作者:許哲豪

GTC 2024 Keynote (Youtube)。[1]
這兩天相信很多人都被老黃GTC 2024演講[1]給震撼到了吧!如果你是剛買了H100的朋友,大概心中不免XXX,眼眶中充滿淚水暗罵老黃「你又跟我說B100更快更便宜了??我的錢錢又被搶了啊」。收拾起心情,想想那些買不到的人,自己還算幸運,還有生意可做啊!
兩個小時的影片中,其中透露出一個加速祕密,新一代 GPU Blackwell B200 在硬體端提供了 FP4 計算能力,單片就可達 20 petaFLOPS(每秒2×10^16=20兆次浮點數計算),二片 B200 組成的 GB200 在訓練性能是前一代 H100 的 4 倍,推論性能更高達 7 倍。若再將 36個 CPU 加上 72 個 GPU 組成「GB200 NVL72」超大型伺服器,則 FP8 訓練能力可高達 720 petaFLOPS, FP4 推論能力更高達1.44 exaFLOPS(1,440 petaFLOPS)。這樣總體訓練及推論運算速度較前一代分別快了22倍及45倍。而究竟什麼是 FP8 / FP4 呢? 接下來就簡單幫大家科普一下。
8位元浮點數(FP8)
一般 AI 模型有很多參數要被訓練,通常每個參數要使用32位元浮點數 (FP32) 來表示,相當於要使用 4 個位元組(Byte),若以 GPT-3 的1750億(175B)個參數來看,就等於要使用 700 (4×175=700) GByte ,這對訓練時的記憶體需要極高。所以為了讓數值動態範圍(可表達最大到最小數字範圍)夠大,且儲存空間變小,同時加快計算速度,於是有了8位元浮點數 (FP8) 格式出現,而這項技術也第一次被 H100 加入硬體設計中。
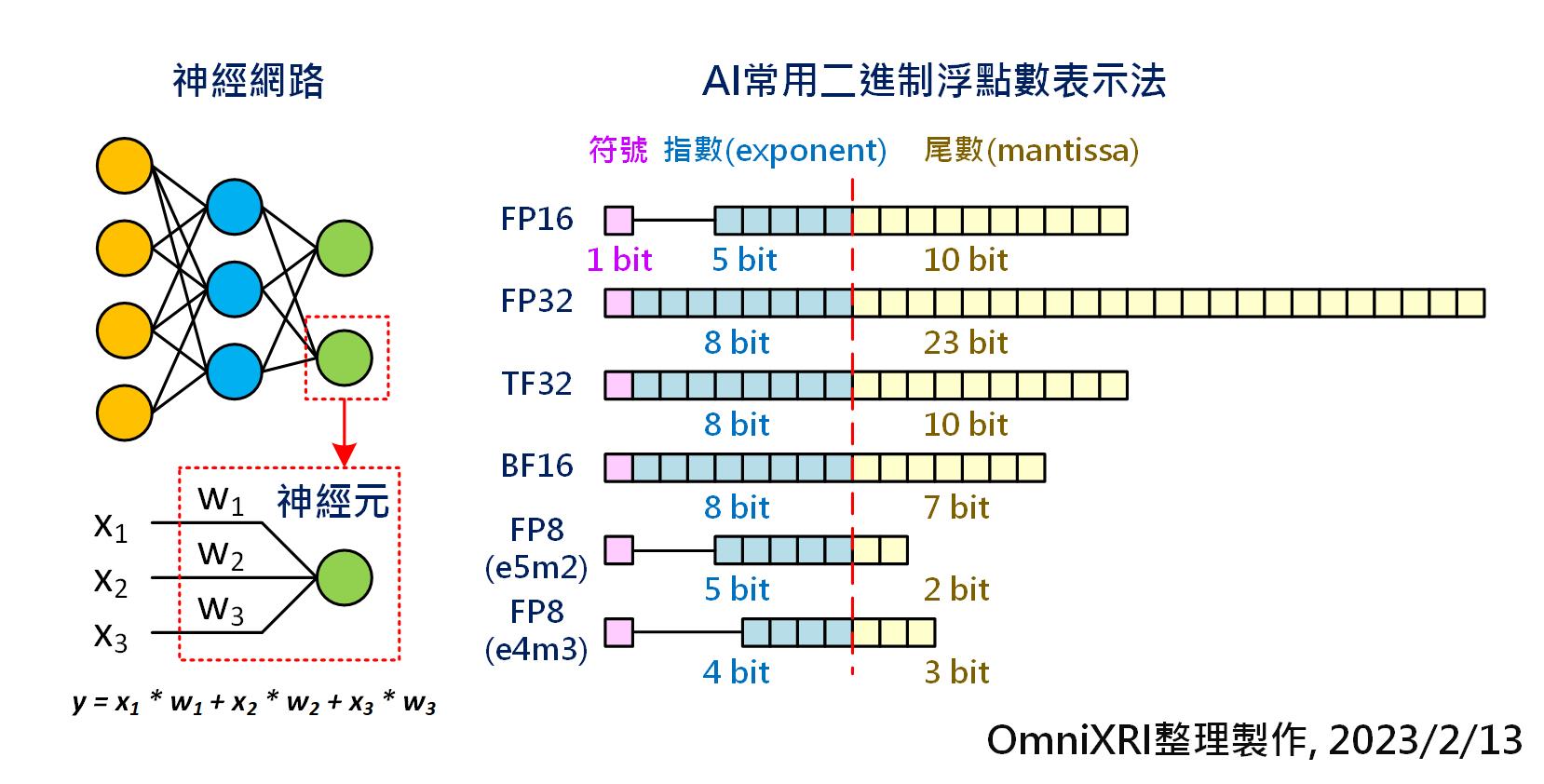
AI常用二進制浮點數表示法。(OmniXRI整理製作, 2023/02/13)[2]
從 Fig.2 可看出為了表示浮點數,通常會有符號(表正負值)、指數及尾數三個部份,依需求的動態範圍可配置不同的位數,而 FP8 就是使用8位元來表示浮點數。由於 FP8 位數較少,所以可彈性調整指數和尾數的位元數,用以表現不同的動態範圍及表現精度,如e4m3, e5m2等。
為了讓大家更理解同樣是有號數8位元,不同表達方式的動態範圍及最小表示精數,可參考 Fig.3 所示。整數(INT8,亦可看成e0m7)只能表示 ±127,而 FP8 e4m3 動態範圍 ±448, 最小表示精度為 2^-9, e5m2 動態範圍則可擴大到 ±57,334 ,最小表示精度可達 2^-16。不過這裡的 FP8 小數點解析度並不像整數空間是線性等距的,因此使用上會產生一些偏差值,要特別注意。
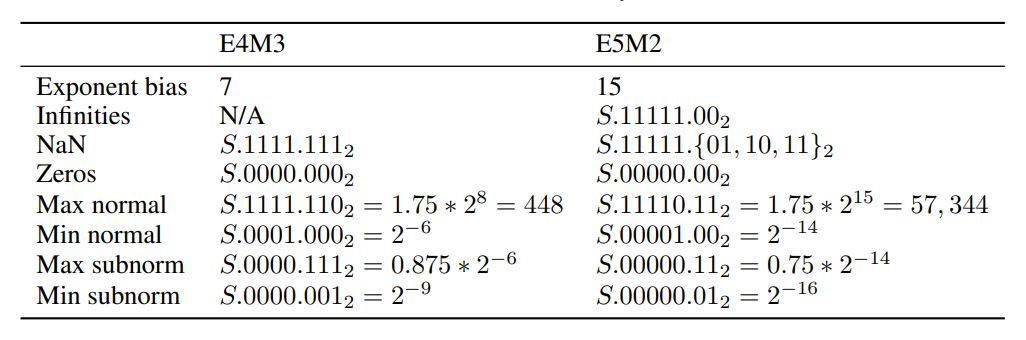
FP8 e4m3 及 e5m2 數值表示範圍。[3]
4位元浮點數(FP4)
為了讓大型語言模型在訓練及推論時能更節省數據空間,自然就想到把參數從8位元再減半變成4位元,其中除了使用無號數整數(UINT4)外,浮點數(FP4)也是重點,而此次NVIDIA就是 FP4 計算硬體化,首次放入新晶片 B200 中。
由於 FP4 位數實在過少,所以在 IEEE 754 標準中,直接定義為1位符號、2位指數及1位尾數,即FP4 e2m1。從Fig. 4可看出,若以UINT4表示,則數字間距為等距,距離為1,表示範圍從0到15。對應到 FP4(e2m1) 時則非等距,表示範圍在 ±3,最小表示精度為 0.5,其中還要扣除 Inf (正負無限大)和 NaN(非數字)。後來有學者提出新論文[4]想改善動態範圍,放棄 Inf, NaN,讓動態範圍擴大到 ±6。未來到底是 UINT4(或INT4) 還是 FP4 會更受重視,就有待時間來考驗了。

無號4位元整數(UINT4)和有號4位元浮點數(FP4)數值表示範圍。[4]
小結
從以往的 TF32 取代 FP32 到 BF16 改善 FP16,新的數字系統都是為了加速 AI 訓練和推論用。從 Nvidia 此次提出的實測數據,可以感受到在大型語言模型及生成式應用採用新的 FP4 確實有很大的助益,尤其在硬體化後。未來是否會將此類技術移轉到家用顯卡上或其它廠商(如INTEL, AMD)也投入跟進,就讓我們再耐心等等吧!
參考文獻
[1] Nvidia, GTC March 2024 Keynote with NVIDIA CEO Jensen Huang (Youtube)
https://youtu.be/Y2F8yisiS6E?t=2728
[2] 許哲豪,【vMaker EDGE AI專欄 #02】 要玩AI前,先來認識數字系統
https://omnixri.blogspot.com/2023/02/vmaker-edge-ai-02-ai.html
[3] Paulius Micikevicius et al., FP8 FORMATS FOR DEEP LEARNING
https://arxiv.org/abs/2209.05433.pdf
[4] Yijia Zhang et al., Integer or Floating Point? New Outlooks for
Low-Bit Quantization on Large Language Models
https://arxiv.org/abs/2305.12356.pdf
(本篇文章經同意轉載自歐尼克斯實境互動工作室(OmniXRI),原文連結;責任編輯:謝嘉洵。)

主持歐尼克斯實境互動工作室(OmniXRI):http://omnixri.blogspot.com
Edge AI Taiwan邊緣智能交流區:https://www.facebook.com/groups/edgeaitw/
- Arduino UNO Q教學案例整理 - 2026/03/09
- 有了Intel AI Playground 不寫程式也能輕鬆玩生成式AI - 2025/09/02
- 【開發資源】TinyML MCU 等級開源推論引擎 - 2025/06/09
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


