作者:陸向陽
最近知名創客Alasdair Allan發表一篇專文,談及他在Edge AI、TinyML領域的新實測發現:
- 在使用相同的TensorFlow模型下,第五代樹莓派RPi 5的推論速度幾乎是上一代RPi 4的5倍。
- 在使用相同的TensorFlow模型下,使用Google Edge TPU加速晶片還是非常快,但若把模型改成TensorFlow Lite的瘦身輕量版,則單純用RPi 5就有機會跟Edge TPU速度相近,只略慢一點。
推論成效
所謂的相同模型是用MobileNet v1(0.75深度)與v2,訓練的資料集是COCO(Common Objects in Context),訓練時輸入的照片解析度為300 x 300。Alasdair Allan同時拿了三代的樹莓派進行測試,並測試完成推論的時間(縱軸,單位毫秒,mS),時間愈短愈好:
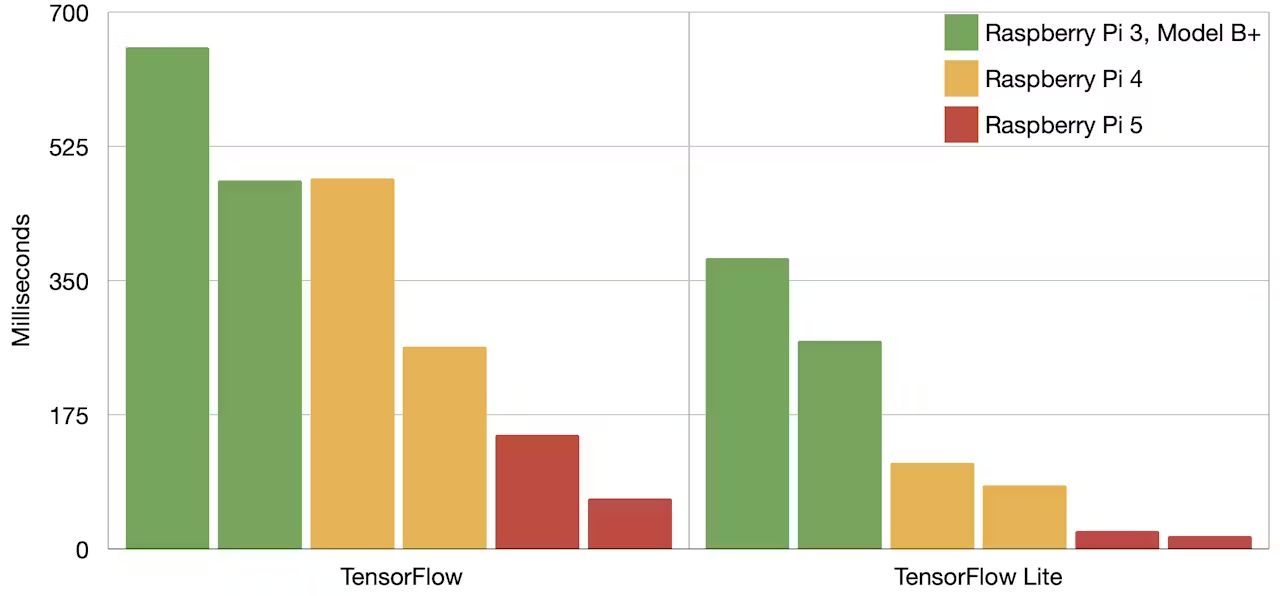
圖1 三代樹莓派跑TensorFlow、TensorFlow Lite模型的推論速度比較,左邊組為MobileNet v2,右邊為v1(圖片來源:Alasdair Allan)
然後,給RPi加裝上Google的Coral Dev Board開發板,運用板子上的Google Edge TPU晶片來加速,該晶片在2018年推出時在8位元整數推論下有傲人的推論效能(4TOPS,且省電,強調每瓦達2TOPS),若用於前述的模型推論,MobileNet v1只要15.7mS就能完成,v2也只要20.9mS。
對此,只要同樣是用正規TensorFlow模型,無論第三、四、五代樹莓派,在沒有加速器晶片下,都要上百毫秒才能完成推論,但如果是用RPi 5,同時搭配TensorFlow Lite將模型進行輕量化,則可以有逼近Edge TPU的推論表現,MobileNet v1可以到16.9mS,v2也有23.5mS。
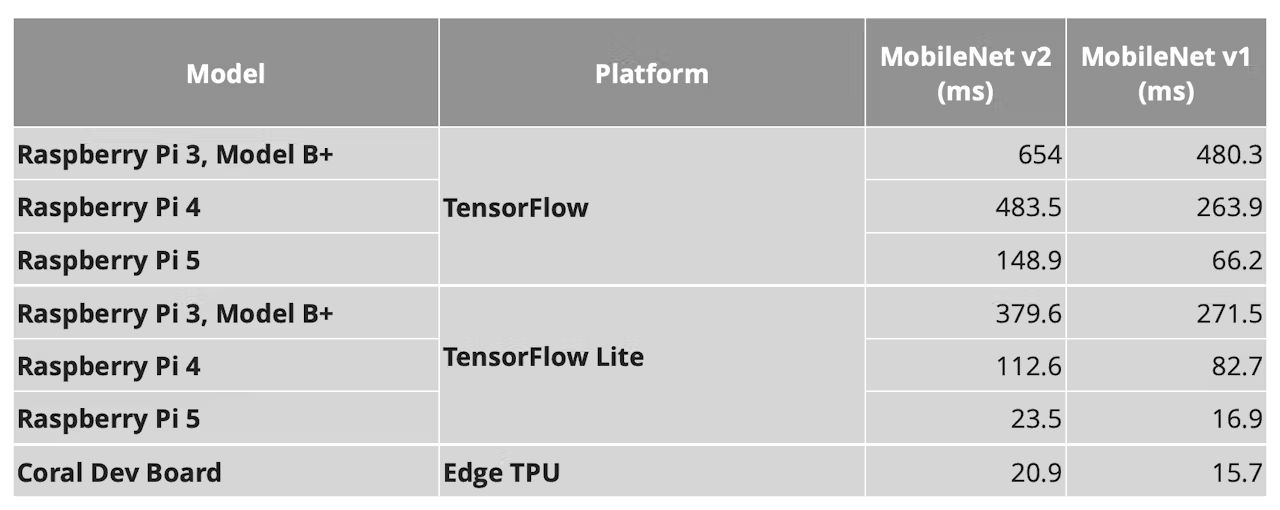
圖2第五代樹莓派搭配TensorFlow Lite,推論效能直逼Coral Dev Board,以數字進行比較(圖片來源:Alasdair Allan)
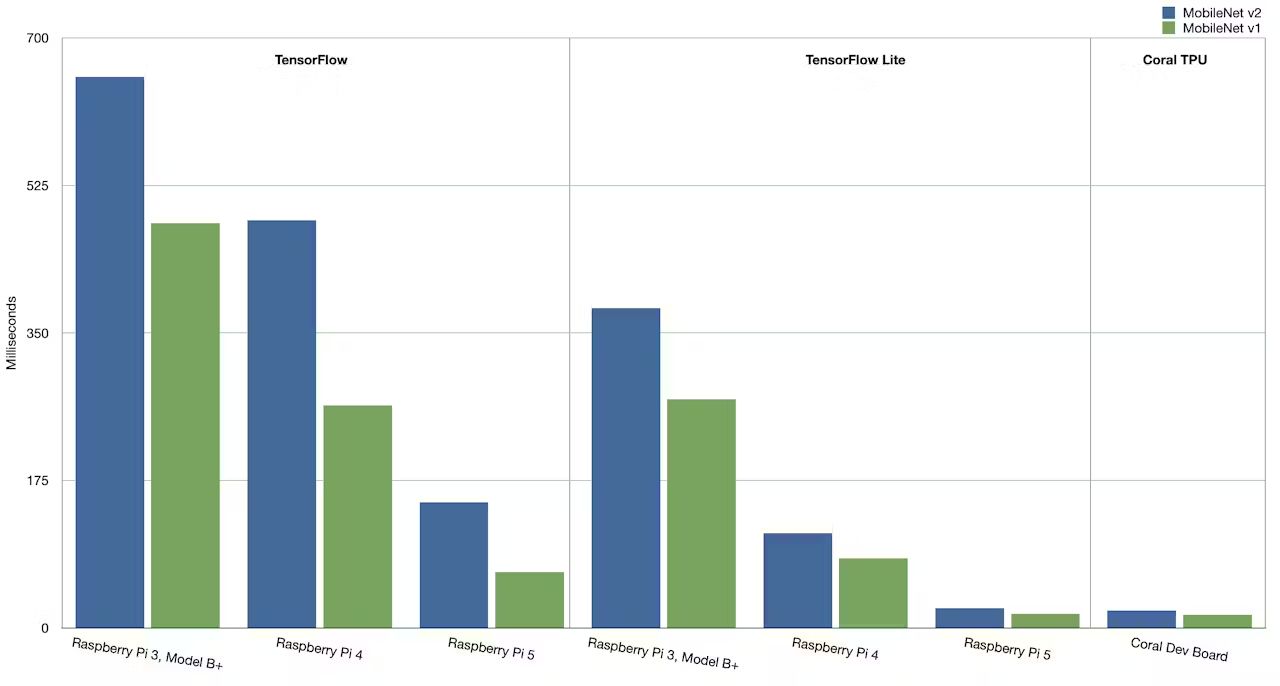
圖3 第五代樹莓派搭配TensorFlow Lite,推論效能直逼Coral Dev Board,以長條圖進行比較(圖片來源:Alasdair Allan)
要補充說明的是,RPi 5有使用電動風扇散熱,這幾乎是RPi 5的標準配備,但RPi 3、4則採被動散熱。另外,雖然RPi主控晶片內也有GPU電路,有機會用於AI加速,但此次測試全然使用CPU電路。
雖然Edge TPU還是最快,但畢竟是2018年的產品,這段期間AI軟硬體都在進步,2017年即有從TensorFlow衍生出的TensorFlow Lite並持續精進改版,2023年則有RPi 5,兩者相搭配已接近Edge TPU的表現。
同時Edge TPU也有些隱憂,一是2021年Google便不再更新pycoral函式庫,另一是pycoral函式庫無法適用新版Python,如此要在新的作業系統上使用Edge TPU就有相容性的困擾。
至於15mS、20mS是否強悍?或許可以加入更多軟硬體搭組來比較,Alasdair Allan拿了Intel Movidius NCS(Neural Compute Stick)、Intel NCS2以及NVIDIA Jetson Nano來比,Intel方面搭配的軟體為OpenVINO,NVIDIA則是搭配正規TensorFlow外也搭配NVIDIA最佳化的TensorRT,至於Coral則使用TensorFlow Lite,為了讓Coral可以用TensorFlow Lite還得額外進行一些程序,包含要將模型轉換成FlatBuffer格式、模型重新編譯等。
至於測試模型還是MobileNet v1、v2,一樣是把圖片變成300 x 300解析度後才給模型,測試的模型主要是用來識別照片中是否有香蕉或蘋果,然後推論時間是跑過10,000次測試後取平均值而得。如此得到結果:
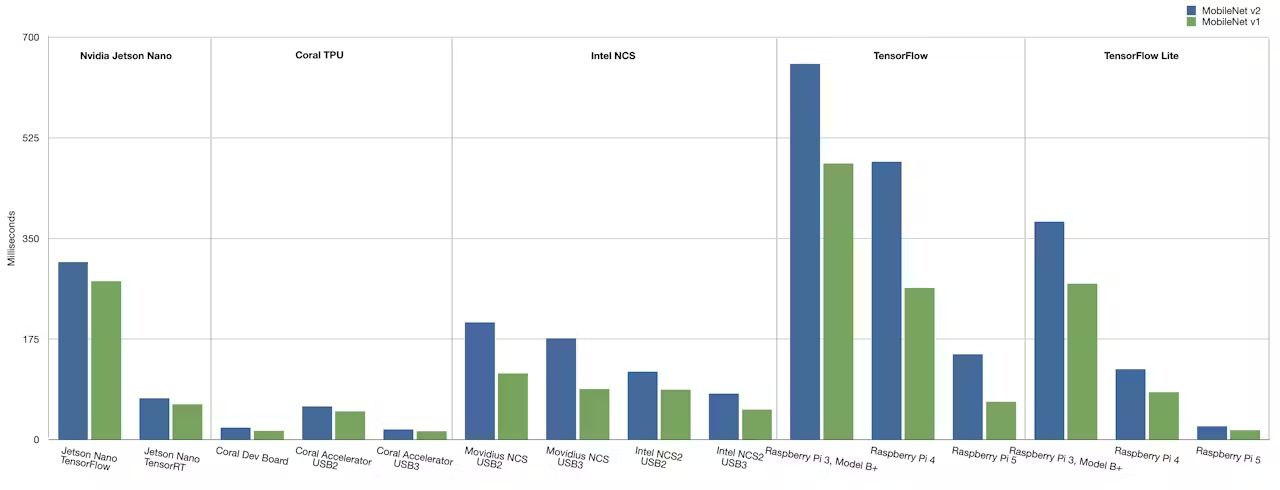
圖4 NVIDIA Jetson Nano、Coral Dev Board、Intel NCS2、RPi 5推論速度比較(圖片來源:Alasdair Allan)
由測試結果可知,Coral(Google Edge TPU)跟RPi 5在與TensorFlow Lite搭配下確實很強猛,然後NVIDIA Jetson Nano必須使用自家的TensorRT才顯現強猛,至於Intel則必須是新一代的NCS2且採行USB 3介面傳輸才顯現強猛。
另外Coral自身也是以USB 3的硬體配置比較強猛,好過USB 2介面的版本,但與使用PCI Express(PCIe)介面的Coral Dev Board差不多,Intel也是以USB 3介面版可以快過USB 2,無論是Intel Movidius NCS或NCS2都是如此,看來USB 2.0確實是推論效能瓶頸所在。
小結
即便經過最佳化搭組,NVIDIA與Intel方案的推論速度還是略慢於Coral組合或RPi 5組合,但大體都已在100mS之內。此外,即便不倚賴TensorFlow Lite,回到正統TensorFlow的基準條件下,RPi 5的表現也已經優於Intel Movidius NCS,甚至能與USB 2介面的Intel NCS2拼鬥,不過NCS2也已是2018年發表的產品,Jetson Nano則是2019年發表,2023年的RPi 5打贏6、7年前的硬體實在勝之不武,更何況第一代NCS時間更早,約在2016年。
更重要的是,RPi 5幾乎得使用風扇,但Coral方案不用、Intel NCS2也不用,NVIDIA Jetson Nano也只使用大體積的被動散熱片。
在價格方面Coral Dev Board約129美元,USB介面型約59美元,Jetson Nano約99美元(但這是1,000片批發價),Intel NCS2在RICELEE網站上最終資訊為3,800台幣。其他比較也包含容積、功耗等。
最後必須說競爭其實是多元且動態的,或許喚醒RPi 5的GPU會有更強的效果,又或許TensorRT改版後也會有不同的結果,或者Intel、NVIDIA、Google很快也推出新品回敬對手等,時間切片的勝負只是一時,後續發展更讓人期待。
(責任編輯:謝嘉洵。)

- 小米AI眼鏡內部解析:元件緊湊性考驗 - 2026/04/08
- 小孩才選擇!Arduino VENTUNO Q全都要 - 2026/03/26
- 樹莓派也能「養龍蝦」! - 2026/03/24
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


