作者:高煥堂
上一期所刊登的《從CLIP應用領會隱空間的魅力》一文裡,就是一個典型的範例:從Github網頁下載OpenAI公司的CLIP原始程式碼(Source code),然後搭配自己收集的小資料來訓練一個給超市商家使用的小模型(圖-1)。
圖-1、Github上的免費CLIP源碼
那麼,這大模型與小模型,兩者的程式碼之間,有何不同呢? 這可能會出乎您的預料,其核心模型的程式碼,大多是一致的、相容的。常常僅是大模型的參數量很大,而小模型參數量較少而已。
於是就能免費拿來大模型的開放原始程式碼,把其參數量調小,搭配企業自有IP的資料(訓練資料量較少),在較省算力的電腦上即可把程式碼跑起來,訓練出企業自有IP的中小模型了。免費程式碼既省成本、可靠、省算力、又自有IP,可謂取之不盡、用之不竭的資源,豈不美哉!
例如,在上一期的文章裡,就以商店櫃檯的產品推薦應用為例演示了:拿CLIP的原始程式碼,搭配商家自有產品圖像(Image)和圖像敘述文句(Text),來訓練出企業自用的CLIP小模型。
然而,上一期文章裡,並沒有詳細說明其訓練的流程。於是,本文就拿另一個範例來演示,並且說明其開發流程。由於本文的主題是程式碼,如果您有些Python程式碼的基礎知識,就會更容易理解。
以<訓練Diffusion寫書法>為例
筆者之前的文章《細觀Diffusion隱空間裡UNet的訓練流程》裡,曾經介紹過Diffusion架構,及其訓練方法。在AIGC潮流中,SD(Stable Diffusion)產品的推出是AIGC圖像生成發展歷程中的一個里程碑,提供了高性能模型,能快速生成創意十足的圖像。
於是,本範例就拿Diffusion來學習,及創作書法字體,也就是俗稱的:寫書法。雖然Diffusion也能學習依循標準筆順,來逐筆寫出字形。為了從簡單範例出發,本文先讓Diffusion來學習生成整個字形,而不是逐一生成各筆劃。
在SD裡,UNet模型扮演關鍵性角色。在SD的隱空間裡,它使用了一個UNet模型,並搭配一個時間調度(Scheduling)器,來擔任圖像生成的核心任務。而擴散(Diffusion)一詞則描述了SD隱空間裡進行的圖像生成情形,整個過程都是在隱空間裡逐步推進(Step by step)的,現在就依循開發流程來逐步說明之。
Step-1:從Github網頁下載Diffusers源碼
首先訪問這個Huggingface網頁(圖-2):
圖-2、Github上的免費Diffusers源碼
然後,按下<code>就自動把Diffusers源碼下載到本機裡了。這源碼本身並不大,只有4.5M大小而已。
Step-2:把Code放置於Python 的IDLE環境裡
把剛才下載的Diffusers程式碼壓縮檔解開,放置於Wibdows本機的Python工作區裡,例如 /Python310/目錄區裡(圖-3):
圖-3、放置於本機的Python環境裡
這樣,就能先在本機裡做簡單的測試,例如創建模型並拿簡單資料(或假資料)來測試,有助於提升成功的自信心。
Step-3:找出Diffusion的核心模型—UNet
由於小模型常常只需要部份程式碼就足夠了,所以就打開上圖裡的/diffusers/ 文件夾,就會看到所需要的UNet模型程式碼檔— unet_2d_condition.py檔案,如下(圖-4)所示。
圖-4、放置於本機的Python環境裡
接著,打開這個unet_2d_condition.py檔案,可以看到內含的類(Class)定義:
class UNet2DConditionModel(…):
……………
……………
這個UNet2DCondition類就是所需要的UNet模型的定義了。
Step-4:準備訓練數據(Training data)
在本文的範例裡,收集了「春、滿、乾、坤」四個字的書法圖像,各5個圖像,如下(圖-5)所示。
圖-5、訓練數據
總共有20個書法字體的圖像。使用這20張書法圖像,來讓UNet模型學習,就能讓它「畫」出書法字了。之後,也能進一步讓它學習沒一個字的筆順,來逐筆地<寫>出書法字體了。
Step-5:編寫<模型訓練>主程序,然後展開訓練
準備好了訓練資料(書法圖像),就來編寫一個主程序,使用UNet2DCondition類來創建一個UNet模型。主程序的程式碼如下:

接著,就拿剛才所準備的訓練圖像,來展開訓練,也就是讓UNet模型來學習了。其程式碼如下:
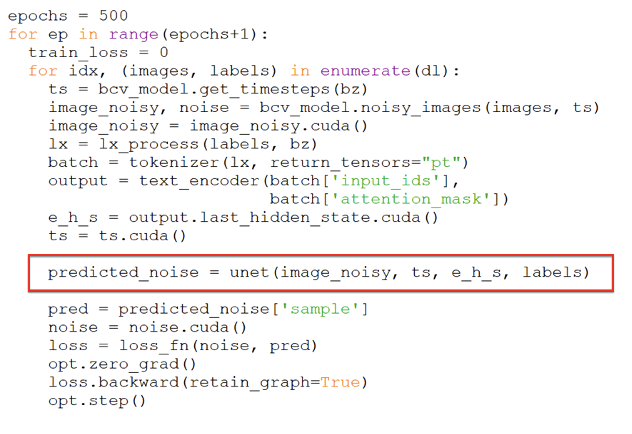
在SD隱空間裡,它使用了一個UNet模型,並搭配一個時間調度(Scheduling)器,來擔任圖像生成的核心任務。執行到上圖紅色框的指令時,就會把隨機噪音添加到書法圖像裡,成為<含噪音圖像>(Image noisy)。然後把它輸入給UNet模型,讓它預測出此圖像所含的噪音。在SD裡,使用數學運算,根據時間步數(即上圖裡的ts)來決定將多少噪音量添加到原圖像裡。這樣地重複訓練500回合。如果圖像數量增大時,在單機上訓練,可能速度非常緩慢。此時可以把這些程式碼遷移到有GPU的機器上進行訓練,能大幅提高效率。
Step-6:編寫<圖像生成>主程序,然後展開創作
訓練好了,就得到了自用小模型了。最後就可編寫另一個主程序,來讓UNet模型生成各種創意的書法作品了。例如,把字寫在唐宋時期的國畫裡,如下(圖-6)所示。

圖-6、AI的書法創作
每次執行這個書法主程序,都會有一些不一樣的創新,例如圖-6的左右兩項書法創作。
結語
基於本文的範例,可以繼續微調、優化這UNet模型及主程序程式碼,讓AI做出更多的創新作品。例如,也能進一步讓它學習沒一個字的筆順,來逐筆地「寫」出書法字體了(圖-7)。

圖-7、AI依筆順而逐筆創作
本文以AI<畫>書法為例,說明如何從Github園地裡,挖掘自己想要的大模型原始程式碼,搭配自己收集的書法圖像,來訓練出有趣的AI書法小模型。如果能善用這些免費程式碼,既能省成本、又可靠、省算力、甚至能擁有自己有IP,可謂取之不盡、用之不竭的資源,不亦美哉!

近5年來,從事於AI普及化教育工作,目前擔任銘傳大學AI課程、長庚智慧醫療研究所AI課程授課老師。也擔任永春國小、東園國小、立志中學、君毅中學、永春高中等學校的AI師資培育工作。
- LoRA微調三步驟:以大語言模型MT5為例 - 2024/05/02
- 為什麼Gemma採取Decoder-Only Transformer架構呢? - 2024/04/08
- 如何從0訓練企業自用Gemma模型 - 2024/04/03
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


