作者:高煥堂
1.Gemma簡介
- Gemma是最先進的開源大語言模型(LLM),它是Gemini模型小而美精緻版本。 Gemma 是由Google DeepMind團隊所主導創建的。

- Gemma模型是Text到Text的大型語言模型,非常適合各種文本生成任務,包括提問,摘要、和推理等。
- 有多種使用途徑,包括:(1) 使用新資料來微調Gemma模型,並不從頭開始重新訓練它。(2) 拿Gemma開源程式碼,而從頭開始訓練它。
- 本文介紹上述的第2種用法:如何從0訓練企業自用Gemma模型。
2.下載Gemma程式碼
首先進入這個網頁:https://github.com/google/gemma_pytorch
按下<Code>,就可以下載Gemma源碼到您的終端電腦裡,如下:
接下來,就把它複製到Python的工作區裡,並解開它,如下:
點開它,可以看到Gemma的源碼架構和內容了:
於是,順利下載源碼成功了。
3.從Gemma核心的Attention機制出發
複習Attention機制
由於您對於相似度的計算,已經建立良好的基礎了。就可以輕易地來理解和掌握注意力(Attention)機制。這項機制在許多大語言模型(如ChatGPT、Gemma等)裡,都扮演了極為關鍵性的角色。再看看最近聲勢非常浩大的Sora,其關鍵技術 — DiT(Diffusion Transformer)的核心也是注意力機制。
於是,本文就從相似度(Similarity)基礎,繼續延伸到注意力機制。更重要的是:此項機制也是可以學習的(Learnable),於是就來把它包裝於NN模型裡,成為可以訓練的注意力模型(Attention model)。典型的Attention模型,包括兩種:交叉注意力(CrossAttention)和自注意力(SelfAttention)。本文就先來說明SelfAttention模型的計算邏輯,及其訓練方法。
以<企業經營>來做比喻
首先來做個比喻。例如,一個公司有三個部門,其投資額(以X表示),經過一年的經營績效比率(以W表示),其營收額(以V表示)。如下圖所示:
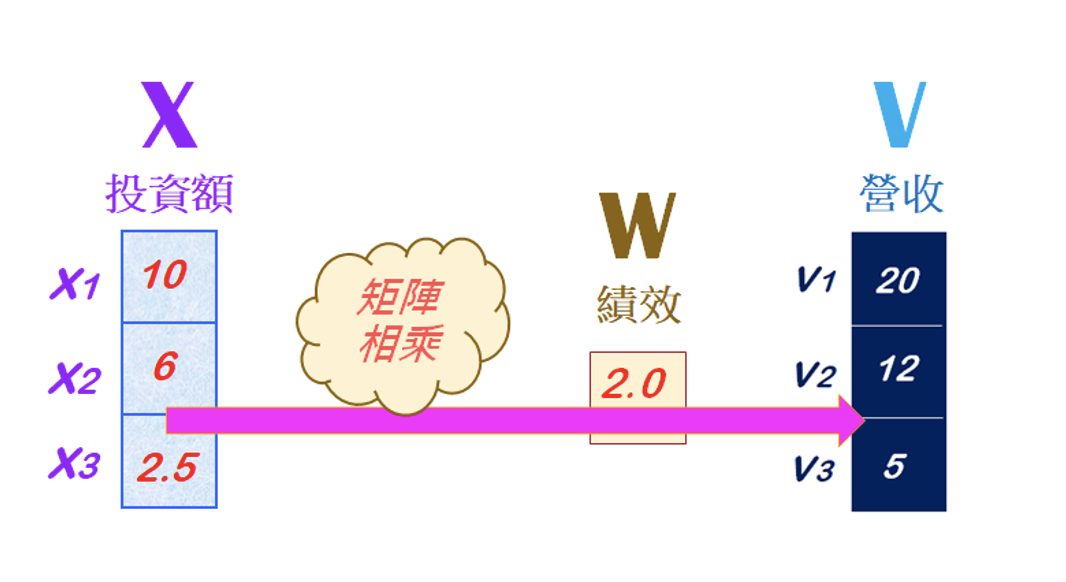
這三部門投資額是:X=[10, 6, 2.5],其單位是—百萬元。經過一年的經營,其營收比率是:W=[2.0],就可以計算出營收金額是:V=[20, 12, 5]。
接下來,公司的經營團隊開始規畫下一年度的投資方案,針對未來新的商業投資獲利注意點,擬定一個投資預算分配表(即注意力表),然後計算出新年度的投資預算金額(單位:百萬元)。如下圖所示:
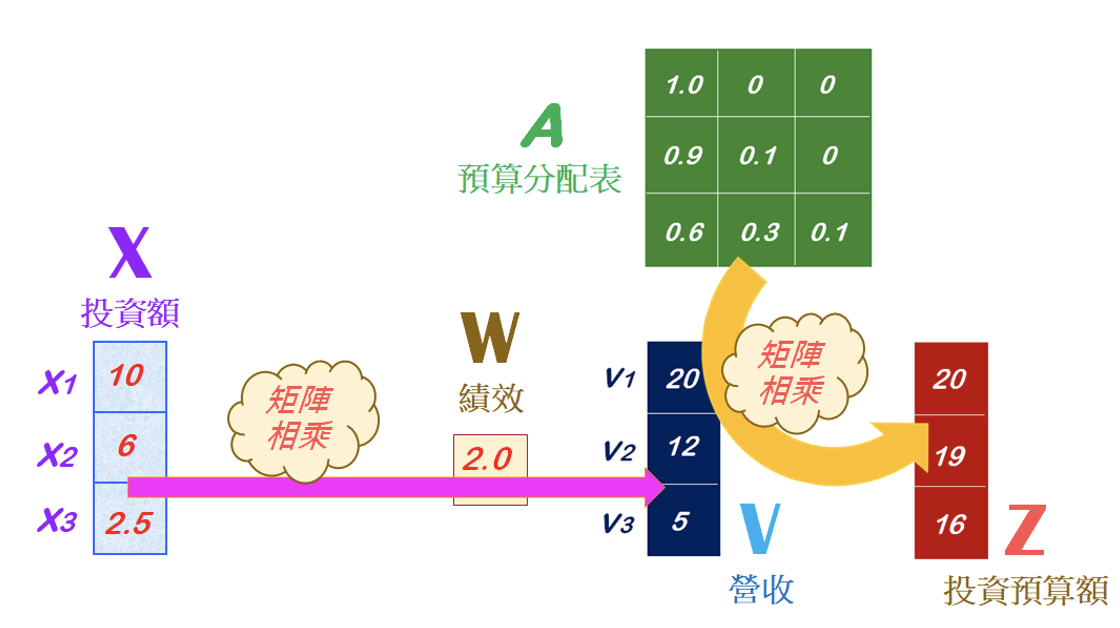
其中的預算分配表,可以是相似度矩陣(Similarity matrix),亦即經由相似度的計算而來。現在,就來理解上圖的計算邏輯,請觀摩一個Python的程式碼:
# gem_qk_001.py
import numpy as np
import torch
X = torch.tensor([[10.0],[6.0],[2.5]]) # 投資額
W = torch.tensor([[2.0]]) # 經營績效
V = X.matmul(W) # 計算營收
A = torch.tensor(
[[1.0, 0., 0.],
[0.9, 0.1, 0.],
[0.6, 0.3, 0.1]]) # 預算分配表
Z = A.matmul(V) # 計算分配額
print('\n---- 投資預算額Z ----')
print(Z)
#END
接著,就執行這個程式。此時就輸入X和W,計算出V值。然後輸入相似度表A,計算出新年度的投資預算額,並輸出如下:

使用Attention计算公式
剛才已經說明了,相似度矩陣是直接計算向量的點積(Dot-product),即將兩向量的對應元素相乘再相加。然後,這相似度矩陣再除以它們的歐氏長度的乘積,將相似度的值正規化,就得到余弦(Cosine)相似度。而且,如果將上述的相似度矩陣,在經由Softmax()函數的運算,就得到注意力矩陣(Attention weights)了。例如,有兩個矩陣:Q和K,就能計算出注意力矩陣。如下圖所示:
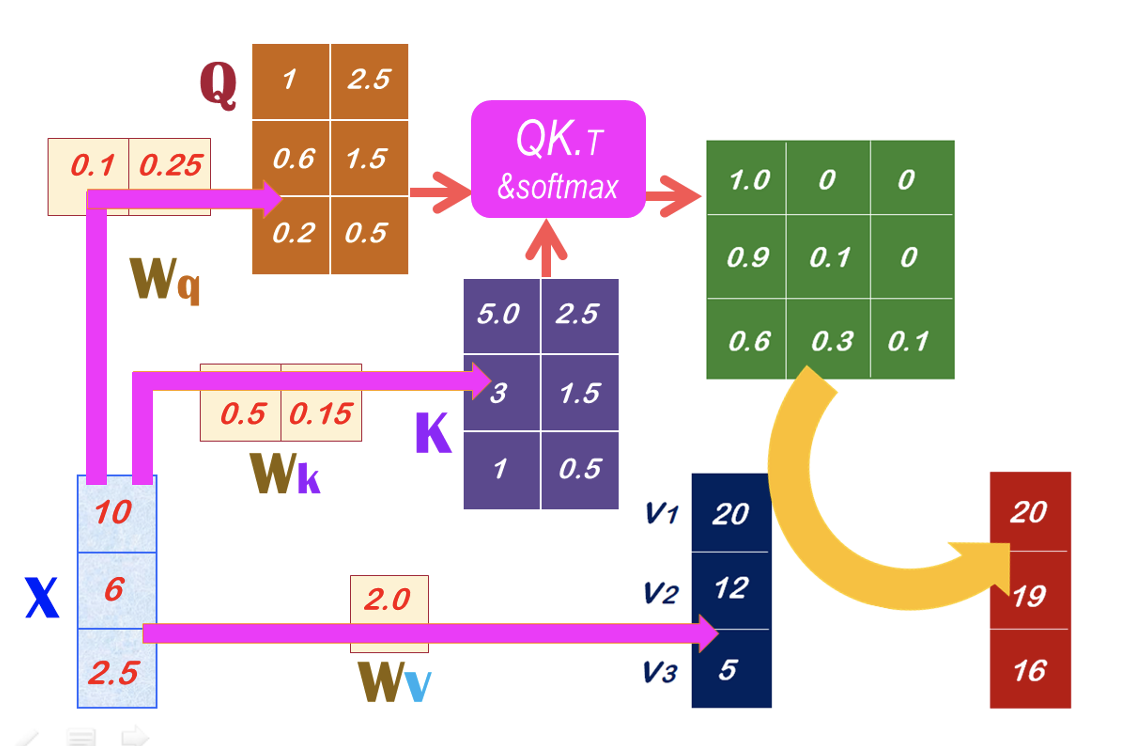
當我們把上圖裡的Wq、Wk和Wv權重都放入SelfAttention模型裡,就能進行機器學習(Machine learning)來找出最佳的權重值(即Wq、Wk和Wv),就能預測出Q、K和V了。並且可繼續計算出A了。
訓練SelfAttention模型
現在就把Wq、Wk和Wv都放入SelfAttention模型裡。請觀摩這個SelfAttention模型的程式碼範例,如下:
# gem_qk_002.py
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
class SelfAttention(nn.Module): # 定義模型
def __init__(self):
super(SelfAttention, self).__init__()
self.Wq = nn.Linear(1, 2, bias=False)
self.Wk = nn.Linear(1, 2, bias=False)
self.Wv = nn.Linear(1, 1, bias=False)
def forward(self, x):
Q = self.Wq(x)
K = self.Wk(x)
V = self.Wv(x)
Scores = Q.matmul(K.T)
A = F.softmax(Scores, dim=-1) # Attention_weights
Z = A.matmul(V) # 計算Z
return Z, A, V
model = SelfAttention() # 建立模型
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.004)
# 輸入X
X = torch.tensor([[10.0],[6.0],[2.5]])
# 設定Target Z
target_attn = torch.tensor([[20.0],[19.0],[16.0]])
print('展開訓練1800回合...')
for epoch in range(1800+1):
Z, A, V = model(X) # 正向傳播
loss = criterion(Z, target_attn) # 計算損失
optimizer.zero_grad() # 反向傳播和優化
loss.backward()
optimizer.step()
if(epoch%600 == 0):
print('ep=', epoch, 'loss=', loss.item())
# 進行預測
Z, A, V = model(X)
print('\n----- 預算分配表A -----')
print(np.round(A.detach().numpy(), 1))
print('\n----- 投資預算額Z -----')
print(np.round(Z.detach().numpy()))
#END
然後就執行這個程式,此時會展開1800回合的訓練。在訓練過程中,回持續修正模型裡的權重(即Wq、Wk和Wv),並且其損失(Loss)值會持續下降,如下:

一旦訓練完成了,就可以展開預測(Prediction)。此時,就計算出Q、K和V,然後繼續計算出A和Z值。以上基於相似度計算,繼續說明注意力機制的計算邏輯,建立SelfAttention模型,並且訓練1800回合,然後進行預測。
從這範例中,可以領會到SelfAttention模型能順利捕捉到企業的經營規律,並進行準確的預測。
4.繼續擴大到Gemma Model模型
請觀摩範例程式:
# gem_qk_003.py
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
from einops import rearrange
# 定義模型
class GemmaAttention(nn.Module):
def __init__(self, head_dim):
super(GemmaAttention, self).__init__()
self.head_dim = head_dim
self.scaling = 1 / math.sqrt(self.head_dim) # self.head_dim**-0.5
self.Wq = nn.Linear(self.head_dim, self.head_dim)
self.Wk = nn.Linear(self.head_dim, self.head_dim)
self.Wv = nn.Linear(self.head_dim, self.head_dim)
def forward( self, x):
q = self.Wq( x )
k = self.Wk( x )
v = self.Wv( x )
# 計算相似度
scores = q.matmul(k.transpose(1, 2)) * self.scaling
# 計算Attention weights
a = F.softmax(scores, dim=-1)
z = a.matmul(v)
return z, a
# 建立模型
model = GemmaAttention(head_dim=10)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.004)
# 設定Target weight
T = torch.FloatTensor( [[0,0,0,0,0, 1,0,0,0,0],
[0,0,0,0,0, 0,1,0,0,0],
[0,0,0,0,0, 0,0,1,0,0],
[0,0,0,0,0, 0,0,0,1,0]] )
# 輸入資料
X = torch.FloatTensor( [[1,0,0,0,0, 0,0,0,0,0],
[0,1,0,0,0, 0,0,0,0,0],
[0,0,1,0,0, 0,0,0,0,0],
[0,0,0,1,0, 0,0,0,0,0]] )
X = X.unsqueeze(0)
T = T.unsqueeze(0)
#----------- 訓練500回合 -----------------
print('展開訓練...')
for epoch in range(500+1):
# 正向傳播
Z, A = model(X)
# 計算損失
loss = criterion(Z, T)
# 反向傳播和優化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每1個迴圈印出損失
if(epoch%100 == 0):
print('ep=', epoch, 'loss=', loss.item())
#------------------
Z, A = model(X)
print('\n----- A -----')
print(np.round(A.detach().numpy(), 1))
print('\n----- Z -----')
print(np.round(Z.detach().numpy()))
#------------------
#END
然後就執行這個程式,此時會展開500回合的訓練,並輸出,如下:

接著,繼續擴大添加更多Gemma的細節功能,請觀摩程式碼:
# gem_qk_004.py
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
from einops import rearrange
#-----------------------------------------
# 定義模型
class GemmaAttention(nn.Module):
def __init__(self, hidden_size, num_heads, head_dim):
super(GemmaAttention, self).__init__()
self.hidden_size = hidden_size
self.num_heads = num_heads
self.head_dim = head_dim
self.num_kv_heads = 1 #MultiQuery
self.num_queries_per_kv = self.num_heads // self.num_kv_heads
self.q_size = self.num_heads * self.head_dim
self.kv_size = self.num_kv_heads * self.head_dim
self.scaling = 1 / math.sqrt(self.head_dim) # self.head_dim**-0.5
self.qkv_proj = nn.Linear(self.hidden_size,
(self.num_heads + 2*self.num_kv_heads)*self.head_dim)
self.o_proj = nn.Linear(
self.num_heads * self.head_dim,
self.hidden_size)
def forward( self,
hidden_states,
kv_write_indices,
kv_cache,
mask ):
hidden_states_shape = hidden_states.shape
assert len(hidden_states_shape) == 3
batch_size, input_len, _ = hidden_states_shape
qkv = self.qkv_proj( hidden_states )
xq, xk, xv = qkv.split( [self.q_size,
self.kv_size,
self.kv_size], dim=2)
xq = xq.view(batch_size, -1, self.num_heads, self.head_dim)
xk = xk.view(batch_size, -1, self.num_kv_heads, self.head_dim)
xv = xv.view(batch_size, -1, self.num_kv_heads, self.head_dim)
#------------------------------------
k_cache, v_cache = kv_cache
k_cache.index_copy_(1, kv_write_indices, xk)
v_cache.index_copy_(1, kv_write_indices, xv)
key = k_cache
value = v_cache
if self.num_kv_heads != self.num_heads:
# [batch_size, max_seq_len, n_local_heads, head_dim]
key = torch.repeat_interleave(key, self.num_queries_per_kv, dim=2)
value = torch.repeat_interleave(value,
self.num_queries_per_kv,
dim=2)
#-----------------------------------------------
q = xq.transpose(1, 2)
k = xk.transpose(1, 2)
v = xv.transpose(1, 2)
# 計算分配表
scores = q.matmul(k.transpose(2, 3)) * self.scaling
scores = scores + mask
a = F.softmax(scores, dim=-1)
#---- 計算分配額 -----------
output = a.matmul(v)
z = (output.transpose(1, 2).contiguous().view(
batch_size, input_len, -1))
z = self.o_proj(z)
return z, a, v
#--------- 建立模型 --------------------
model = GemmaAttention(hidden_size=10, num_heads=2, head_dim=8)
criterion = nn.MSELoss()
#optimizer = torch.optim.SGD(model.parameters(), lr=0.15)
optimizer = torch.optim.Adam(model.parameters(), lr=0.004)
# 設定Target
T = torch.FloatTensor( [[0,0,0,0,0, 1,0,0,0,0],
[0,0,0,0,0, 0,1,0,0,0],
[0,0,0,0,0, 0,0,1,0,0],
[0,0,0,0,0, 0,0,0,1,0]] )
# 輸入資料
X = torch.FloatTensor( [[1,0,0,0,0, 0,0,0,0,0],
[0,1,0,0,0, 0,0,0,0,0],
[0,0,1,0,0, 0,0,0,0,0],
[0,0,0,1,0, 0,0,0,0,0]] )
X = X.unsqueeze(0)
T = T.unsqueeze(0)
batch_size = 1
seq_len = 4
num_kv_heads = 1
head_dim = 8
kc_cache = torch.randn(batch_size, seq_len, num_kv_heads, head_dim)
vc_cache = torch.randn(batch_size, seq_len, num_kv_heads, head_dim)
kv_cache = (kc_cache, vc_cache)
mask = torch.tensor([1, 1, 1, 1], dtype=torch.float32)
kv_write_indices = torch.LongTensor([0, 1, 2, 3])
#---- 訓練500回合 ----
print('展開訓練...')
for epoch in range(500):
# 正向傳播
Z, A, V = model(X, kv_write_indices, kv_cache, mask)
# 計算損失
loss = criterion(Z, T)
# 反向傳播和優化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每1個迴圈印出損失
if(epoch%100 == 0):
print('ep=', epoch, 'loss=', loss.item())
#------------------------------
print('\n----- A -----')
print(np.round(A.detach().numpy(), 1))
print('\n----- Z -----')
print(np.round(Z.detach().numpy()))
#------------------------------
#END
然後就執行這個程式,此時會展開500回合的訓練,並輸出,如下:

接著,繼續擴大添加更多Gemma的細節功能,請觀摩程式碼:
# gem_qk_005.py
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
from einops import rearrange
#-----------------------------------------
def apply_rotary_emb(x: torch.Tensor, freqs_cis: torch.Tensor) -> torch.Tensor:
x_ = torch.view_as_complex(
torch.stack(torch.chunk(x.transpose(1, 2).float(), 2, dim=-1),
dim=-1))
x_out = torch.view_as_real(x_ * freqs_cis).type_as(x)
x_out = torch.cat(torch.chunk(x_out, 2, dim=-1), dim=-2)
x_out = x_out.reshape(x_out.shape[0], x_out.shape[1], x_out.shape[2],
-1).transpose(1, 2)
return x_out
# 定義模型
class GemmaAttention(nn.Module):
def __init__(self, hidden_size, num_heads, head_dim):
super(GemmaAttention, self).__init__()
self.hidden_size = hidden_size
self.num_heads = num_heads
self.head_dim = head_dim
self.num_kv_heads = 1 #MultiQuery
self.num_queries_per_kv = self.num_heads // self.num_kv_heads
self.q_size = self.num_heads * self.head_dim
self.kv_size = self.num_kv_heads * self.head_dim
self.scaling = 1 / math.sqrt(self.head_dim) # self.head_dim**-0.5
self.qkv_proj = nn.Linear(self.hidden_size,
(self.num_heads + 2*self.num_kv_heads)*self.head_dim)
self.o_proj = nn.Linear(
self.num_heads * self.head_dim,
self.hidden_size)
def forward( self,
hidden_states,
freqs_cis,
kv_write_indices,
kv_cache,
mask ):
hidden_states_shape = hidden_states.shape
assert len(hidden_states_shape) == 3
batch_size, input_len, _ = hidden_states_shape
qkv = self.qkv_proj( hidden_states )
xq, xk, xv = qkv.split( [self.q_size,
self.kv_size,
self.kv_size], dim=2)
xq = xq.view(batch_size, -1, self.num_heads, self.head_dim)
xk = xk.view(batch_size, -1, self.num_kv_heads, self.head_dim)
xv = xv.view(batch_size, -1, self.num_kv_heads, self.head_dim)
# Positional embedding.
xq = apply_rotary_emb(xq, freqs_cis=freqs_cis)
xk = apply_rotary_emb(xk, freqs_cis=freqs_cis)
#------------------------------------
k_cache, v_cache = kv_cache
k_cache.index_copy_(1, kv_write_indices, xk)
v_cache.index_copy_(1, kv_write_indices, xv)
key = k_cache
value = v_cache
if self.num_kv_heads != self.num_heads:
# [batch_size, max_seq_len, n_local_heads, head_dim]
key = torch.repeat_interleave(key, self.num_queries_per_kv, dim=2)
value = torch.repeat_interleave(value,
self.num_queries_per_kv,
dim=2)
#-----------------------------------------------
q = xq.transpose(1, 2)
k = xk.transpose(1, 2)
v = xv.transpose(1, 2)
# 計算分配表
scores = q.matmul(k.transpose(2, 3)) * self.scaling
scores = scores + mask
a = F.softmax(scores, dim=-1)
#---- 計算分配額 -----------
output = a.matmul(v)
z = (output.transpose(1, 2).contiguous().view(
batch_size, input_len, -1))
z = self.o_proj(z)
return z, a, v
#--------- 建立模型 --------------------
model = GemmaAttention(hidden_size=10, num_heads=2, head_dim=8)
criterion = nn.MSELoss()
#optimizer = torch.optim.SGD(model.parameters(), lr=0.15)
optimizer = torch.optim.Adam(model.parameters(), lr=0.004)
#--- 採監督式學習:設定Target weight -----
T = torch.FloatTensor( [[0,0,0,0,0, 1,0,0,0,0],
[0,0,0,0,0, 0,1,0,0,0],
[0,0,0,0,0, 0,0,1,0,0],
[0,0,0,0,0, 0,0,0,1,0]] )
#--------------------------------------
# 投資額
X = torch.FloatTensor( [[1,0,0,0,0, 0,0,0,0,0],
[0,1,0,0,0, 0,0,0,0,0],
[0,0,1,0,0, 0,0,0,0,0],
[0,0,0,1,0, 0,0,0,0,0]] )
X = X.unsqueeze(0)
T = T.unsqueeze(0)
batch_size = 1
seq_len = 4
num_kv_heads = 1
head_dim = 8
kc_cache = torch.randn(batch_size, seq_len, num_kv_heads, head_dim)
vc_cache = torch.randn(batch_size, seq_len, num_kv_heads, head_dim)
kv_cache = (kc_cache, vc_cache)
mask = torch.tensor([1, 1, 1, 1], dtype=torch.float32)
freqs_cis = torch.tensor([[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]
], dtype=torch.float32)
kv_write_indices = torch.LongTensor([0, 1, 2, 3])
#----------- 訓練500回合 -----------------
print('展開訓練...')
for epoch in range(500+1):
# 正向傳播
Z, A, V = model(X, freqs_cis, kv_write_indices, kv_cache, mask)
# 計算損失
loss = criterion(Z, T)
# 反向傳播和優化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每1個迴圈印出損失
if(epoch%100 == 0):
print('ep=', epoch, 'loss=', loss.item())
#------------------------------
Z, A, V = model(X, freqs_cis, kv_write_indices, kv_cache, mask)
print('\n----- A -----')
print(np.round(A.detach().numpy(), 1))
print('\n----- Z -----')
print(np.round(Z.detach().numpy()))
#------------------
#END
然後就執行這個程式,此時會展開500回合的訓練,並輸出,如下:
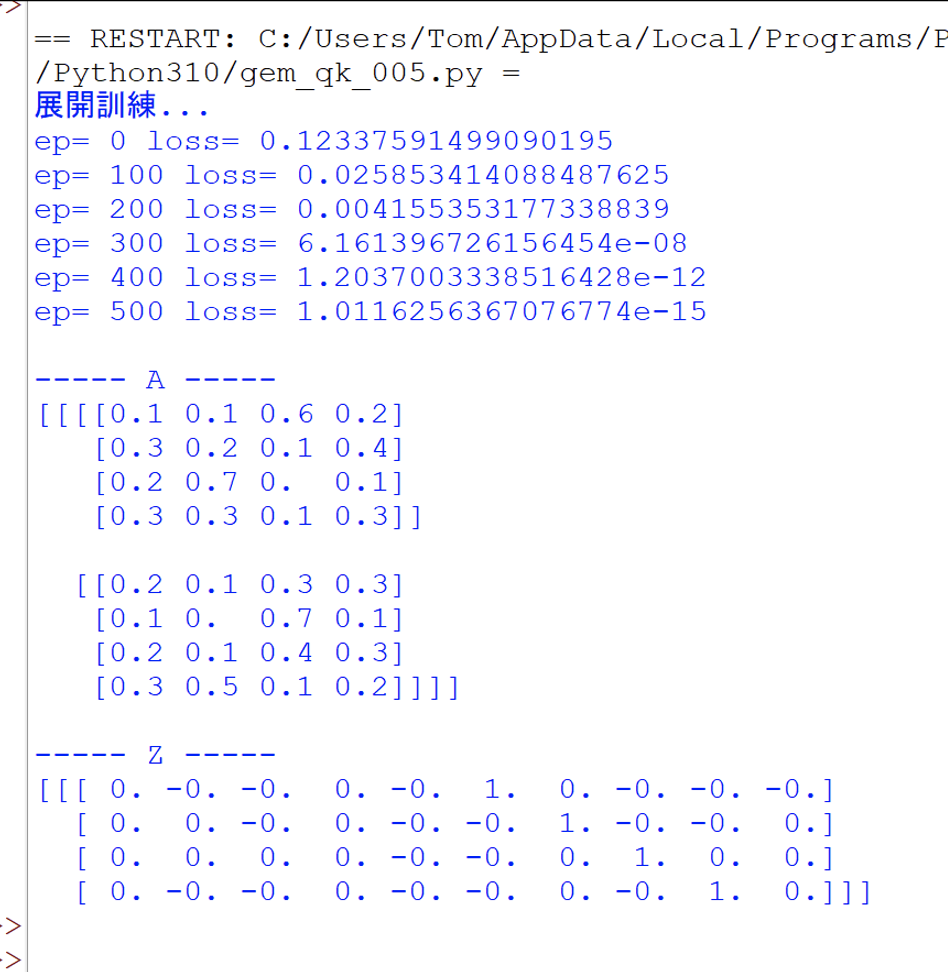
接著,繼續擴大添加更多Gemma的細節功能,請觀摩程式碼:
# gem_qk_006.py
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
from einops import rearrange
from typing import Any, List, Optional, Sequence, Tuple, Union
from gemma import config as gemma_config
#-----------------------------------------
def apply_rotary_emb(x: torch.Tensor, freqs_cis: torch.Tensor) -> torch.Tensor:
x_ = torch.view_as_complex(
torch.stack(torch.chunk(x.transpose(1, 2).float(), 2, dim=-1),
dim=-1))
x_out = torch.view_as_real(x_ * freqs_cis).type_as(x)
x_out = torch.cat(torch.chunk(x_out, 2, dim=-1), dim=-2)
x_out = x_out.reshape(x_out.shape[0], x_out.shape[1], x_out.shape[2],
-1).transpose(1, 2)
return x_out
#--------------------------------------
class RMSNorm(torch.nn.Module):
def __init__(
self,
dim: int,
eps: float = 1e-6,
add_unit_offset: bool = True,
):
super().__init__()
self.eps = eps
self.add_unit_offset = add_unit_offset
self.weight = nn.Parameter(torch.zeros(dim))
def _norm(self, x):
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
x = self._norm(x.float()).type_as(x)
if self.add_unit_offset:
output = x * (1 + self.weight)
else:
output = x * self.weight
return output
#---------------------------------------
# 定義模型
class GemmaAttention(nn.Module):
def __init__(self, hidden_size, num_heads, num_kv_heads, head_dim, quant):
super(GemmaAttention, self).__init__()
self.hidden_size = hidden_size
self.num_heads = num_heads
self.head_dim = head_dim
self.num_kv_heads = num_kv_heads
self.num_queries_per_kv = self.num_heads // self.num_kv_heads
self.q_size = self.num_heads * self.head_dim
self.kv_size = self.num_kv_heads * self.head_dim
self.scaling = 1 / math.sqrt(self.head_dim) # self.head_dim**-0.5
self.qkv_proj = nn.Linear(self.hidden_size,
(self.num_heads + 2*self.num_kv_heads)*self.head_dim)
self.o_proj = nn.Linear(
self.num_heads * self.head_dim,
self.hidden_size)
def forward( self,
hidden_states,
freqs_cis,
kv_write_indices,
kv_cache,
mask ):
hidden_states_shape = hidden_states.shape
assert len(hidden_states_shape) == 3
batch_size, input_len, _ = hidden_states_shape
qkv = self.qkv_proj( hidden_states )
xq, xk, xv = qkv.split( [self.q_size,
self.kv_size,
self.kv_size], dim=2)
xq = xq.view(batch_size, -1, self.num_heads, self.head_dim)
xk = xk.view(batch_size, -1, self.num_kv_heads, self.head_dim)
xv = xv.view(batch_size, -1, self.num_kv_heads, self.head_dim)
# Positional embedding.
xq = apply_rotary_emb(xq, freqs_cis=freqs_cis)
xk = apply_rotary_emb(xk, freqs_cis=freqs_cis)
#------------------------------------
k_cache, v_cache = kv_cache
k_cache.index_copy_(1, kv_write_indices, xk)
v_cache.index_copy_(1, kv_write_indices, xv)
key = k_cache
value = v_cache
if self.num_kv_heads != self.num_heads:
# [batch_size, max_seq_len, n_local_heads, head_dim]
key = torch.repeat_interleave(key, self.num_queries_per_kv, dim=2)
value = torch.repeat_interleave(value,
self.num_queries_per_kv,
dim=2)
#-----------------------------------------------
q = xq.transpose(1, 2)
k = xk.transpose(1, 2)
v = xv.transpose(1, 2)
# 計算分配表
scores = q.matmul(k.transpose(2, 3)) * self.scaling
scores = scores + mask
a = F.softmax(scores, dim=-1)
#---- 計算分配額 -----------
output = a.matmul(v)
z = (output.transpose(1, 2).contiguous().view(
batch_size, input_len, -1))
z = self.o_proj(z)
return z
#-------------------------------------
class GemmaDecoderLayer(nn.Module):
def __init__(
self,
hidden_size,
num_heads,
num_kv_heads,
head_dim,
quant=False,
):
super().__init__()
self.self_attn = GemmaAttention(
hidden_size=hidden_size,
num_heads=num_heads,
num_kv_heads=num_kv_heads,
head_dim=head_dim,
quant=quant,
)
self.rms_norm_eps = 1e-6
self.input_layernorm = RMSNorm(hidden_size,
eps=self.rms_norm_eps)
self.post_attention_layernorm = RMSNorm(hidden_size,
eps=self.rms_norm_eps)
def forward(
self,
hidden_states: torch.Tensor,
freqs_cis: torch.Tensor,
kv_write_indices: torch.Tensor,
kv_cache: Tuple[torch.Tensor, torch.Tensor],
mask: torch.Tensor,
):
# Self Attention
residual = hidden_states
hidden_states = self.input_layernorm(hidden_states)
hidden_states = self.self_attn(
hidden_states=hidden_states,
freqs_cis=freqs_cis,
kv_write_indices=kv_write_indices,
kv_cache=kv_cache,
mask=mask,
)
hidden_states = residual + hidden_states
return hidden_states
#--------- 建立模型 --------------------
model = GemmaDecoderLayer(hidden_size=10, num_heads=3, num_kv_heads=1, head_dim=8)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.004)
# 設定Target
T = torch.FloatTensor( [[0,0,0,0,0, 1,0,0,0,0],
[0,0,0,0,0, 0,1,0,0,0],
[0,0,0,0,0, 0,0,1,0,0],
[0,0,0,0,0, 0,0,0,1,0]] )
# Input資料
X = torch.FloatTensor( [[1,0,0,0,0, 0,0,0,0,0],
[0,1,0,0,0, 0,0,0,0,0],
[0,0,1,0,0, 0,0,0,0,0],
[0,0,0,1,0, 0,0,0,0,0]] )
X = X.unsqueeze(0)
T = T.unsqueeze(0)
batch_size = 1
seq_len = 4
num_kv_heads = 1
head_dim = 8
kc_cache = torch.randn(batch_size, seq_len, num_kv_heads, head_dim)
vc_cache = torch.randn(batch_size, seq_len, num_kv_heads, head_dim)
kv_cache = (kc_cache, vc_cache)
mask = torch.tensor([1, 1, 1, 1], dtype=torch.float32)
freqs_cis = torch.tensor([[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]
], dtype=torch.float32)
kv_write_indices = torch.LongTensor([0, 1, 2, 3])
#----------- 訓練1000回合 -----------------
print('展開訓練...')
for epoch in range(1000):
# 正向傳播
Z = model(X, freqs_cis, kv_write_indices, kv_cache, mask)
# 計算損失
loss = criterion(Z, T)
# 反向傳播和優化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每1個迴圈印出損失
if(epoch%100 == 0):
print('ep=', epoch, 'loss=', loss.item())
#------------------------------
Z = model(X, freqs_cis, kv_write_indices, kv_cache, mask)
print('\n----- 投資預算額Z -----')
print(np.round(Z.detach().numpy()))
#------------------
#END
然後就執行這個程式,此時會展開1000回合的訓練,並輸出,如下:
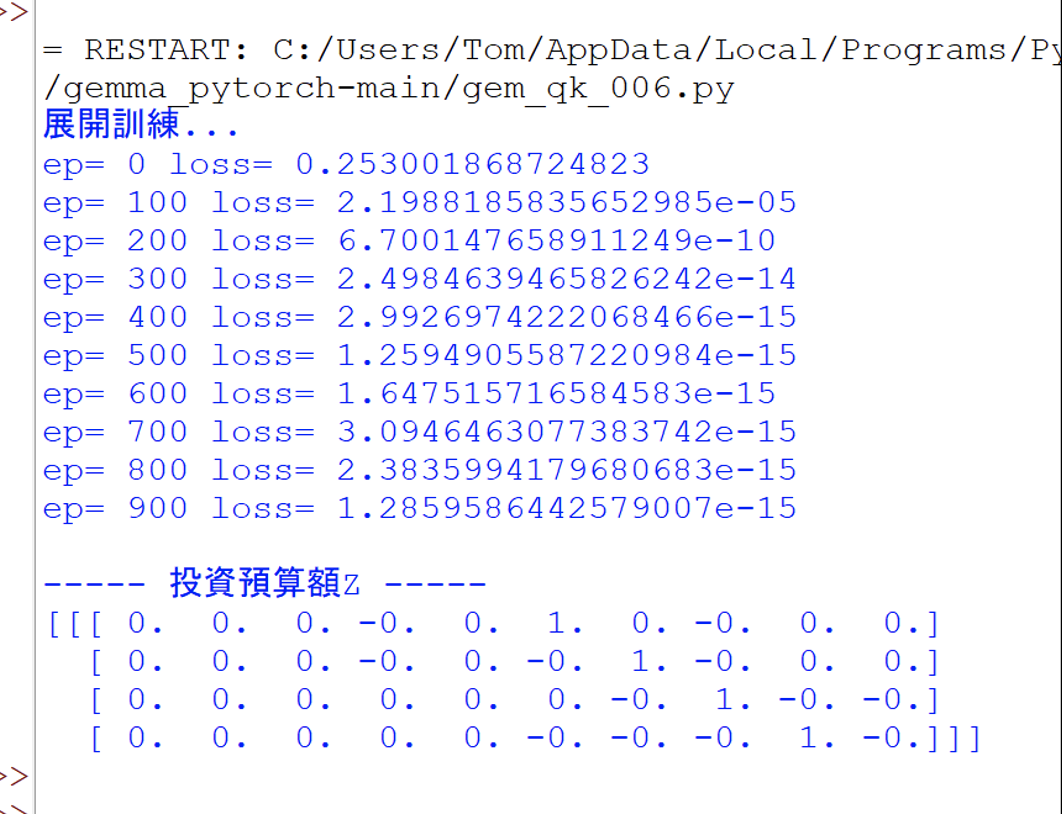
接著,繼續擴大添加更多Gemma的細節功能,請觀摩程式碼:
# gem_qk_007.py
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
from einops import rearrange
from typing import Any, List, Optional, Sequence, Tuple, Union
from gemma import config as gemma_config
#-----------------------------------------
def apply_rotary_emb(x: torch.Tensor, freqs_cis: torch.Tensor) -> torch.Tensor:
x_ = torch.view_as_complex(
torch.stack(torch.chunk(x.transpose(1, 2).float(), 2, dim=-1),
dim=-1))
x_out = torch.view_as_real(x_ * freqs_cis).type_as(x)
x_out = torch.cat(torch.chunk(x_out, 2, dim=-1), dim=-2)
x_out = x_out.reshape(x_out.shape[0], x_out.shape[1], x_out.shape[2],
-1).transpose(1, 2)
return x_out
#--------------------------------------
class RMSNorm(torch.nn.Module):
def __init__(
self,
dim: int,
eps: float = 1e-6,
add_unit_offset: bool = True,
):
super().__init__()
self.eps = eps
self.add_unit_offset = add_unit_offset
self.weight = nn.Parameter(torch.zeros(dim))
def _norm(self, x):
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
x = self._norm(x.float()).type_as(x)
if self.add_unit_offset:
output = x * (1 + self.weight)
else:
output = x * self.weight
return output
#---------------------------------------
# 定義模型
class GemmaAttention(nn.Module):
def __init__(self, hidden_size, num_heads, num_kv_heads, head_dim, quant):
super(GemmaAttention, self).__init__()
self.hidden_size = hidden_size
self.num_heads = num_heads
self.head_dim = head_dim
self.num_kv_heads = num_kv_heads
self.num_queries_per_kv = self.num_heads // self.num_kv_heads
self.q_size = self.num_heads * self.head_dim
self.kv_size = self.num_kv_heads * self.head_dim
self.scaling = 1 / math.sqrt(self.head_dim) # self.head_dim**-0.5
self.qkv_proj = nn.Linear(self.hidden_size,
(self.num_heads + 2*self.num_kv_heads)*self.head_dim)
self.o_proj = nn.Linear(
self.num_heads * self.head_dim,
self.hidden_size)
def forward( self,
hidden_states,
freqs_cis,
kv_write_indices,
kv_cache,
mask ):
hidden_states_shape = hidden_states.shape
assert len(hidden_states_shape) == 3
batch_size, input_len, _ = hidden_states_shape
qkv = self.qkv_proj( hidden_states )
xq, xk, xv = qkv.split( [self.q_size,
self.kv_size,
self.kv_size], dim=2)
xq = xq.view(batch_size, -1, self.num_heads, self.head_dim)
xk = xk.view(batch_size, -1, self.num_kv_heads, self.head_dim)
xv = xv.view(batch_size, -1, self.num_kv_heads, self.head_dim)
# Positional embedding.
xq = apply_rotary_emb(xq, freqs_cis=freqs_cis)
xk = apply_rotary_emb(xk, freqs_cis=freqs_cis)
#------------------------------------
#kv_write_indices = torch.LongTensor([0, 1, 2, 3])
k_cache, v_cache = kv_cache
k_cache.index_copy_(1, kv_write_indices, xk)
v_cache.index_copy_(1, kv_write_indices, xv)
key = k_cache
value = v_cache
if self.num_kv_heads != self.num_heads:
# [batch_size, max_seq_len, n_local_heads, head_dim]
key = torch.repeat_interleave(key, self.num_queries_per_kv, dim=2)
value = torch.repeat_interleave(value,
self.num_queries_per_kv,
dim=2)
#-----------------------------------------------
q = xq.transpose(1, 2)
k = xk.transpose(1, 2)
v = xv.transpose(1, 2)
# 計算分配表
scores = q.matmul(k.transpose(2, 3)) * self.scaling
scores = scores + mask
a = F.softmax(scores, dim=-1)
#---- 計算分配額 -----------
output = a.matmul(v)
z = (output.transpose(1, 2).contiguous().view(
batch_size, input_len, -1))
z = self.o_proj(z)
return z
#-------------------------------------
class GemmaDecoderLayer(nn.Module):
def __init__(
self,
hidden_size,
num_heads,
num_kv_heads,
head_dim,
quant=False,
):
super().__init__()
self.self_attn = GemmaAttention(
hidden_size=hidden_size,
num_heads=num_heads,
num_kv_heads=num_kv_heads,
head_dim=head_dim,
quant=quant,
)
self.rms_norm_eps = 1e-6
self.input_layernorm = RMSNorm(hidden_size,
eps=self.rms_norm_eps)
self.post_attention_layernorm = RMSNorm(hidden_size,
eps=self.rms_norm_eps)
def forward(
self,
hidden_states: torch.Tensor,
freqs_cis: torch.Tensor,
kv_write_indices: torch.Tensor,
kv_cache: Tuple[torch.Tensor, torch.Tensor],
mask: torch.Tensor,
):
# Self Attention
residual = hidden_states
hidden_states = self.input_layernorm(hidden_states)
hidden_states = self.self_attn(
hidden_states=hidden_states,
freqs_cis=freqs_cis,
kv_write_indices=kv_write_indices,
kv_cache=kv_cache,
mask=mask,
)
hidden_states = residual + hidden_states
return hidden_states
#---------------------------------------
class GemmaModel(nn.Module):
def __init__(self):
super().__init__()
self.vocab_size = 10
self.num_hidden_layers = 2
self.rms_norm_eps = 1e-6
self.layers = nn.ModuleList()
for _ in range(self.num_hidden_layers):
self.layers.append(GemmaDecoderLayer(hidden_size=10,
num_heads=3,
num_kv_heads=1,
head_dim=8))
self.norm = RMSNorm(10, eps=self.rms_norm_eps)
def forward(
self,
hidden_states,
freqs_cis,
kv_write_indices,
kv_caches,
mask,
) -> torch.Tensor:
for i in range(len(self.layers)):
layer = self.layers[i]
hidden_states = layer(
hidden_states=hidden_states,
freqs_cis=freqs_cis,
kv_write_indices=kv_write_indices,
kv_cache=kv_caches[i],
mask=mask,
)
hidden_states = self.norm(hidden_states)
return hidden_states
#--------- 建立模型 --------------------
model = GemmaModel()
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.004)
# 設定Target
T = torch.FloatTensor( [[0,0,0,0,0, 1,0,0,0,0],
[0,0,0,0,0, 0,1,0,0,0],
[0,0,0,0,0, 0,0,1,0,0],
[0,0,0,0,0, 0,0,0,1,0]] )
# Input資料
X = torch.FloatTensor( [[1,0,0,0,0, 0,0,0,0,0],
[0,1,0,0,0, 0,0,0,0,0],
[0,0,1,0,0, 0,0,0,0,0],
[0,0,0,1,0, 0,0,0,0,0]] )
X = X.unsqueeze(0)
T = T.unsqueeze(0)
batch_size = 1
seq_len = 4
num_kv_heads = 1
head_dim = 8
kc_cache = torch.randn(batch_size, seq_len, num_kv_heads, head_dim)
vc_cache = torch.randn(batch_size, seq_len, num_kv_heads, head_dim)
kv_cache = (kc_cache, vc_cache)
kv_caches = (kv_cache, kv_cache)
mask = torch.tensor([1, 1, 1, 1], dtype=torch.float32)
freqs_cis = torch.tensor([[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]
], dtype=torch.float32)
kv_write_indices = torch.LongTensor([0, 1, 2, 3])
#----------- 訓練1000回合 -----------------
print('展開訓練...')
for epoch in range(1000):
# 正向傳播
Z = model(X, freqs_cis, kv_write_indices, kv_caches, mask)
# 計算損失
loss = criterion(Z, T)
# 反向傳播和優化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每1個迴圈印出損失
if(epoch%100 == 0):
print('ep=', epoch, 'loss=', loss.item())
#------------------------------
Z = model(X, freqs_cis, kv_write_indices, kv_caches, mask)
print('\n----- Z -----')
print(np.round(Z.detach().numpy()))
#------------------
#END
然後就執行這個程式,此時會展開1000回合的訓練,並輸出,如下:
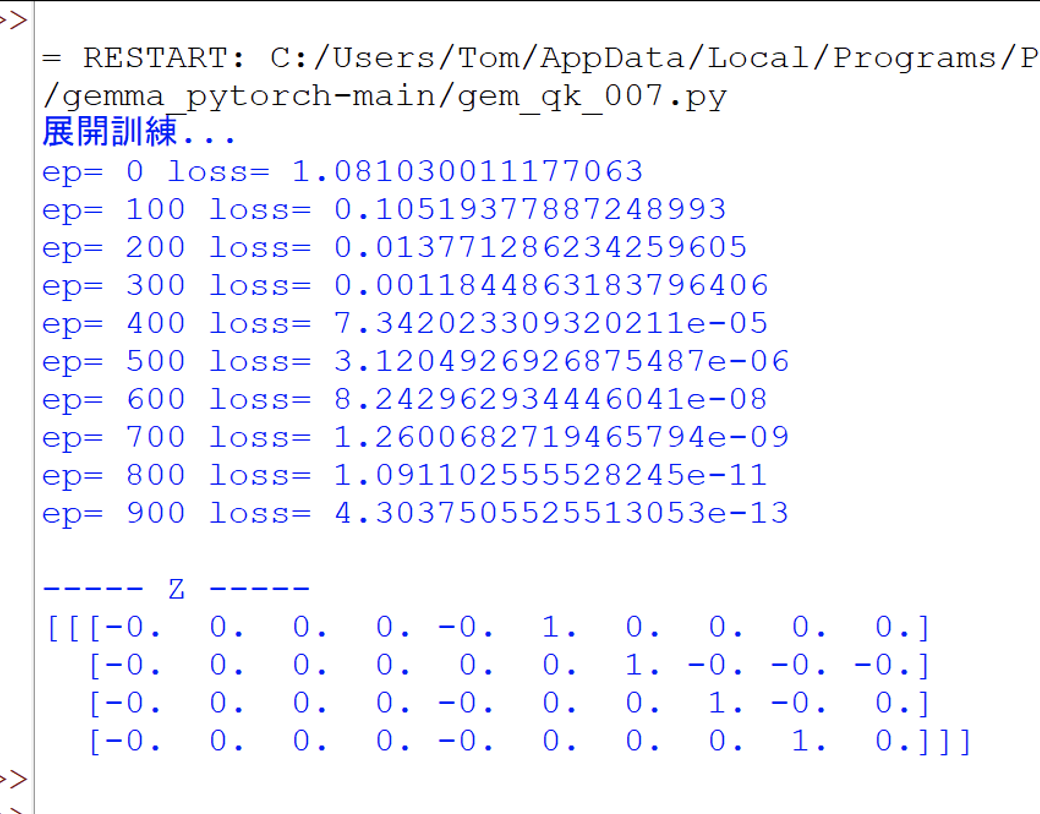
接著,繼續擴大添加更多Gemma的細節功能,請觀摩程式碼:
# gem_qk_008.py
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
import os
import sentencepiece as spm
from typing import Any, List, Optional, Sequence, Tuple, Union
from gemma import config as gemma_config
#-----------------------------------------
def apply_rotary_emb(x: torch.Tensor, freqs_cis: torch.Tensor) -> torch.Tensor:
x_ = torch.view_as_complex(
torch.stack(torch.chunk(x.transpose(1, 2).float(), 2, dim=-1),
dim=-1))
x_out = torch.view_as_real(x_ * freqs_cis).type_as(x)
x_out = torch.cat(torch.chunk(x_out, 2, dim=-1), dim=-2)
x_out = x_out.reshape(x_out.shape[0], x_out.shape[1], x_out.shape[2],
-1).transpose(1, 2)
return x_out
#--------------------------------------
class RMSNorm(torch.nn.Module):
def __init__(
self,
dim: int,
eps: float = 1e-6,
add_unit_offset: bool = True,
):
super().__init__()
self.eps = eps
self.add_unit_offset = add_unit_offset
self.weight = nn.Parameter(torch.zeros(dim))
def _norm(self, x):
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
x = self._norm(x.float()).type_as(x)
if self.add_unit_offset:
output = x * (1 + self.weight)
else:
output = x * self.weight
return output
#---------------------------------------
# 定義模型
class GemmaAttention(nn.Module):
def __init__(self, hidden_size, num_heads, num_kv_heads, head_dim, quant):
super(GemmaAttention, self).__init__()
self.hidden_size = hidden_size
self.num_heads = num_heads
self.head_dim = head_dim
self.num_kv_heads = num_kv_heads
self.num_queries_per_kv = self.num_heads // self.num_kv_heads
self.q_size = self.num_heads * self.head_dim
self.kv_size = self.num_kv_heads * self.head_dim
self.scaling = 1 / math.sqrt(self.head_dim) # self.head_dim**-0.5
self.qkv_proj = nn.Linear(self.hidden_size,
(self.num_heads + 2*self.num_kv_heads)*self.head_dim)
self.o_proj = nn.Linear(
self.num_heads * self.head_dim,
self.hidden_size)
def forward( self,
hidden_states,
freqs_cis,
kv_write_indices,
kv_cache,
mask ):
hidden_states_shape = hidden_states.shape
assert len(hidden_states_shape) == 3
batch_size, input_len, _ = hidden_states_shape
qkv = self.qkv_proj( hidden_states )
xq, xk, xv = qkv.split( [self.q_size,
self.kv_size,
self.kv_size], dim=2)
xq = xq.view(batch_size, -1, self.num_heads, self.head_dim)
xk = xk.view(batch_size, -1, self.num_kv_heads, self.head_dim)
xv = xv.view(batch_size, -1, self.num_kv_heads, self.head_dim)
# Positional embedding.
xq = apply_rotary_emb(xq, freqs_cis=freqs_cis)
xk = apply_rotary_emb(xk, freqs_cis=freqs_cis)
#------------------------------------
k_cache, v_cache = kv_cache
k_cache.index_copy_(1, kv_write_indices, xk)
v_cache.index_copy_(1, kv_write_indices, xv)
key = k_cache
value = v_cache
if self.num_kv_heads != self.num_heads:
# [batch_size, max_seq_len, n_local_heads, head_dim]
key = torch.repeat_interleave(key, self.num_queries_per_kv, dim=2)
value = torch.repeat_interleave(value,
self.num_queries_per_kv,
dim=2)
#-----------------------------------------------
q = xq.transpose(1, 2)
k = xk.transpose(1, 2)
v = xv.transpose(1, 2)
# 計算相似度分數
scores = q.matmul(k.transpose(2, 3)) * self.scaling
scores = scores + mask
a = F.softmax(scores, dim=-1)
# 計算Attention
output = a.matmul(v)
z = (output.transpose(1, 2).contiguous().view(
batch_size, input_len, -1))
z = self.o_proj(z)
return z
#-------------------------------------
class GemmaDecoderLayer(nn.Module):
def __init__(
self,
hidden_size,
num_heads,
num_kv_heads,
head_dim,
quant=False,
):
super().__init__()
self.self_attn = GemmaAttention(
hidden_size=hidden_size,
num_heads=num_heads,
num_kv_heads=num_kv_heads,
head_dim=head_dim,
quant=quant,
)
self.rms_norm_eps = 1e-6
self.input_layernorm = RMSNorm(hidden_size,
eps=self.rms_norm_eps)
self.post_attention_layernorm = RMSNorm(hidden_size,
eps=self.rms_norm_eps)
def forward(
self,
hidden_states: torch.Tensor,
freqs_cis: torch.Tensor,
kv_write_indices: torch.Tensor,
kv_cache: Tuple[torch.Tensor, torch.Tensor],
mask: torch.Tensor,
):
# Self Attention
residual = hidden_states
hidden_states = self.input_layernorm(hidden_states)
hidden_states = self.self_attn(
hidden_states=hidden_states,
freqs_cis=freqs_cis,
kv_write_indices=kv_write_indices,
kv_cache=kv_cache,
mask=mask,
)
hidden_states = residual + hidden_states
return hidden_states
#---------------------------------------
class GemmaModel(nn.Module):
def __init__(self):
super().__init__()
self.vocab_size = 10
self.num_hidden_layers = 2
self.rms_norm_eps = 1e-6
self.layers = nn.ModuleList()
for _ in range(self.num_hidden_layers):
self.layers.append(GemmaDecoderLayer(hidden_size=10,
num_heads=3,
num_kv_heads=1,
head_dim=8))
self.norm = RMSNorm(10, eps=self.rms_norm_eps)
def forward(
self,
hidden_states,
freqs_cis,
kv_write_indices,
kv_caches,
mask,
) -> torch.Tensor:
for i in range(len(self.layers)):
layer = self.layers[i]
hidden_states = layer(
hidden_states=hidden_states,
freqs_cis=freqs_cis,
kv_write_indices=kv_write_indices,
kv_cache=kv_caches[i],
mask=mask,
)
hidden_states = self.norm(hidden_states)
return hidden_states
#----------------------------------------
class Tokenizer:
def __init__(self, model_path):
# Reload tokenizer.
assert os.path.isfile(model_path), model_path
self.sp_model = spm.SentencePieceProcessor(model_file=model_path)
# BOS / EOS token IDs.
self.n_words: int = self.sp_model.vocab_size()
self.bos_id: int = self.sp_model.bos_id()
self.eos_id: int = self.sp_model.eos_id()
self.pad_id: int = self.sp_model.pad_id()
assert self.sp_model.vocab_size() == self.sp_model.get_piece_size()
def encode(self, s: str, bos: bool = True, eos: bool = False) -> List[int]:
"""Converts a string into a list of tokens."""
#assert isinstance(s, str)
t = self.sp_model.encode(s)
if bos:
t = [self.bos_id] + t
if eos:
t = t + [self.eos_id]
return t
def decode(self, t: List[int]) -> str:
"""Converts a list of tokens into a string."""
return self.sp_model.decode(t)
#-------------------------------------------
class Embedding(nn.Module):
def __init__(self, num_embeddings: int, embedding_dim: int, quant: bool):
super().__init__()
if quant:
self.weight = nn.Parameter(
torch.rand((num_embeddings, embedding_dim), dtype=torch.int8),
requires_grad=True,
)
self.weight_scaler = nn.Parameter(torch.Tensor(num_embeddings))
else:
self.weight = nn.Parameter(
torch.rand((num_embeddings, embedding_dim)),
requires_grad=True,
)
self.quant = quant
def forward(self, x):
#print('x=', x.shape)
weight = self.weight
if self.quant:
weight = weight * self.weight_scaler.unsqueeze(-1)
#print('w=', weight.shape)
x = x.unsqueeze(0)
#weight =
output = F.embedding(x, weight)
#print('######')
return output
#----------------------------------------
class GemmaForCausalLM(nn.Module):
def __init__( self ):
super().__init__()
vocab_size = 256000 #config.vocab_size
self.embedder = Embedding(vocab_size, 10, quant=False)
self.model = GemmaModel()
def forward(
self,
x,
freqs_cis,
kv_write_indices,
kv_caches,
mask,
):
hidden_states = self.embedder(x)
Z = self.model(hidden_states, freqs_cis, kv_write_indices, kv_caches, mask)
return Z
#--------- 建立模型 --------------------
model = GemmaForCausalLM()
criterion = nn.MSELoss()
#optimizer = torch.optim.SGD(model.parameters(), lr=0.15)
optimizer = torch.optim.Adam(model.parameters(), lr=0.004)
# 設定Target
T = torch.FloatTensor( [[0,0,0,0,0, 1,0,0,0,0],
[0,0,0,0,0, 0,1,0,0,0],
[0,0,0,0,0, 0,0,1,0,0],
[0,0,0,0,0, 0,0,0,1,0]] )
T = T.unsqueeze(0)
# Input資料
X = ['北 中 南']
print('\nX=', X)
tk_path = os.path.join("tokenizer/tokenizer.model")
xtokenizer = Tokenizer(tk_path)
prompt_tokens = [xtokenizer.encode(prompt) for prompt in X]
X = torch.LongTensor(prompt_tokens[0])
batch_size = 1
seq_len = 4
num_kv_heads = 1
head_dim = 8
kc_cache = torch.randn(batch_size, seq_len, num_kv_heads, head_dim)
vc_cache = torch.randn(batch_size, seq_len, num_kv_heads, head_dim)
kv_cache = (kc_cache, vc_cache)
kv_caches = (kv_cache, kv_cache)
mask = torch.tensor([1, 1, 1, 1], dtype=torch.float32)
freqs_cis = torch.tensor([[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]
], dtype=torch.float32)
kv_write_indices = torch.LongTensor([0, 1, 2, 3])
#----------- 訓練500回合 -----------------
print('\n展開訓練...')
for epoch in range(500+1):
# 正向傳播
Z = model(X, freqs_cis, kv_write_indices, kv_caches, mask)
# 計算損失
loss = criterion(Z, T)
# 反向傳播和優化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每1個迴圈印出損失
if(epoch%100 == 0):
print('ep=', epoch, 'loss=', loss.item())
#------------------------------
Z = model(X, freqs_cis, kv_write_indices, kv_caches, mask)
print('\n----- Z -----')
print(np.round(Z.detach().numpy()))
#------------------
#END
然後就執行這個程式,此時會展開500回合的訓練,並輸出,如下:
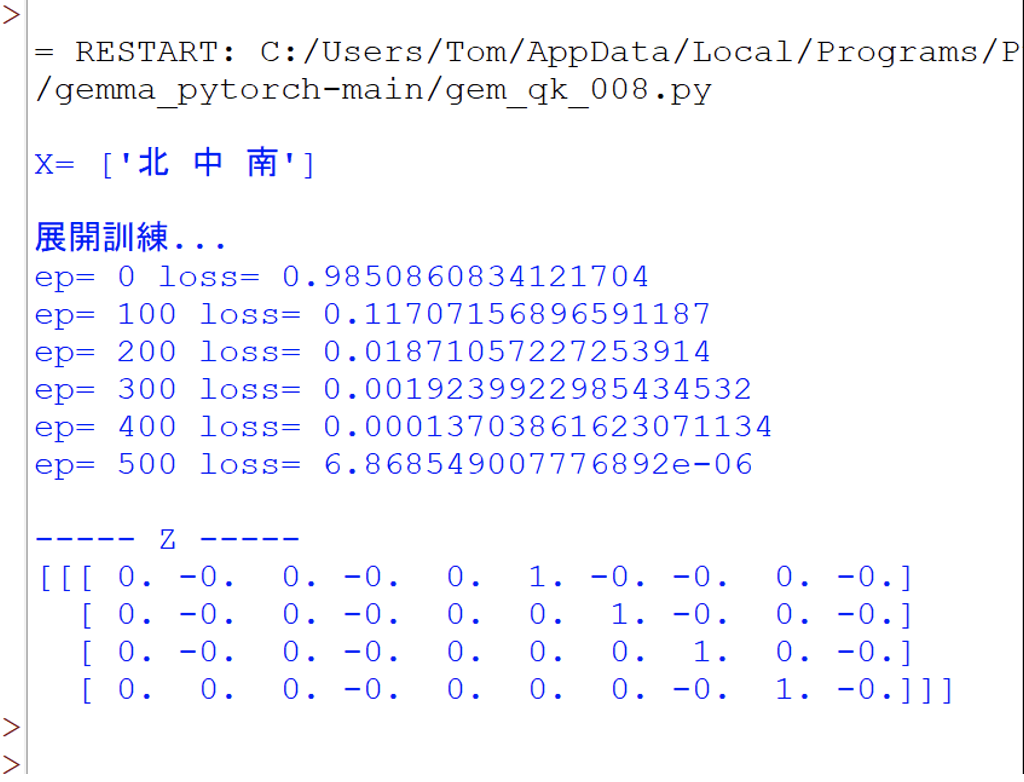
(責任編輯:謝嘉洵。)

近5年來,從事於AI普及化教育工作,目前擔任銘傳大學AI課程、長庚智慧醫療研究所AI課程授課老師。也擔任永春國小、東園國小、立志中學、君毅中學、永春高中等學校的AI師資培育工作。
- LoRA微調三步驟:以大語言模型MT5為例 - 2024/05/02
- 為什麼Gemma採取Decoder-Only Transformer架構呢? - 2024/04/08
- 如何從0訓練企業自用Gemma模型 - 2024/04/03
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!



2025/03/14
讚讚