同,而不是各自為政。
訓練與效率的挑戰
若說 LLM 靠的是「語料海洋」,那麼 VLA 則必須仰賴「多模態經驗」。這意味著,研究者需要同時蒐集龐大的文字語料、視覺資料,以及機器人的操作軌跡。
在實際操作中,這樣的資料蒐集與標註成本極高。因此,研究社群逐漸轉向 自監督學習與模擬環境生成。機器人不必等到真實世界中執行數百萬次操作,而可以先在虛擬環境裡透過 Sim2Real (Simulation to Reality)技術獲取經驗,再遷移到真實場景。

》延伸閱讀:ReBot: Scaling Robot Learning with Real-to-Sim-to-Real Robotic Video Synthesis
另一方面,模型規模帶來的推理負擔也是難題。為了讓 VLA 能在機器人或自駕車這樣的資源受限裝置上運行,研究者廣泛應用了 LoRA(Low-Rank Adaptation)等高效微調技術,並設計硬體感知的最佳化策略。這些方法讓 VLA 不再是只能依賴雲端的龐然大物,而能成為嵌入式邊緣 AI 的一環,支援即時反應。
實際應用的初步落地
到 2025 年為止,VLA 已經在幾個領域展現驚人的潛力。
在機器人領域,VLA 支援全身控制,讓人形機器人不再只會簡單的「走」與「抓」,而能理解複合任務。例如Helix 這個由 Figure AI 推出的通用 VLA(Vision-Language-Action)模型,專為人形機器人設計。它採用「雙系統架構」:System 2 負責語言理解與場景推理,運行頻率約 7-9 Hz;System 1 則以高達 200 Hz 的速度輸出運動控制指令,確保機器人能即時反應並完成精細動作。這種設計讓 Helix 同時兼具「思考」與「行動」的能力。
Helix 展示了零樣本泛化與跨場景適應的潛力,可僅透過自然語言指令操控機器人處理日常數千種未見過的物件,並能在不同機器人間共享相同權重進行協作。更重要的是,它能在嵌入式 GPU 上獨立運行,脫離雲端依賴,意味著商業落地的可能性大幅提升。
》延伸閱讀:
Helix: A Vision-Language-Action Model for Generalist Humanoid Control
在智慧駕駛,VLA 成為輔助決策的中樞。它能夠結合駕駛者語音指令與車輛感知,協助導航、變換車道,甚至在危險情境中自動接手,提升安全性。
在 Sim2Real 訓練,研究者利用模擬器生成數以千萬計的「經驗片段」,讓 VLA 學會如何搬運、組裝,甚至玩遊戲。這種訓練方式不僅降低了成本,也縮短了模型部署到真實場景的週期。
產業與學術的競逐
在全球 AI 技術版圖中,VLA 正迅速成為兵家必爭之地。
學術界方面,麻省理工學院(MIT)、Stanford、清華等研究團隊不斷推出新的公開數據集與基準測試,試圖推動 VLA 技術朝著更強泛化的方向邁進。
產業界則是另一番激戰。NVIDIA、Google DeepMind、OpenAI,以及特斯拉自駕團隊,都在積極探索如何把 VLA 轉化為實際產品。NVIDIA 在 2024 年的 GTC 大會上,甚至將 VLA 定位為「AI 機器人世代的操作系統」。以下影片為NVIDIA、Stanford University及MIT在今年(2025) CVPR共同發表的CoT-VLA技術。
》延伸閱讀:CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models
未來三到五年的關鍵
展望未來三到五年,VLA 技術的重點將放在更強的跨場景泛化與更普及的即時部署。研究者正致力於讓模型在一次訓練後就能靈活適應家庭、工廠甚至戶外等多變環境,而不必為每一個場景重新調整。同時,隨著硬體加速器進化與軟體優化加速落地,VLA 的運行將不再局限於大型伺服器,而能嵌入到手機、車載電腦或家用機器人中,真正成為智慧生活與智慧工業的核心基礎。

- 【產業觀察】Intel在VLA機器人市場的佈局與契機 - 2026/03/27
- AI如何讓機器人更有「人」味:跨越雙手協同鴻溝! - 2026/03/17
- 2026 Edge AI MCU技術趨勢與廠商方案現況比較 - 2026/03/12
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


