作者:Judith Cheng
AI正從雲端走入凡間,在更接近終端使用者、位居網路邊緣的各種裝置中,扮演實現智慧功能的關鍵角色,催生了五花八門的創新應用;在這個被稱為「邊緣AI」(Edge AI)的新興市場領域,除了擁有龐大商機潛力吸引眾家軟硬體業者積極搶進,也成為吸引電子系統開發者揮灑創意的舞台,其未來發展充滿無限可能。
看好Edge AI應用的成長趨勢,原本就是嵌入式系統/物聯網(IoT)裝置核心元件的各廠牌微控制器(MCU)/微處理器(MPU),也紛紛開始強調自家方案在邊緣執行AI推論任務的運算能力以及容易上手的開發工具;有別於CPU、GPU以較高運算力為強項,MCU/MPU固有的靈活性、低功耗、安全性等優勢,在這波Edge AI應用浪潮中成為矚目焦點。為此我們透過與供應商的訪談以及資料收集,以期讓讀者們更了解市面上現有MCU產品與工具平台的特色,做為開發Edge AI應用時的選擇指南。
結合CNN加速器、專為Edge AI應用打造的MCU
鎖定Edge AI應用的低功耗需求,亞德諾半導體(ADI)以結合了卷積神經網路(CNN)加速引擎的MAX78000系列MCU作為主打解決方案(編按:這是ADI完成收購Maxim Integrated取得的產品線)。根據ADI工程師黃一凡的介紹,MAX78000內建配備浮點運算單元(FPU)的Arm Cortex-M4核心支援高效率系統控制,搭配一顆支援智慧DMA的RISC-V核心以執行應用程式與控制碼、同時用以驅動CNN加速器,其晶片架構如下圖1。
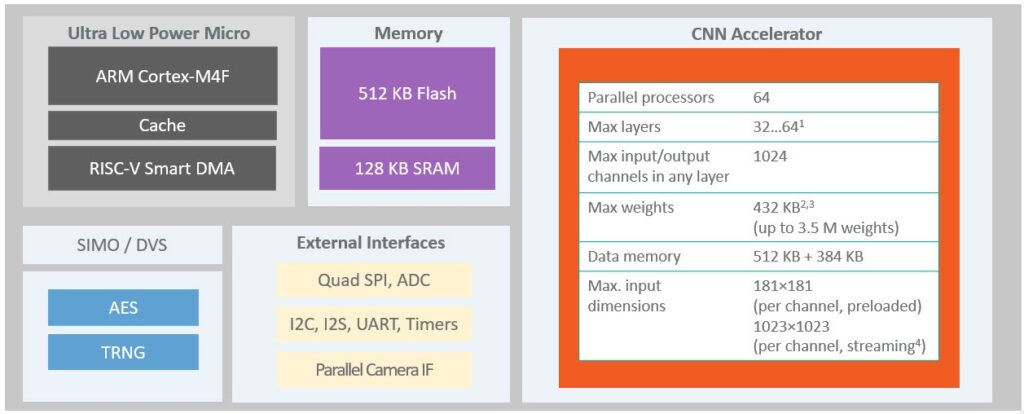
圖1:MAX78000晶片架構。(來源:ADI)
MAX78000的CNN加速引擎配備442KB權重記憶體,可以支援 1、2、4和8位元權重;CNN的權重記憶體是以SRAM為基礎,可以即時進行AI網路更新。除了CNN加速器的內建記憶體,MAX78000還配備512KB快閃記憶體和128KB SRAM,支援多個高速和低功耗通訊介面,包括I²S和並聯攝影機介面(PCIF)。
因應不同Edge AI應用開發需求,MAX78000可提供各種配置選項(參考該元件規格表)──包括不同振盪器、時脈源以及運作模式──以實現功耗最佳化。在ADI分享的官方文件中,有利用PyTorch機器學習框架構建、以MAX78000開發工具套件部署的關鍵字識別(KWS20)與臉部辨識(FaceID)應用實例提供開發者參考。

圖2:MAX78000開發工具套件。(來源:ADI)
專為MAX78000打造的開發工具套件(EV Kit)配備數位麥克風、串列連接埠以及對攝影機模組的支援,配備3.5吋彩色TFT觸控顯示器,以及電流/電壓監測電路(參考圖2)。MAX78000的模型可使用PyTorch或TensorFlow-Keras工具鏈開發,以浮點權重和訓練資料進行訓練。權重可以在訓練期間量化(量化感知訓練)或在訓練後量化;MAX78000的開發流程如圖3所示。
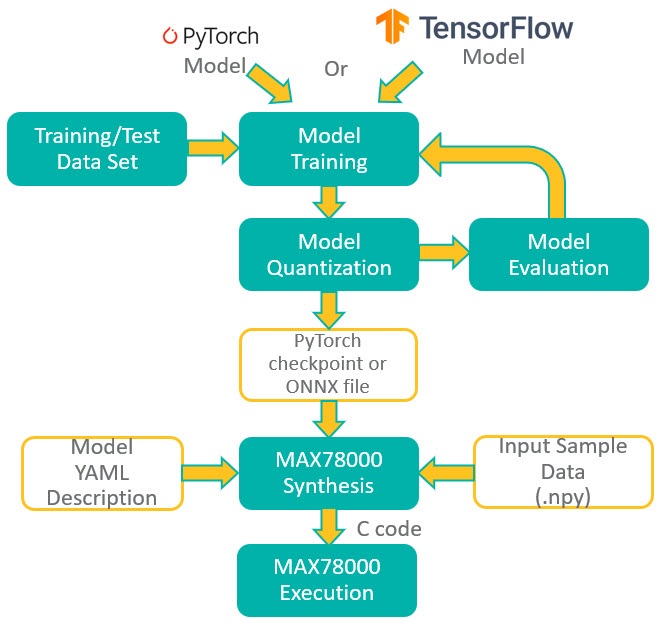
圖3:MAX78000開發流程圖。(來源:ADI)
針對需要更高算力的應用,ADI還有新一代的MAX78002,其CNN加速引擎配備2M 8-Bit內建記憶體,可支援 1、2、4和8-Bit(網路支援多達 1600 萬Bit)權重。此外微控制器內建的系統記憶體則有2.5MB快閃記憶體和384KB SRAM。支援多種高速低功耗通訊介面,包括I²S、MIPI CSI-2、PCIF和SD3.0/SDIO3.0/eMMC4.51安全數位介面。

MAX78000在執行Edge AI任務時比競爭方案速度更快、功耗更低。(來源:ADI)
累積豐富車用經驗、以視覺處理為強項的MPU系列
看好成長潛力十足的Edge AI市場,晶片產品陣容堅強的老牌半導體大廠德州儀器(TI)針對從2TOPS、8TOPS到32TOPS不同算力需求的低至高階應用,分別以鎖定工業應用的AM62A (2TOPS)、AM68A (8TOPS)、AM69A (32TOPS) 的Sitara系列MPU,以汽車相關應用為目標的Jacinto TDA4 (8TOPS)系列SoC為主打解決方案。
憑藉在車用市場先進駕駛輔助系統(ADAS)應用累積的豐富經驗,TI特別強調自家解決方案的性能/功耗表現與免費線上開發工具的易用性等優勢。此外根據該公司應用工程經理陳寬裕以及資深應用工程師詹源銘的介紹,TI的Edge AI應用解決方案目前可提供6種經過預訓練的模型(參考圖4),也將持續增加種類,預計在近期增加對YoloV8模型的支援;能為開發者節省大量時間與開發成本。
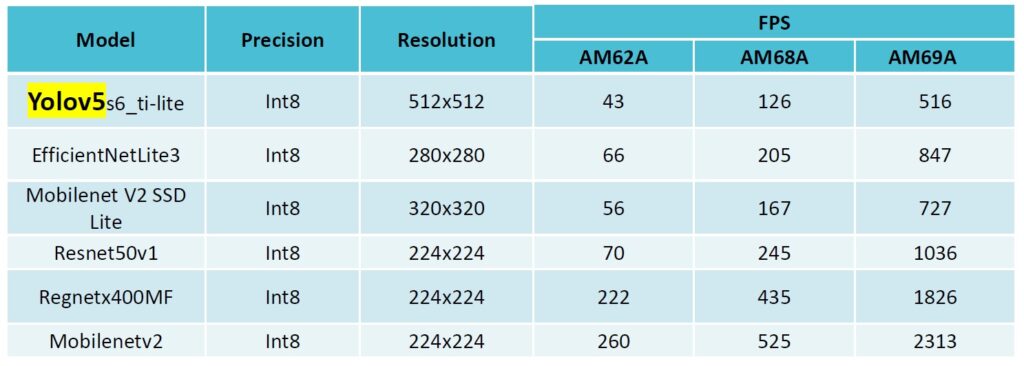
圖4:TI微處理器目前支援6種預訓練模型。(來源:TI;圖中所示精度僅供參考,持續更新中,最新資訊請參考TI線上開發工具平台)
AM62A、AM68A、AM69A三款MPU是TI在2023年3月才剛發表的最新產品,採用Arm Cortex-A53 (AM62A) 或 Cortex-A72 (AM68A/AM69A)中央處理單元、第三代 TI繪圖處理器(GPU)、內部記憶體、介面和硬體加速器(Cx7);其詳細晶片架構請參考圖5。
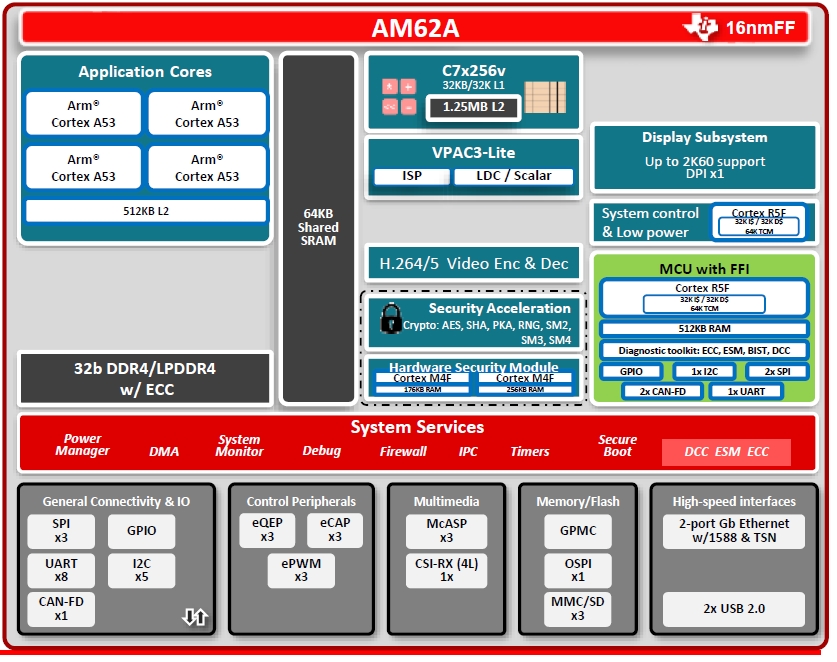
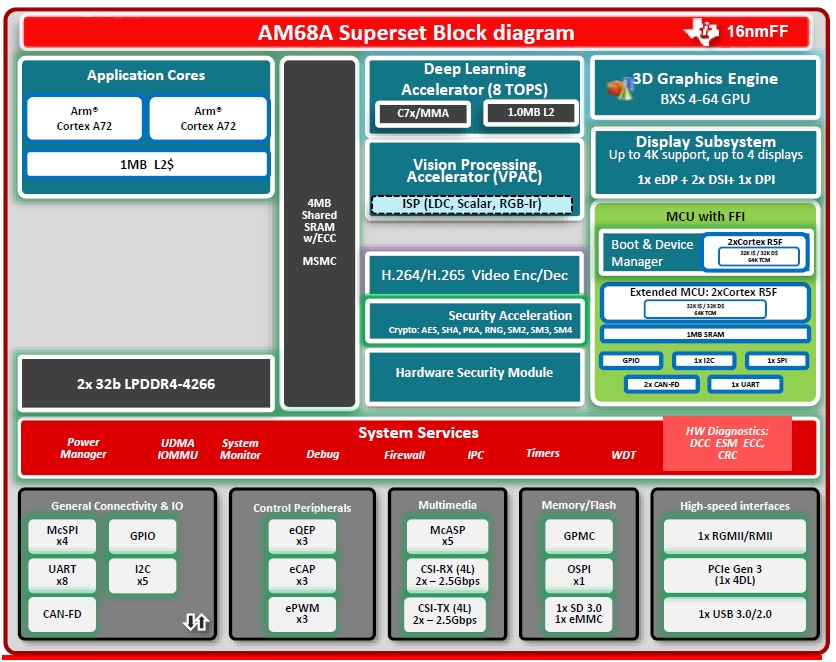
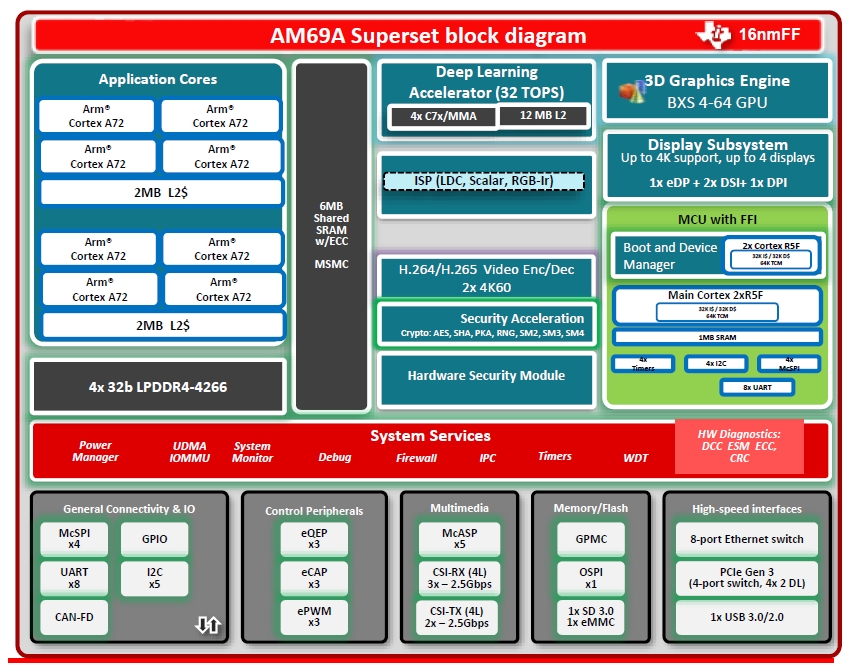
圖5:AM62A、AM68A、AM69A晶片架構圖。(來源:TI)
其中AM62A能在智慧門鈴、智慧零售等系統以低於2W的功率支援最多2支攝影機,支援低成本視覺應用;AM68A適合保全攝影機、工廠自動化等進階視訊分析應用,能支援最多8支攝影機;AM69A則能在自主行動機器人、交通監控系統等要求高性能與即時性的應用中,支援最多12支攝影機。
採用TI Jacinto 7架構的TDA4系列微處理器以高運算能力與高整合度特性,以自動駕駛、ADAS等汽車相關應用為目標,也適合例如機器人、機器視覺、雷達等工業應用,僅需4G DDR就能支援包含8支攝影機的配置。
TDA4VM關鍵內建核心包括C7x浮點運算向量DSP、深度學習MMA、具有ISP和多重視覺輔助加速器的視覺處理加速器(VPAC)、深度和動作處理加速器(DMPAC)、雙核心64位元Arm Cortex-A72子系統、6個Arm Cortex-R5F MCU,以及兩個 C66x 浮點 DSP,以及3D GPU PowerVR Rogue 8XE GE8430等,電路配置參考圖6。
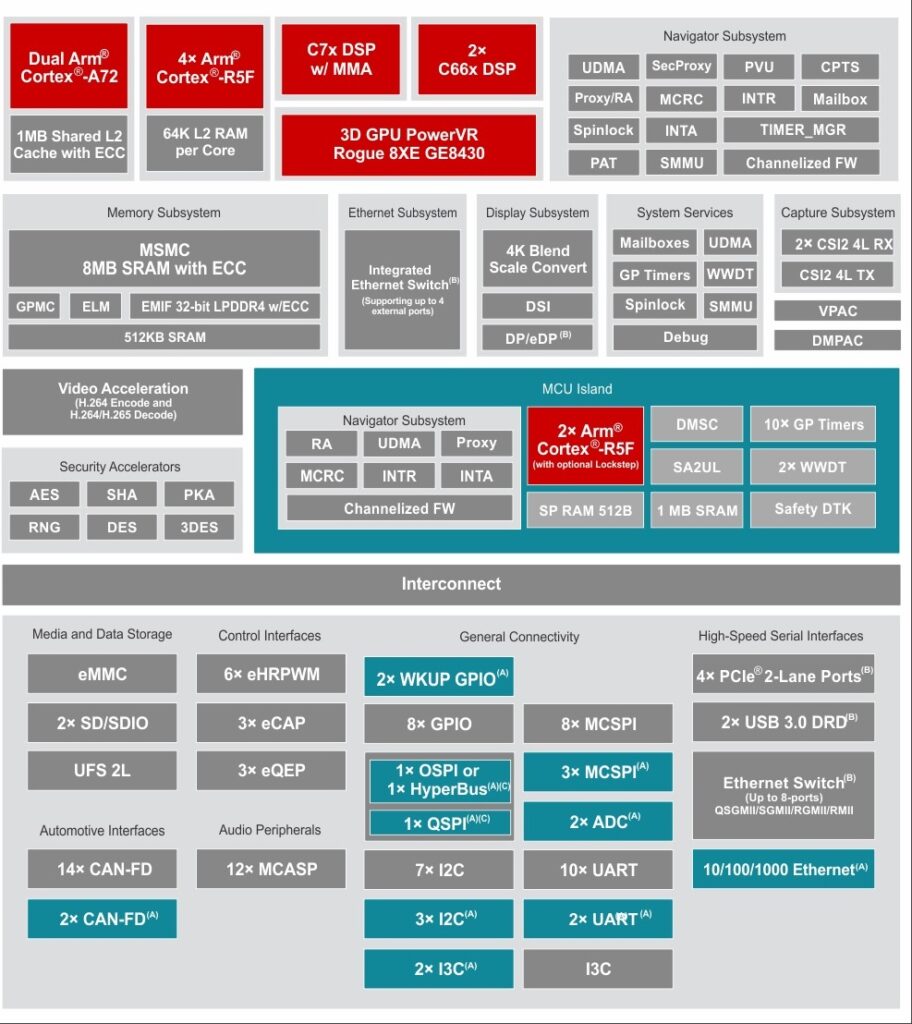
圖6:TDA4VM晶片架構圖。(來源:TI)
無論是AM62A、AM68A、AM69A或TDA4,都有配套的開發工具套件提供設計評估;同時TI擁有資源豐富的線上開發環境(TI Developer Zone)與工具資源,針對Edge AI應用也提供模型編譯器(Model composer)與分析器(Model Analyzer)免費下載。
結合AI/ML與豐富無線連結選項的32位元低功耗MCU
可提供包括各種無線連結技術、低功耗MCU等解決方案,支援智慧家庭、工業物聯網以及智慧城市相關應用的Silicon Labs在Edge AI領域亦有所著墨,該公司所有EFR32系列無線SoC (32位元MCU)都支援機器學習功能,包括配備內建AI/ML硬體加速器的最新EFR32BG24與EFR32MG24產品;這兩款元件都採用ARM Cortex-M33核心,內建2.4 GHz RF、Secure Vault安全功能,以及節能低功耗設計架構,電路配置參考圖7。
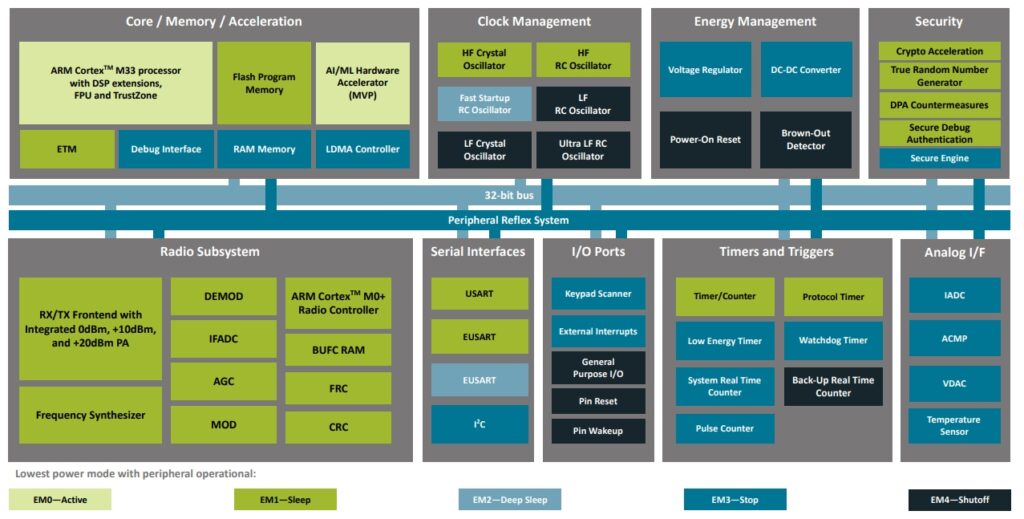
圖7:EFR32BG24/EFR32MG24晶片架構圖。(來源:Silicon Labs)
Silicon Labs表示,EFR32BG24適用以藍牙低功耗和藍牙網狀網路(Bluetooth mesh)連結的IoT裝置,EFR32MG24則支援透過Matter、OpenThread和Zigbee協議進行網狀網路無線連結的IoT應用,兩者都是可穿戴裝置、醫療保健、智慧家庭、智慧照明、大樓自動化,甚至工業應用的理想選擇。藉由加入對AI/ML技術的支援,Silicon Labs的MCU不只是執行簡單的通訊數據機任務,而能支援像是設備異常檢測、語音識別、視覺應用等應用,成為智慧IoT/Edge AI裝置中的一體化解決方案,助力開發者降低成本、簡化設計。
此外Silicon Labs也指出,AI/ML功能也讓MCU能扮演「系統守護者」角色,在主系統CPU休眠時保持開啟,並在檢測到正確關鍵字(或在視覺應用中有人經過)時喚醒系統,如此能實現更長的電池壽命以及更高的任務執行效率。而該公司也表示,將持續提供效率更高、更具智慧性的軟硬體設計解決方案,來滿足Edge AI這個新興應用領域的需求。
在開發支援方面,Silicon Labs表示其MCU產品提供對TensorFlow Lite Micro (for Microcontrollers)的原生支援,並在GitHub上提供開源工具套件Machine Learning Tool Kit (MLTK),包含端對端範例、示範與教學,以及有助加速ML開發流程的Python套件。
此外Silicon Labs也與嵌入式AI/ML開發工具鏈供應商如SensiML和 Edge Impulse等合作,透過所謂的AutoML工具,協助開發人員利用針對嵌入式系統最佳化的模型來簡化開發過程;包括與Edge Impulse合作的xG24 開發套件,以及SensiML的AutoML嵌入式程式碼生成軟體。以上的AI/ML 工具鏈也能與Silicon Labs的Simplicity Studio無縫結合,讓使用EFR32BG24與EFR32MG24的開發者輕鬆部署支援ML的無線應用軟體。
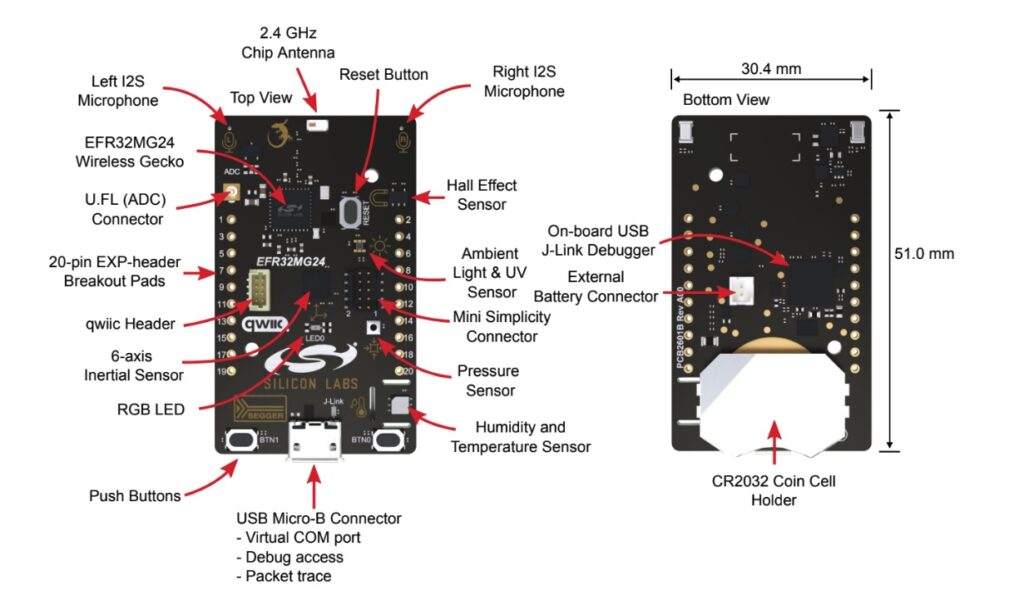
圖7:Silicon Labs與Edge Impulse合作推出的xG24開發工具套件。(來源:Edge Impulse)
對於沒有AI/ML開發經驗/經驗較少、或者尋找立即可用解決方案的使用者,Silicon Labs則能提供生態系合作夥伴的資源,包括語音識別/喚醒詞技術領導業者Sensory,以及無程式碼異常檢測平台供應商Micro.ai等。
內建神經網路處理單元的低功耗MCU
以支援圖像辨識、關鍵字識別、馬達控制、異常檢測等Edge AI應用為目標,恩智浦半導體(NXP)最新推出的解決方案為MCX-N微控制器(MCU)系列;根據該公司大中華區市場總監黃健洲介紹,MCX-N是首款結合NXP硬體神經處理加速器──NXP eIQ Neutron NPU──的MCU系列。
與單獨使用CPU核心相比,該元件的ML輸送量提高了30倍;而透過與MCU整合的NPU,使用者可以開發具有更高輸送量和更高效的AI和ML工作負載的應用程式,而不會增加Cortex-M核心MCU的主要應用處理負擔。該系列MCU的工作電流消耗小於45μA/MHz,若啟動即時時脈(RTC)和保持8KB SRAM,在低功耗模式下消耗的電流不到2.5μA。
MCX-N系列率先問世的是N94x和N54x,內建雙Arm Cortex-M33核心、EdgeLock安全子系統; N94x支援更廣泛的類比與馬達控制周邊、適合工業應用,N54x系列則以支援消費性和IoT應用的周邊為主,包括配備PHY的高速USB介面、SD和智慧卡介面等。MCX-N系列微控制器的晶片架構參考圖9。
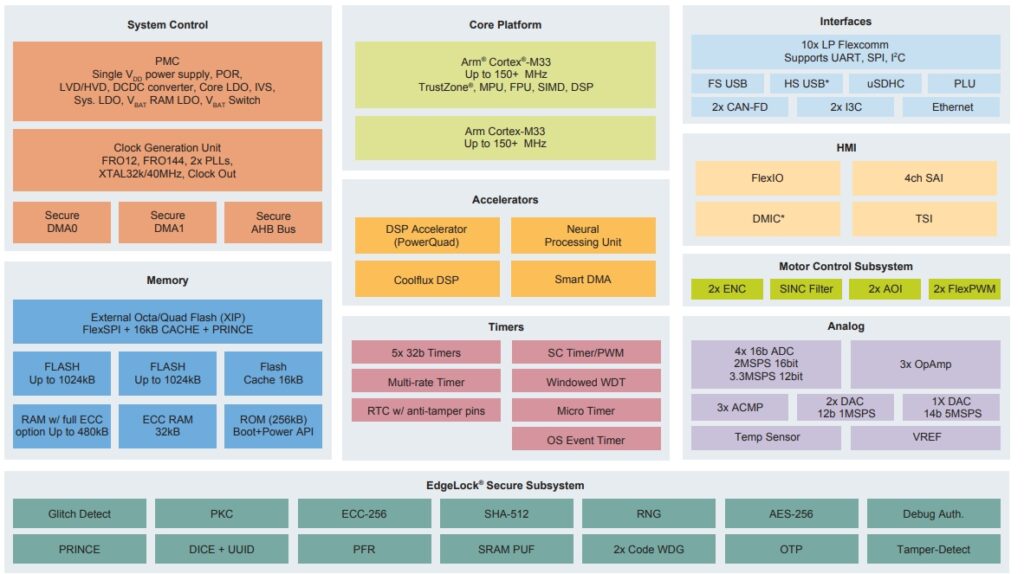
圖9:MCX-N系列MCU晶片架構圖。(來源:NXP)
在開發工具的支援方面,NXP的eIQ機器學習軟體開發環境(ML Software Development Environment),能結合該公司高性能i.MX RT跨界處理器、MCX-N系列MCU與eIQ Neutron NPU核心相結合,助力使用者簡化開發智慧解決方案的流程。
結合開放源碼與NXP專有技術的eIQ ML軟體開發環境包括eIQ Toolkit、推論引擎(目前支援包括DeepViewRT、TensorFlow Lite Micro、TensorFlow Lite、CMSIS-NN、Glow)、神經網路編譯器,最佳化模型庫等,能與該公司的MCUXpresso軟體工具套件以及Yocto開發環境整合,其開發流程參考圖10。
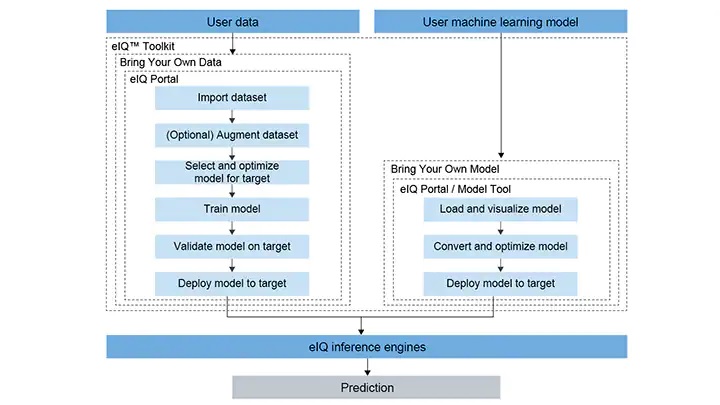
圖10:eIQ機器學習軟體開發流程。(來源:NXP)
小結
市場上的MCU/MPU產品琳瑯滿目,除了以上四家跨國供應商,還有許多支援Edge AI應用的同類型解決方案有待我們陸續為讀者介紹並探索其中奧妙;也歡迎有相關開發經驗的朋友們與我們分享箇中使用心得!

- RISC-V躍居AI推論時代運算主流 台灣供應鏈迎接「開放」新契機 - 2026/06/18
- 量子運算加速邁進可用階段 英飛凌分享技術布局策略 - 2026/06/17
- 【COMPUTEX 2026】Edge AI走向現實生活 Alif展示多元低功耗應用 - 2026/06/11
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


