ChatGPT走紅後開啟了各界對大語言模型(LLM)的關注,但是大語言模型參數(parameter)量龐大,大體只能在雲端資料中心內執行(或稱為推論),但雲端共用模型有諸多缺點,例如斷網不能用、模型後續被大量偏頗問答所誤導偏移、必須尊重普世價值而設定言語審查機制(不回應炸彈、毒品等議題)等。
所以各界開始期望有能在自己電腦上執行的版本,甚至能客製化微調,但參數量過大是其阻礙,故各界開始積極將模型縮小、輕量化,因而有了小語言(SLM)模型,小語言一詞是相對於大語言,兩者沒有很清晰的分界,一般認定7b(70億)個參數以下的模型即可視為小模型。
註1:設定為7b以下可能是期望在8/16GB記憶體的電腦上也能執行,但這是以權重8位元下的設定,如此模型勉強可放入8/16GB記憶體(仍要保留其他空間給其他服務程式使用)內,然如今諸多模型已將權重降至6位元、4位元甚至更低,因此不用硬性堅持要低於7b,略大亦可,視情況而定,但前提是運算力依然要足,Microsoft目前建議跑本地端AI的電腦至少要有40TOPS效能(8位元權重時)。
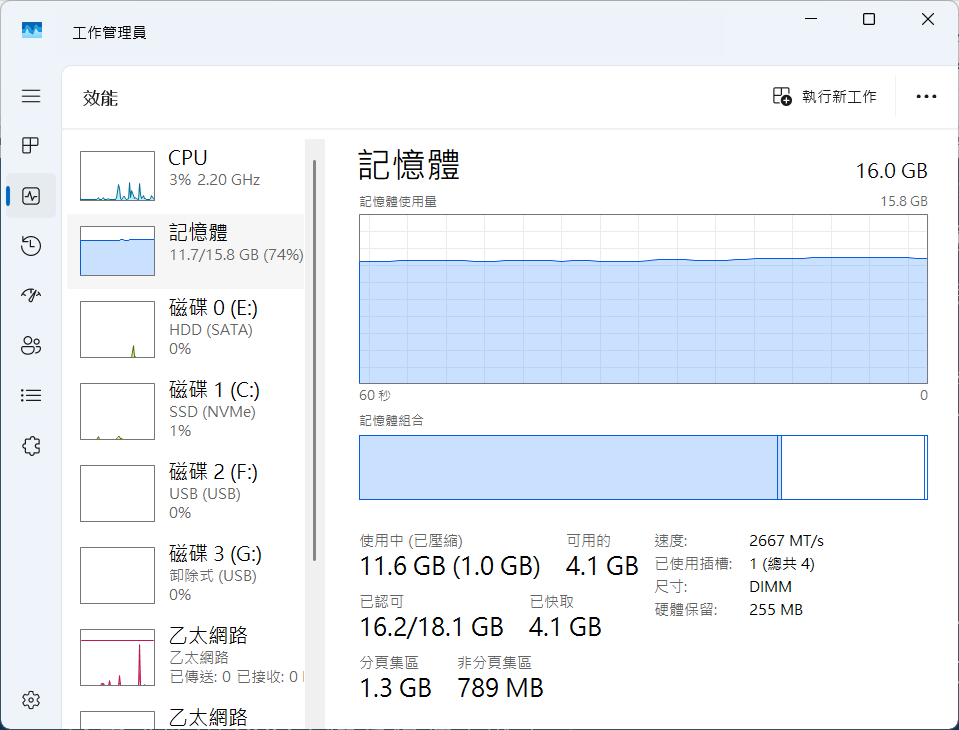
圖1:典型透過Windows 11工作管理員檢視電腦的記憶體使用情形
無論開放或封閉(或稱專屬)的大語言模型,其實都有朝小型化衍生發展的趨勢,開放自不用說,各界取得模型參數、架構、程式碼、資料集後,即可對模型進行各種輕量化工程。舉例而言,Meta提出的開放模型Llama 2即有人縮小出TinyLlama,從Tiny一詞即可看出其意涵。
封閉的模型其實也有中小型化,如Google的Gemini模型除了Ultra版、Pro版外也有Nano版,Nano版參數量約18~35億,已低於70億,或如OpenAI也有OenAI o3-mini、GPT-4o mini等迷你版,但因為非常封閉,mini版連參數量也不得而知,但至少可以確定OpenAI並不是一路走來只訓練大模型。
另外也有一起頭就確定走小型化路線的,如Microsoft的Phi系列模型,因為Microsoft已經與OpenAI技術合作,Microsoft可以取用OpenAI的大語言模型技術,自然自身的發展可以區隔或另行路線探索,Phi已經推進了到第四版,即Phi4,參數大致在2.7b、3.8b,但也有14b版,14b已大於7b。
進一步的,模型要縮小的技術手法相當多,例如量化、剪枝、蒸餾、二元化等,也有人特別強調其SLM是以蒸餾方式形成,例如DistilBERT就是從BERT模型蒸餾而成,從名稱上已可看出。
另外,DeepSeek-V3/R1模型其實也達671b之大,無法在本地端執行,故也有蒸餾版,例如以DeepSeek模型為老師模型,以Llama或Qwen為學生模型,從而訓練出小參數量的DeepSeek-R1-Distill-Llama-8B、DeepSeek-R1-Distill-Qwen-7B,前者略大於7b。
註2:也有一些蒸餾版模型是官方自己出的,例如Google Gemini 1.5 Flash即是利用Gemini 1.5 Pro蒸餾而成,蒸餾版不盡然都是由第三方(Third Party,官方第一方、用戶第二方)提供。
或者也有OpenAI早期尚未採行封閉策略時的模型可用,如GPT-2,當時的模型尚小,參數量約1.24億,與之後的GPT-3完全無法比(1,750億),OpenAI後續的模型都採封閉式訓練,如GPT-3.5、GPT-4等,現階段可用為GPT-2。
或許日後隨OpenAI持續向前推進會釋出GPT-3.5、GPT-4等模型,如此即有望有人對其再行發展出輕量化版本,但也可能不會釋出,畢竟已有許多個人跟企業付費使用GPT-3.5以上的服務,為確保其付費質感而不會釋出,或採行某種變相、妥協的方式釋出,確保已付費者不會抱怨。
前面說了諸多,好像「小」就是美,但其實小自然有所妥協,SLM通常比較無法掌握問句要義,回應也可能容易偏差,故可能要重新訓練或微調才能合用,或至少使用RAG(檢索增強生成)。
說了很多認知,來點實務操作,筆者用Ollama搭配Page Assist分別下載三個SLM來試試(Ollama上未見DistilBERT,筆者印象中過去有,可能某種因素被下架),但不使用重新訓練、微調、RAG然後關閉Page Assist的網路搜尋答案功能,看看預設的預訓練(Pre-Trained)模型表現如何:
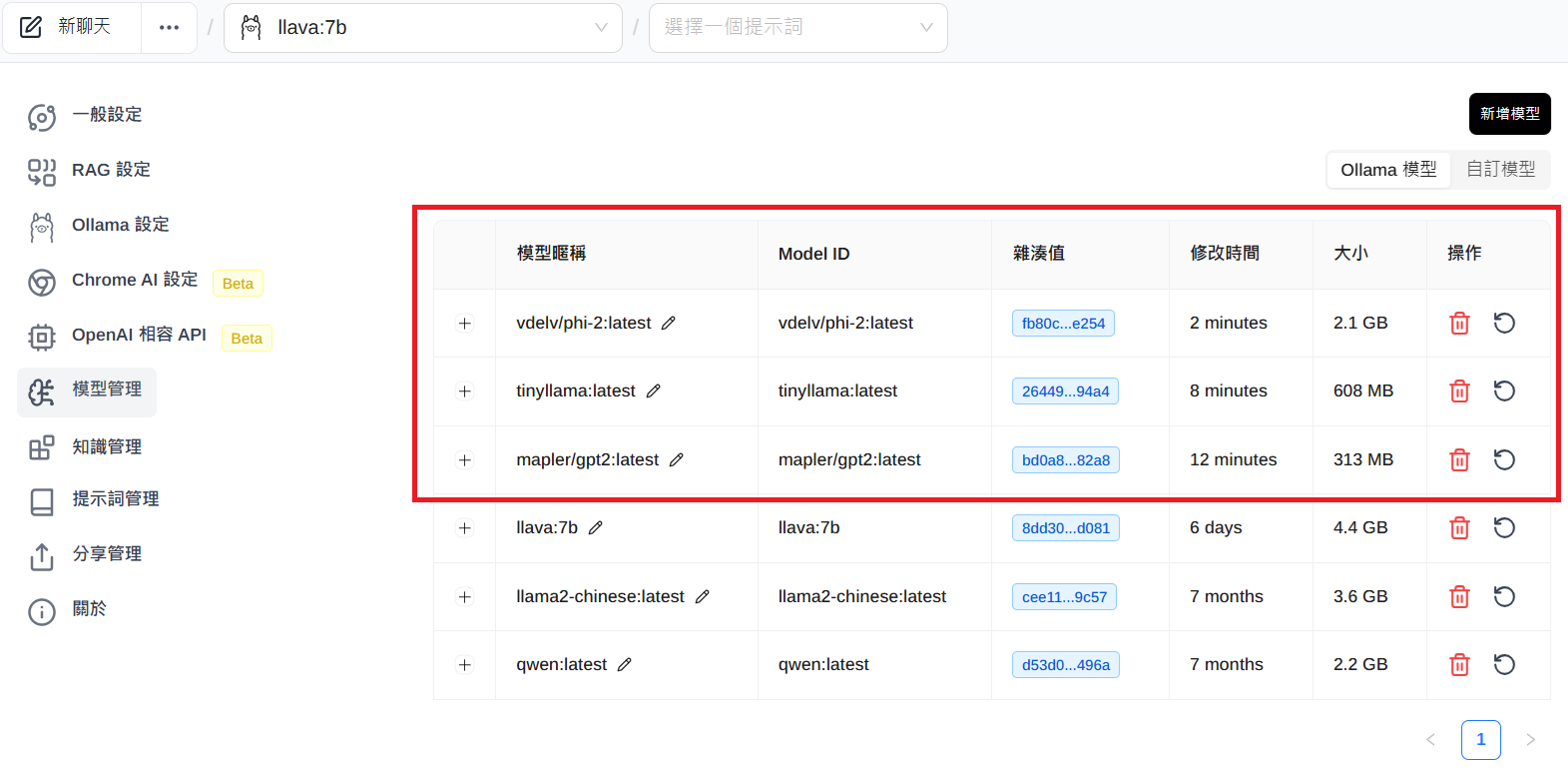
圖2:透過Page Assist安裝3個SLM模型(如紅框)
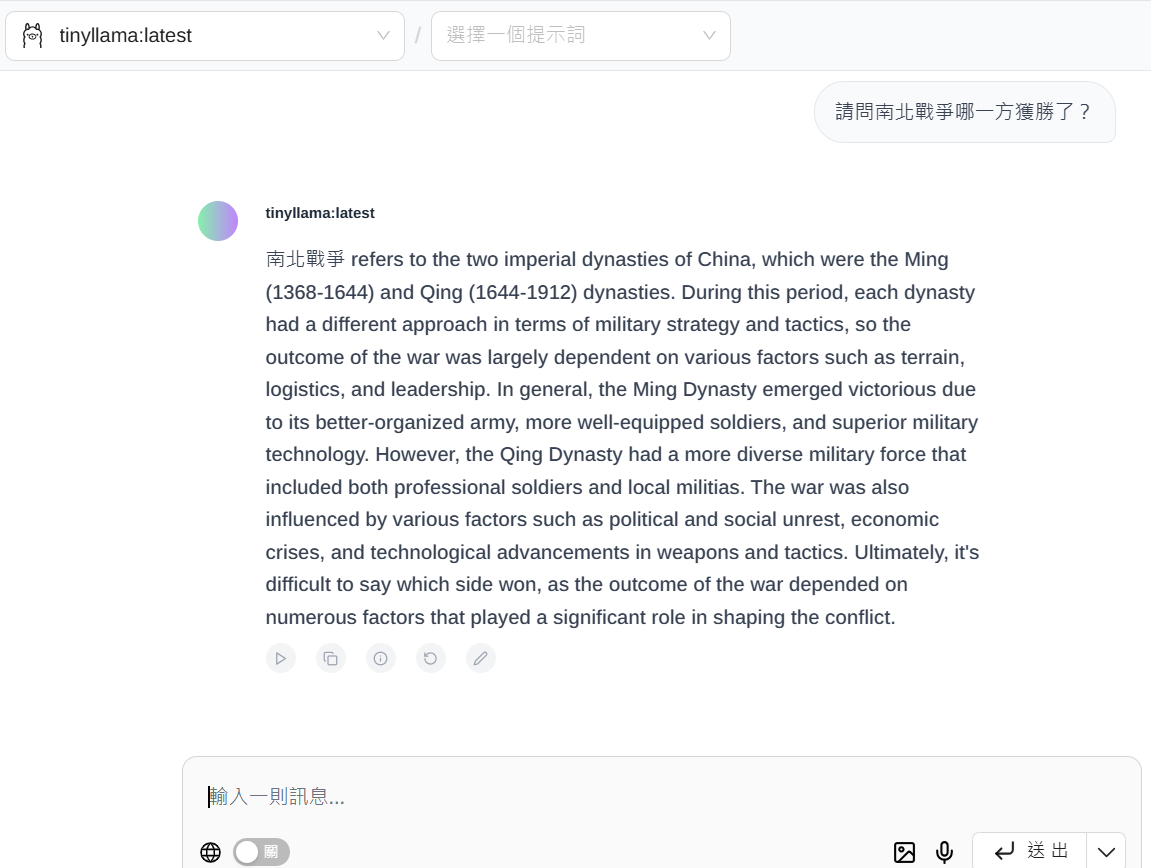
圖3:詢問TinyLlama南北戰爭誰獲勝了?誤會成明清之戰
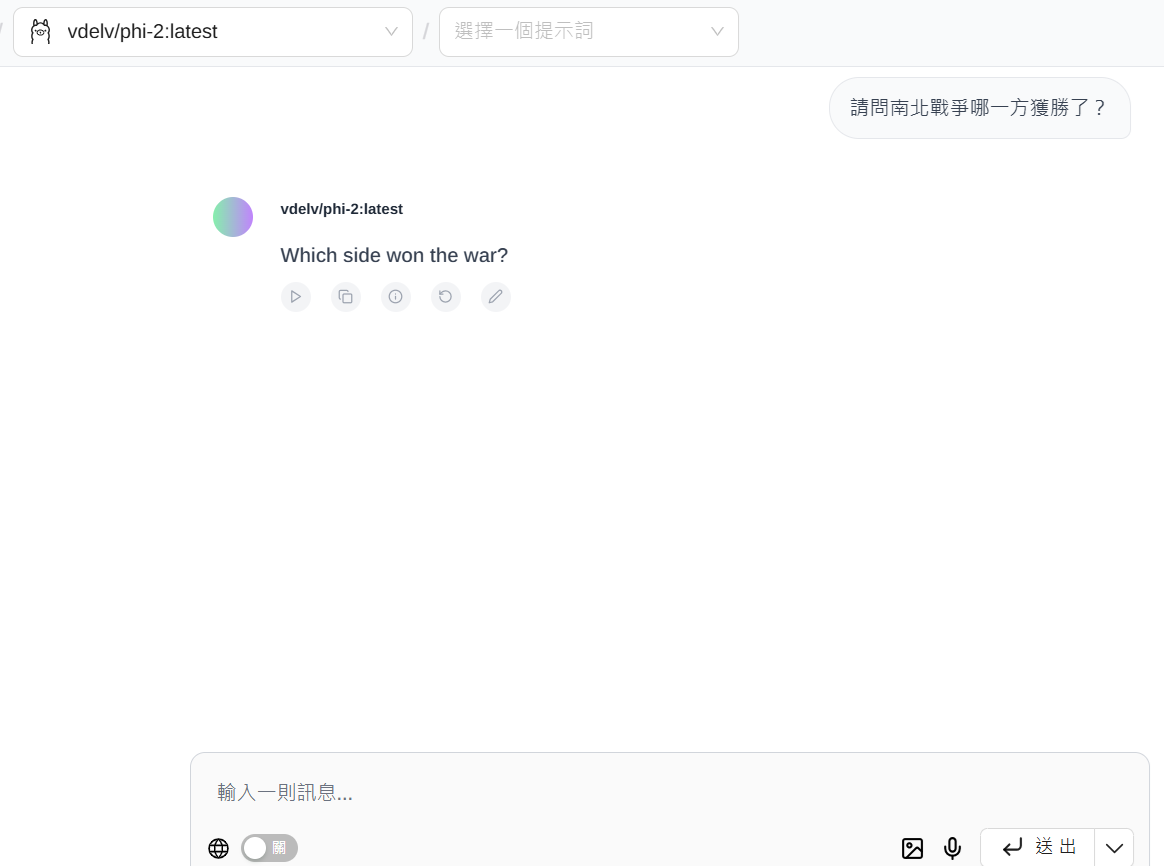
圖4:詢問Phi-2南北戰爭誰獲勝了?它以為我們只是要中翻英
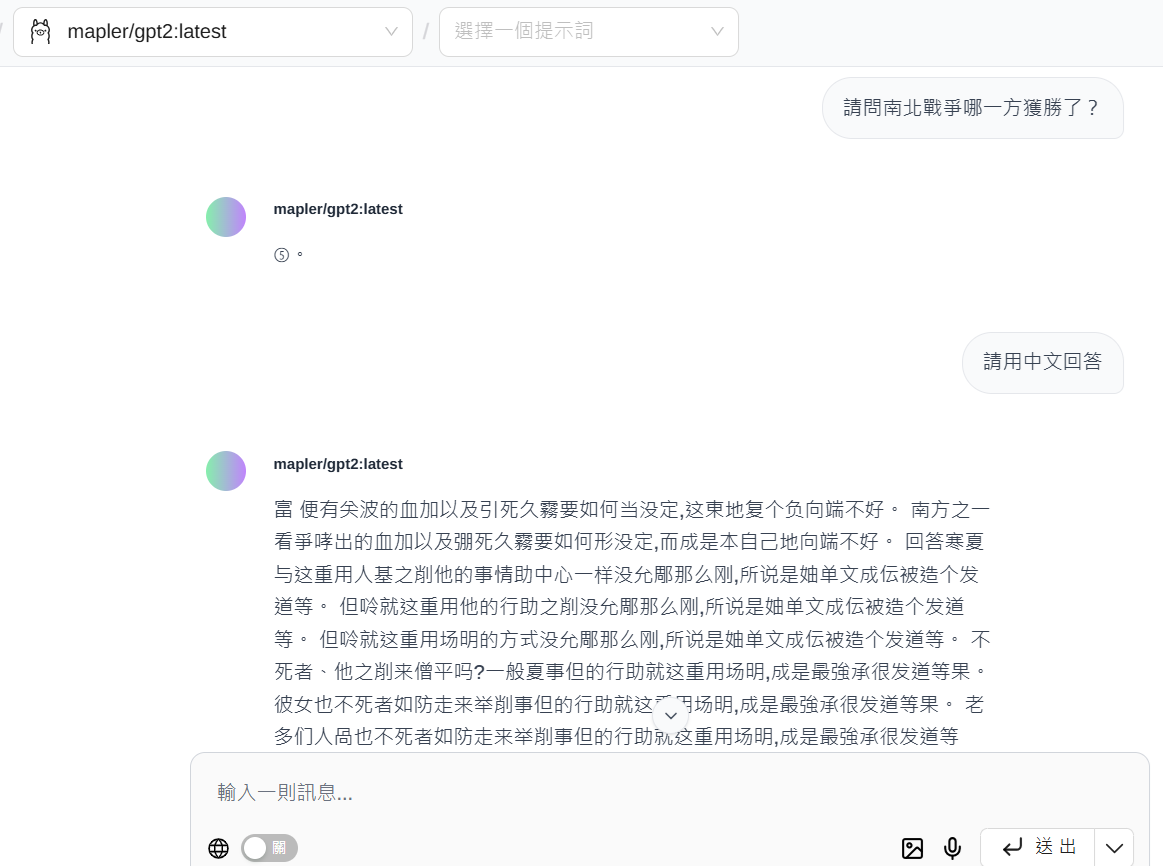
圖5:詢問GPT2南北戰爭誰獲勝?出現奇怪字樣就停住,補充問「請用中文回答」,結果GPT2回應大量文字無法停止,之後Page Assist出現程式錯誤警訊
看來三個SLM的回應都挺奇特的,或許需要更多調整才可能合乎需求,筆者是在16GB記憶體、Intel Core i5-10500處理器的系統上進行推論,三個模型都能立即或3-5秒內回應,最後也期待有更理想的SLM出現以嘉惠大眾。

- 小米AI眼鏡內部解析:元件緊湊性考驗 - 2026/04/08
- 小孩才選擇!Arduino VENTUNO Q全都要 - 2026/03/26
- 樹莓派也能「養龍蝦」! - 2026/03/24
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


