作者:歐敏銓
很多讀者想必對OpenVINO並不陌生,但可能還不熟悉IPEX-LLM,它是英特爾 XPU(Xeon/Core/Flex/Arc/PVC)上的低位元 LLM 開源(Apache 2.0授權)函式庫,具有廣泛的模型支援、低延遲和記憶體佔用小等優勢。IPEX-LLM是Intel為 PyTorch 生態打造的擴充套件,也就是Intel Extension for PyTorch(IPEX) 的子模組,開發者可以使用 IPEX-LLM 運行各種 PyTorch 模型(例如HuggingFace Transformers模型)。
IPEX-LLM支援模型及硬體
在 IPEX-LLM 上已經為70 多個模型進行最佳化,並提供了可立即運行的範例,例如Llama2、Vicuna、ChatGLM、ChatGLM2、Baichuan、MOSS、Falcon、Dolly-v1、 Dolly – v2、StarCoder、Mistral、Redperma等,您可以在此處找到更多模型範例。
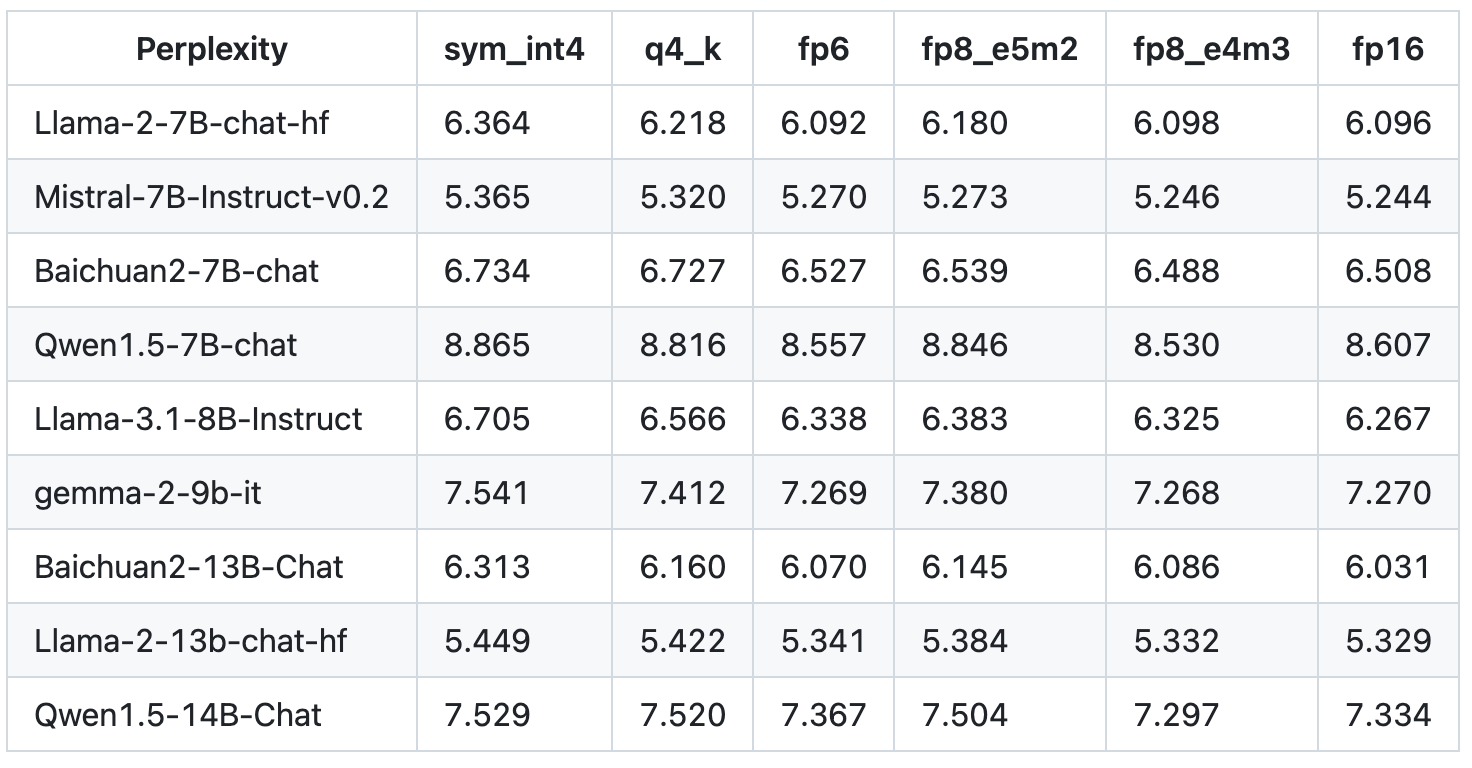
模型量化效能可參考下表:
IPEX-LLM可在Intel Core Ultra iGPU、Intel Core Ultra NPU、single-card Arc GPU或 multi-card Arc GPUs上運行,可參考此圖連結的示範:

下圖顯示運行在Intel Core Ultra處理器上,使用IPEX-LLM涵式庫對6B到13B參數的LLM進行推論的token延遲狀況:

在Intel 12代 Core PC上執行6B模型的實際速度顯示如下:
在Intel 12代 Core PC上執行13B模型的實際速度顯示如下:
IPEX-LLM核心技術
IPEX-LLM之所以能在 CPU 上實現大型語言模型(LLM)的高效推論,關鍵在於其內部整合了多項 Intel 原生的軟硬體加速技術,這些技術共同構築出一個高度優化且易於部署的 LLM 執行環境。
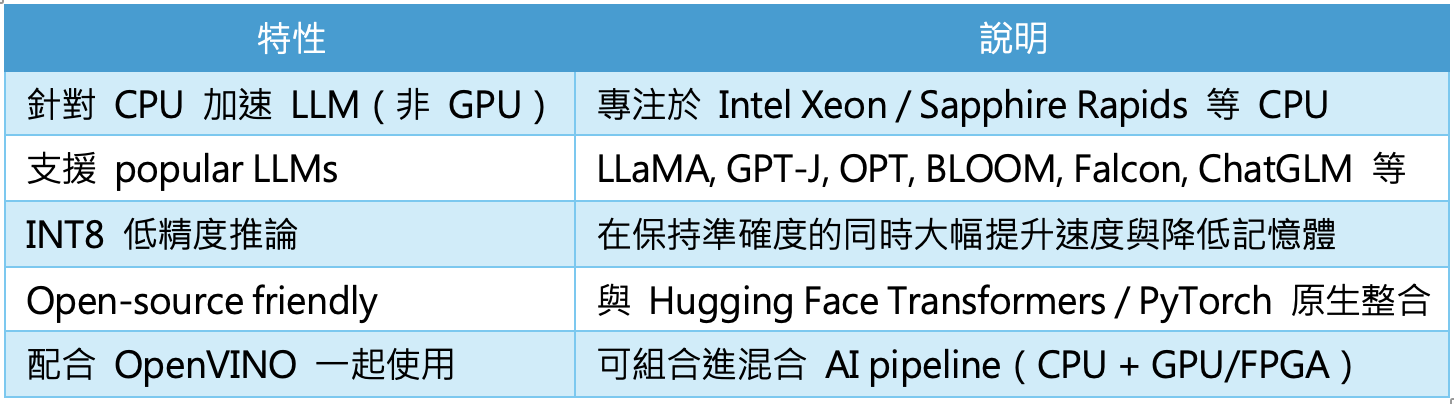
IPEX-LLM支援特性與優點
1. 模型最佳化
首先,IPEX-LLM 提供多種低位元最佳化(例如 INT3/NF3/INT4/NF4/INT5/INT8),透過將模型最佳化(量化),可大幅減少浮點運算與記憶體資源的消耗。尤其在 CPU 上,這種低精度技術帶來顯著效能提升:以 INT8 模式運行模型時,推論速度往往可達到接近兩倍的提升,同時還能有效降低功耗與記憶體使用率,對於邊緣設備或資源受限的伺服器環境尤為重要。
2.部署便利性
部署便利性亦是 IPEX-LLM 的一大優勢。開發者不需要額外進行模型轉換或繁瑣的格式處理,只要在 Hugging Face Transformers 等主流模型庫中,直接載入模型並在使用PyTorch 的代碼中加入一行
進行加速,即可完成低精度轉換與底層加速設定(參考連結):
from ipex_llm import optimize_model
from transformers import LlamaForCausalLM, LlamaTokenizer
model = LlamaForCausalLM.from_pretrained(model_path,...)
# apply ipex-llm low-bit optimization, by default uses INT4
model = optimize_model(model)
...
由於無需進行額外格式轉換或修改模型架構,這大幅降低了進入門檻,讓開發者可快速在低成本 PC(僅 CPU)、具有 GPU 的 PC 或雲端上測試與部署 LLM。
3.其他亮點技術
IPEX-LLM 也深度整合了 Intel 所開發的 oneDNN 函式庫(oneAPI Deep Neural Network Library)。oneDNN 是一套針對深度學習最佳化的運算核心庫,提供經過高度調校的 kernel,能發揮出 Intel Xeon CPU 的最大計算效能,支援主流框架如 PyTorch、TensorFlow,並涵蓋卷積、矩陣乘法、正規化等關鍵運算。
除了核心函式庫的強化,IPEX-LLM 也納入了多種底層系統優化技術,例如 thread affinity(執行緒綁定) 和 graph fusion(運算圖融合)。這些技術可確保模型推論時的計算資源更有效率地分配,同時減少記憶體存取瓶頸,加速整體流程。
最後,memory layout 優化也是整體效能提升不可忽視的一環。IPEX-LLM 可自動根據硬體架構調整張量的記憶體排列方式(如 NCHW 或 NHWC),有效提升資料讀寫效率,進一步縮短推論延遲。
與其他工具的整合
在現代 AI 開發流程中,單一推論工具已難以應對整體部署與整合需求。因此,IPEX-LLM除了自身在 XPU 上的優異效能表現外,也展現出良好的生態系整合能力,可與多種開源工具與 Intel 生態環境協同運作,讓開發者能根據不同場景靈活配置資源。以下將針對幾項常見工具與 IPEX-LLM 的整合方式進行說明。
Hugging Face Transformers:原生支援,直接優化
IPEX-LLM 對 Hugging Face Transformers 提供原生支援,這代表開發者無需修改模型結構或進行格式轉換,只要在 Hugging Face 載入模型後,使用 IPEX 提供的 .optimize() 函數,即可進行低精度加速與底層調校。這種無縫整合讓使用者能在熟悉的開發框架中快速應用 XPU 加速技術,大幅簡化部署流程。
OpenVINO:轉為 IR 模型,擴展至邊緣裝置
雖然 IPEX-LLM 是以 PyTorch 為主體的加速工具,但其所優化的模型可透過 ONNX 匯出,再使用 OpenVINO 工具套件 轉換為 IR(Intermediate Representation)格式,進一步部署於 邊緣裝置或 IoT 平台。這種轉換鏈能將訓練好的模型從開發端延伸至現場應用,實現「雲端開發、邊緣部署」的高效結構。
Intel Gaudi / Habana:CPU + AI 加速協同
對於配備 Intel Gaudi(Habana)AI 加速器的系統,IPEX-LLM 同樣可以發揮作用。在這種架構中,CPU(透過 IPEX)與 Habana GPU 可協同分擔推論任務:CPU 可處理 tokenization、資料前處理、控制流等,GPU 負責主體矩陣運算,實現更平衡的運算負載與功耗管理。這種異質協同設計,特別適合訓練/推論一體化的場景。
n8n、Apache Airflow:整合工作流自動化
在企業環境中,模型推論往往不是單一步驟,而是嵌入在整個任務流程中。IPEX-LLM 可透過 Python 腳本形式包裝,輕鬆整合進如 n8n 或 Apache Airflow 等自動化工作流工具。例如,可在新資料進入後自動觸發一段使用 IPEX-LLM 的文字生成任務,或根據輸出結果進行自動分類與通知,實現真正的 AI+流程自動化整合。(延伸閱讀)
小結
綜上所述,IPEX-LLM 不僅是一個優化 PyTorch 模型的加速工具,更是一個可與整個 AI 工具鏈靈活整合的核心元件。對於想在雲端、邊緣,還是融入企業內部的流程平台的開發者來說,IPEX-LLM提供了一條可加快部署、成本可控且資料安全的實踐路徑。
》延伸閱讀:
Accelerate Large Language Model (LLM) Inference on Your Local PC

- AI如何讓機器人更有「人」味:跨越雙手協同鴻溝! - 2026/03/17
- 2026 Edge AI MCU技術趨勢與廠商方案現況比較 - 2026/03/12
- 大自然的逆向工程:Festo用20年打造的仿生螞蟻、蜜蜂與水母 - 2026/03/10
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!