在我們的生活中,除了語言文字,影像資訊也是一個隨處可得的資訊,是不是也能透過RAG來獲得檢索體驗的強化呢?這門Visual RAG的學問已被視為是下一代AI進步的關鍵,本文介紹它的技術架構與應用案例。
大型語言模型(LLM)與檢索增強生成(RAG)之間的結合,是目前AI技術落地的一門顯學,當開發者將兩者的優勢充分整合後,能有效提升自然語言處理和訊息檢索任務的性能與體驗。也就是透過RAG的檢索機制,LLM能夠獲得更多的上下文訊息和知識支持,從而生成更準確、更豐富的內容。
然而,在我們的生活中,除了語言文字,影像資訊也是一個隨處可得的資訊,是不是也能透過RAG來獲得檢索體驗的強化呢?這門Visual RAG的學問已被視為是下一代AI進步的關鍵,本文介紹它的技術架構與應用案例。
何謂RAG?
先來複習一下RAG。在傳統的AIGC模型中,模型主要依賴於內部知識進行內容生成,這可能導致生成結果缺乏準確性或不夠豐富。透過RAG則可引入外部知識庫,利用檢索過程獲取與當前任務相關的信息,從而有效提高生成內容的質量。
RAG的工作原理分為三個主要步驟:檢索(Retrieval)、增強(Augmentation)和生成(Generation)。在檢索階段,系統會根據輸入的查詢內容從外部知識庫中檢索出相關信息,這些信息可以是文本、圖像或其他類型的數據;然後使用檢索到的信息來增強或增強模型的輸入;接下來,在生成階段,系統會將檢索到的內容與原始輸入結合,通過生成模型生成最終的輸出。請參考下圖。
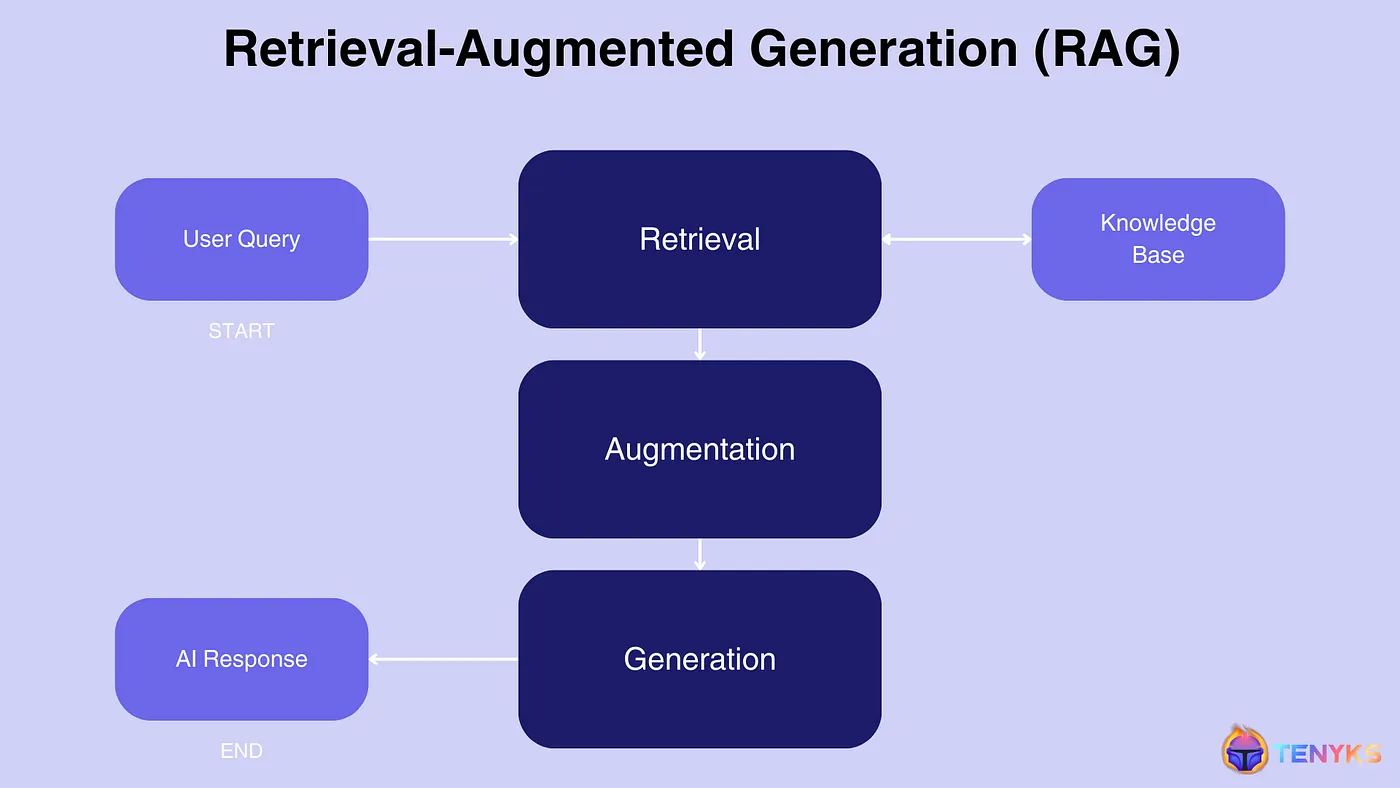
RAG 的三個建構模組:檢索、增強和生成(Source)
這種方法的優勢在於它能夠靈活地融合來自不同來源的信息,使得生成的內容更具上下文意義和信息豐富性。此外,RAG還能夠在面對不確定性或稀缺信息時,通過檢索相關內容來彌補生成模型的不足。
簡單的說,透過RAG可以讓企業客製化屬於自己的LLM應用與服務,例如打造LLM-based CRM、Call Center、員工訓練等,因此相當受到各行業的重視。
Visual RAG:在電腦視覺中的應用
Visual RAG即是將RAG的概念應用於電腦視覺(Computer Vision, CV)領域,這一領域傳統上主要專注於圖像和視訊的分析與處理,隨著AI深度學習技術的進步,電腦視覺在許多應用中取得了顯著的成功,如圖像分類(Image Classification)、物件偵測(Object Detection)和圖像分割(Image Segmentation)等。然而,這些技術仍然面臨著一些挑戰,特別是在需要生成語言描述或理解複雜場景的情況下。
以圖像描述生成為例,傳統方法通常依賴於訓練好的模型來生成與圖像內容相關的文本描述,但這些模型可能無法準確捕捉圖像的細節或上下文。Visual RAG通過引入檢索機制,能夠檢索與圖像內容相關的描述或信息,從而生成更準確的描述。例如,當系統接收到一張狗在公園裡玩的圖像時,視覺RAG可以檢索到類似場景的文本描述,並根據檢索結果生成「這是一隻在陽光下奔跑的狗」的描述。
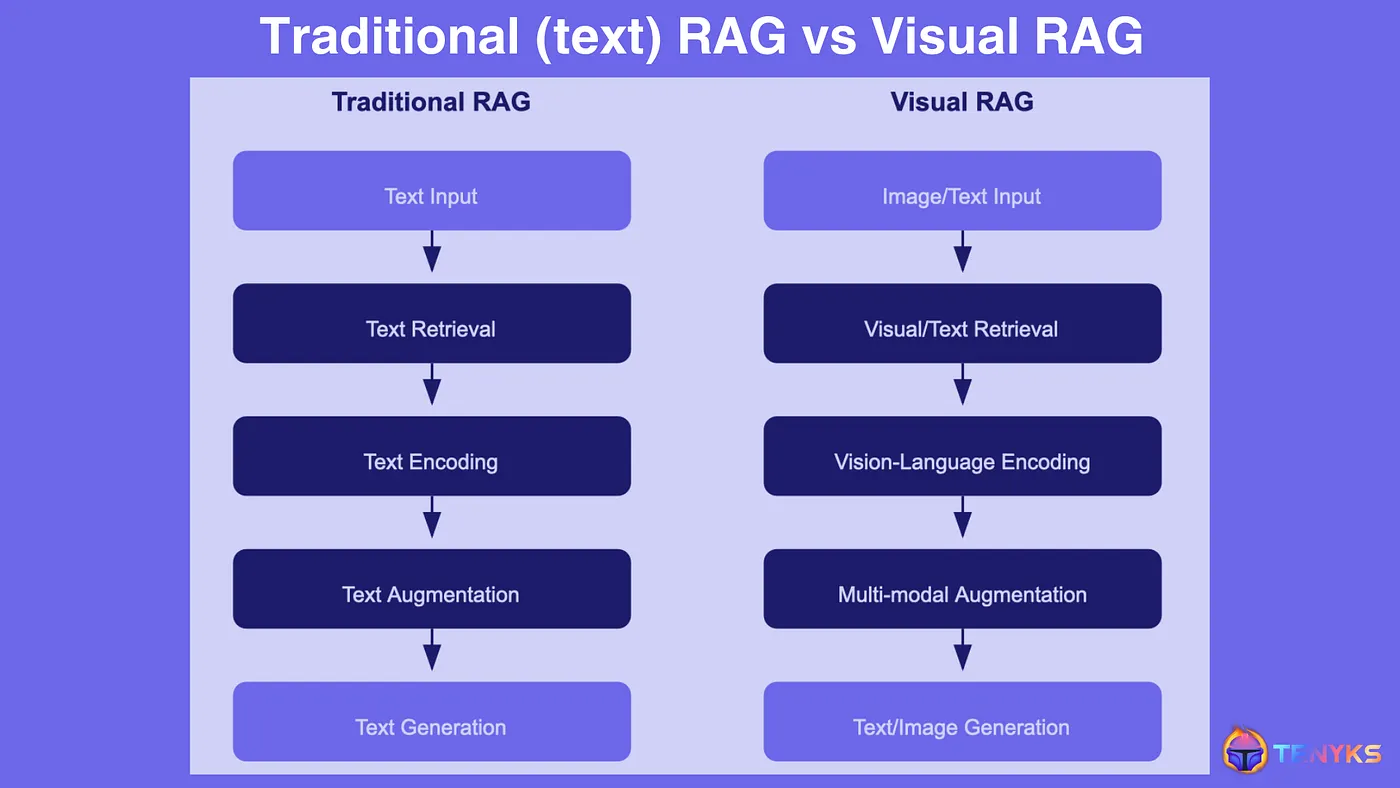
傳統Text-based RAG 與Visual RAG 的比較(Source)
Visual RAG的應用不僅限於圖像描述生成,還可以用於其他許多電腦視覺任務,如視訊分析、場景理解和視覺問答等。通過結合檢索與生成,Visual RAG能夠在更廣泛的場景中提供強大的解決方案。
多模態RAG的崛起
隨著技術的發展,單一模態的處理已經無法滿足當前的需求。多模態RAG(Multimodal RAG)應運而生,它將RAG的應用擴展到不同類型的數據中,如文本、圖像、音訊和視訊等。這一技術的核心在於其能夠同時處理和理解來自多個模態的信息,從而實現更全面的分析和生成。
在多模態RAG中,系統能夠從多個數據來源中檢索信息,並在生成時考慮不同模態之間的關聯性。例如,在一個視訊分析任務中,系統可以同時分析視訊流中的視覺信息和配音中的語音信息,從而更準確地理解視訊內容。這種整合能夠提升對場景的全面理解,使得多模態RAG在許多應用場景中表現優異。
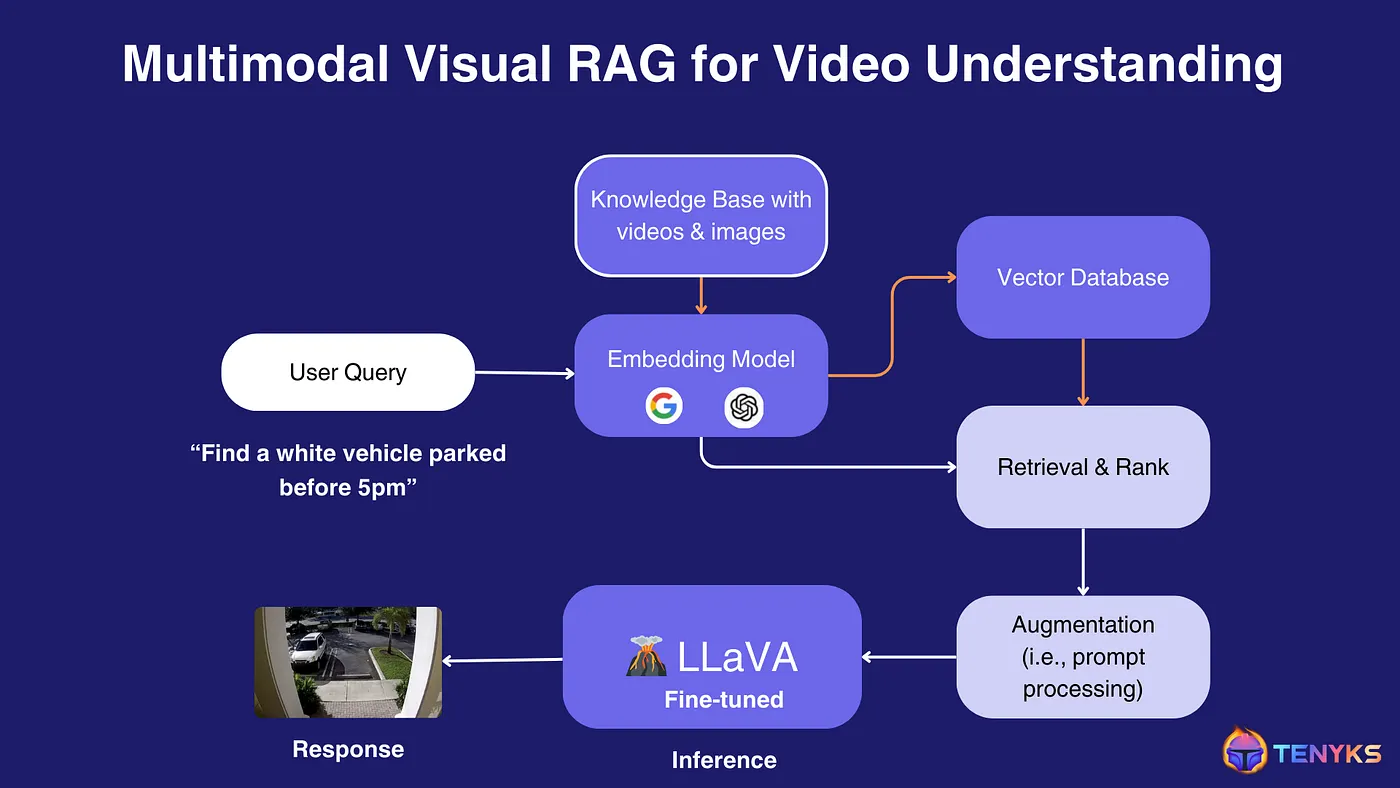
應用於視訊理解系統的多模態Visual RAG運作架構(Source)
對照上圖來分解一下多模態Visual RAG系統元件及其交互作用:
- 知識庫:系統從包含影片和圖像的知識庫開始。這是理解視覺內容的基礎。
- 嵌入模型:嵌入模型,例如CLIP(對比語言-圖像預訓練),用於將知識庫內容和使用者查詢轉換到公共向量空間。這允許在不同模式(文字和視覺數據)之間進行比較。
- 向量資料庫:知識庫的嵌入表示儲存在向量資料庫中,從而實現高效的相似性搜尋。
- 使用者查詢:使用者輸入查詢,例如「尋找下午5點之前停放的白色車輛」。
- 查詢處理:使用者的查詢透過嵌入模型,將其轉換為與知識庫內容相同的向量空間。
- 檢索和排名:系統根據查詢嵌入和儲存的嵌入之間的相似性從向量資料庫中檢索相關資訊。然後,它會對結果進行排名,以找到最相關的匹配項。
- 增強:檢索到的信息經過及時處理或增強,以細化上下文並為語言視覺模型做好準備。
- LLaVA 微調: LLaVA(大語言和視覺助理)的微調版本處理增強訊息。 LLaVA 是一種能夠理解文字和視覺輸入的多模式模型。
- 推理: LLaVA 模型對處理後的資料進行推理,以產生解決使用者查詢的回應。
- 回應:最終輸出是視覺回應,在本例中,影像顯示一輛白色汽車停在街道上,與使用者的查詢相符。
多模態RAG的實際應用案例
在許多實際應用中,多模態RAG的潛力已經得到了充分的展示。以下是幾個值得注意的案例:
- 智慧監控系統:在智慧監控中,系統需要同時處理視訊流和環境聲音。多模態RAG可以檢索與特定事件相關的歷史視訊和音訊信息,幫助系統更準確地識別可疑活動。例如,當監控系統檢測到異常行為時,它可以通過檢索過去類似事件的視訊片段和音訊記錄來進行分析,從而提高事件的準確性。
- 虛擬助手:在虛擬助手的應用中,系統需要理解用戶的語音命令並根據其上下文提供適當的回應。多模態RAG可以檢索用戶過去的對話記錄和相關信息,以生成更具針對性的回應。例如,當用戶詢問「今天的天氣怎麼樣?」時,系統可以檢索先前的天氣數據和用戶的喜好,從而提供個性化的天氣預報。
- 醫療影像分析:在醫療影像分析中,專家需要根據影像資料做出診斷。多模態RAG可以檢索相關的醫療文獻和歷史病例,幫助醫生在分析影像時獲得更多背景訊息。例如,當醫生分析一幅CT圖像時,系統可以檢索到類似病例的診斷報告和治療方案,輔助醫生做出更準確的診斷。
Visual RAG技術的未來展望
隨著RAG技術的持續發展,我們可以期待它在電腦視覺和多模態系統中的應用將會越來越廣泛。未來的研究將集中在以下幾個方面:
- 模型的即時性能:隨著應用場景的多樣化,系統的即時性能變得愈加重要。未來的RAG模型需要在檢索和生成過程中提升效率,確保能夠在即時環境中運行。
- 處理更複雜的多模態數據:隨著多模態數據的增加,系統需要具備處理更複雜和多樣化數據的能力。這將涉及到更強大的檢索算法和生成模型,以應對不同模態之間的挑戰。
- 增強系統的自適應能力:在多變的環境中,系統需要具備自適應的能力,以便根據新的數據和信息進行調整。未來的RAG系統將需要結合機器學習和深度學習技術,以不斷提升其性能。
(參考資料:RAG for Vision: Building Multimodal Computer Vision Systems)

- NVIDIA與全球機器人生態系推動具生產規模的實體AI - 2026/03/27
- 從VLA到落地部署:拆解新世代機器人開發關鍵路徑 - 2026/03/24
- 【Podcast】分散式代理時代:2026 Edge AI 技術全解析 - 2026/03/24
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


